
コグニティブコンピューティングは、過去数年間の傾向です。 これらは多くの専門家が非常に速いペースで開発している技術であり、人々が膨大な情報の流れに対処するのを助けます。 さらに、このストリームは非常に深く、広く、比fig的に言えば、これは人類によって生成された情報のストリーム全体です。 人間の脳は、非構造化データ配列を分析して処理し、「棚に置く」ことができる強力なシステムです。 しかし、このツールでさえ、私たちの時代の情報の流れに対応していないため、人間は通常の個人用および超生産的なシステムの両方でコンピューターを自分のサービスに置いています。 しかし、ここで異なる性質、つまり、処理中のデータを構造化する必要性から問題が発生