
課金は複雑なシステムであり、最も重要なコンポーネントの1つはデータベースです。 さまざまなテーブルが含まれており、時間が経つにつれて大きくなります。
この成長によりデータベースの動作が遅くならないようにするために、Oracle、PostgreSQL、およびその他のDBMSには効果的なパーティションメカニズムがありますが、常に使用できるとは限りません。 たとえば、比較的低予算のバージョンのOracle Standard Editionシステムでは使用できません。
これまで、 Hydraテレコムオペレーターへの請求では、独自のパーティションメカニズムを実装していませんでした。テーブルの成長を追跡し、システムパフォーマンスの問題を最小限に抑える手順を説明したカスタマーガイドの作成に限定しました。 後で判明したように、これは明らかに十分ではありませんでした。
背景
Hydraの請求は通信事業者によって使用されます。つまり、データベース内の最も重要で最大のテーブルの1つは、インターネットまたは電話プロバイダーの加入者のPPPセッションおよびCDRにデータを格納する役割を果たします。 このテーブルには、最後の更新の開始、終了、および時間に関する情報と、接続を開始したIPアドレスなど、それを開始したサブスクライバに関する情報が格納されます。
通信事業者のデータベースに加入者が多いほど、セッションデータを含むテーブルの成長が速くなります。 この状況で最も簡単な解決策は、古いレコードを時々削除することです。 ただし、ロシアの法律では、プロバイダーは、法執行機関が必要とするネットワークへの加入者のアクセスに関するデータを3年間保存する必要があります。
何年も前に請求書を作成する際、この瞬間を考慮して、セッションを含むテーブルのボリュームが1500万行に達すると想定しました。 このレベルに達すると、データをアンロードおよびアーカイブするためのスクリプトが起動されました。
それでも、テーブルのサイズを監視する必要性は残っています。テーブルにまったく注意を払わないと、テーブルが大幅に大きくなる可能性があります。 最終的に私たちの顧客の一人に起こりました。
すべてが悪い
さまざまな理由で、このプロバイダーの専門家は、セッションとテーブルのサイズの監視を設定せず、監視サービスを接続しませんでした(特に遅延クライアントの場合、システムの動作のメトリックを収集し、問題の可能性を通知できる特別なツールを作成しました)。
テーブルは成長しており、データベースのすべてが起こっていた会社も、サポートサービスもそれを知りませんでした。 最終的に、そのサイズは3,600万行に達し、最大制限の2倍以上になりました。
この特定のオペレーターでは、サブスクライバーはVPN経由でネットワークにアクセスしました。つまり、RADIUSプロトコルを使用してデータベースに既にアクセスしていたVPNサーバーにアクセスする必要がありました。
その結果、バックボーンスイッチのいずれかの再起動の結果としてオペレーターのネットワークでサブスクライバーアクティビティが急増した日に、RADIUS課金サーバーは、サブスクライバーの着信フローを即座に承認できませんでした。
これは何が起こったのかです-ある時点でのセッションテーブルからの選択のパフォーマンスは大幅に低下しました。 これにより、サブスクライバーの承認プロセスには、割り当てられた時間内に完了する時間がありませんでした。 その結果、ユーザーはネットワークへのアクセス拒否を受信し始め、システムを圧倒する実際の雪崩にマージされた承認要求を再送信し始めました。
要求処理がタイムアウトすると、VPNサーバーは承認のためにさらに2、3の要求を送信します。それらを再度処理するには、その巨大なテーブルからデータを読み取る必要があります。 その後、サブスクライバーにはアクセス拒否に関するメッセージが表示されます。 当然、そのようなメッセージを受け取ったユーザーは、再び接続を確立しようとし、すべてが再び繰り返されます。 したがって、RADIUSサーバーの実際のDoSで状況が発生しました。
どうする
プロバイダーは、加入者の承認に関する深刻な問題に直面して、サポートサービスを利用しました。 問題の原因を非常に迅速に特定することができました-セッションを含むテーブルが大きすぎ、さらに、IOWAITの上位リクエストにセッションテーブルからの読み取りの同じリクエストが含まれていました。 この状況を解決する方法は1つしかありませんでした-データベース内のテーブル行をクリアすることです。 同時に、データは失われなかったため、以前のどこかにコピーする必要がありました。
したがって、レコードをCSVファイルにアップロードして、テーブルのサイズを小さくしました。 これらの作業中に加入者の一部をネットワークに入れるために、RADIUSサーバーの自律動作モードもアクティブになりました。 キャッシュメカニズムを使用することで構成されます。サブスクライバーの最後の承認の結果に関するデータはキャッシュに保存されるため、請求との接続が失われた場合、サーバーはこのデータを使用してユーザーを承認できます。
当時の自律モードメカニズムは非常に単純で、欠点もありました。たとえば、キャッシュ内のデータはデータベースとのレプリケーションが常に行われていないため、不一致が生じる可能性がありました。 これは、ユーザーが1か月前に最後にログインし、その後インターネットに料金を支払わずにブロックする必要があった場合、1か月前に保存されたレコードに基づいてオフラインで作業する場合、システムはユーザーを承認します-または、アクセスする権利を持つユーザーを承認しませんただし、最後の接続試行でブロックされました。 しかし、この状況では、それは悪の少ない方でした。
その結果、セッションを含むテーブルの最大行数が3,000万行に減少すると、サブスクライバー認証が再び機能し始め、RADIUSサーバーのオフラインモードを無効にすることができました。
レッスン
この物語は私たちに多くの思考の糧を与えました。 クライアントに推奨事項を提示したり、重要なポイントを監視するための有料の機会を提供したりするだけでは不十分であることが判明しました。最終的には、アクションはクライアントに任されます。 そのため、クライアントシステムの問題の発生を自分で追跡できる新しい監視スキームを実装しました。
ここで、上記と同様の潜在的に危険な状況を検出すると、Lateraサポートサービスに対してアプリケーションが作成されます。
さらに、データとRADIUSサーバーのキャッシュプロセスを使用して作業を整理する方法を変更しました。 これにより、新しいバージョンの課金にアーカイブメカニズムが作成されました。これは、絶えず成長しているテーブルのデータを個別のOracleスキームにアーカイブすることを可能にします。 このプロセスはバックグラウンドで実行され、請求の操作には影響しません。 さらに、クライアントの場合、このメカニズムは、セッションに関するレポートを作成するときに、「タンバリンで踊る」ことなく、アーカイブからダイアグラムのメインとテーブルからデータを同時に受信するように機能します。
また、キャッシュとして機能するのではなく、サブスクライバーの承認に必要なメインの課金データベースから複製された情報をローカルに保存するローカルデータベースを備えた完全自律型RADIUSサーバーを作成しました。 このようにして、ブロックされるべきサブスクライバーへの通信サービスの提供の可能性の問題と、許可される必要があるユーザーのアクセス拒否が解決されました。 RADIUSサーバーの新しいバージョンは、課金との接続が切断された場合に、最も簡単に状況から抜け出すためのメカニズムを実装しています。 請求の復元力の確保に関する記事でそれらを説明しました。
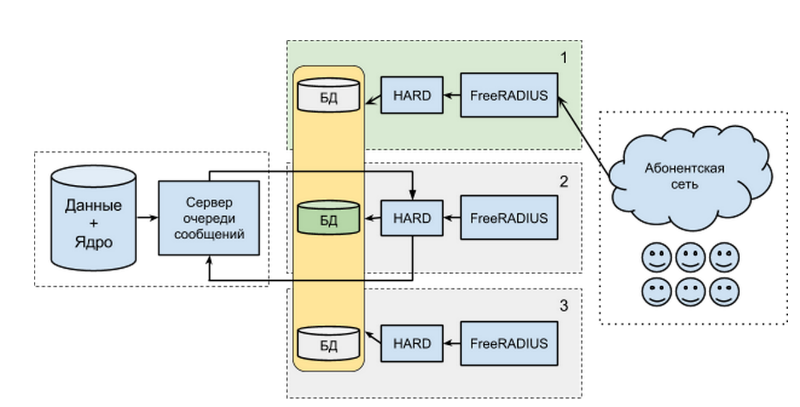
スキームを簡単に説明すると、各アクセスサーバーはいくつかのコンポーネントで構成されます。
- 加入者プロファイルと消費されたサービスのデータを含むデータベース。
- HARDというコードネームのアプリケーション。 次のコンポーネントからのHTTP要求に応答します。
- FreeRADIUS-標準のAAAプロトコルを実装するサーバー-RADIUS。 加入者ネットワークと直接通信し、バイナリ形式のリクエストを通常のHTTP + JSON for HARDに変換します。
すべてのAAAサーバー(これはMongoDB)のデータベースは、1つのメインノード(マスター)と2つのスレーブでグループ化されます。 サブスクライバネットワークからのすべての要求は1つのAAAサーバーに送られますが、メインデータベースを備えたサーバーである必要はなく、望ましくない場合もあります。
何かがうまくいかず、コンポーネントの1つに障害が発生した場合、サブスクライバーはサービスにアクセスできなくなります。 おそらく、彼らはまったく何も気づかないでしょう。
さらに、セッションテーブルのサイズの追跡など、テーブルのサイズの監視を継続します。非アーカイブ期間中のデータ増加の影響を受けません。
今日は以上です。見てくれてありがとう! ブログを購読することを忘れないでください。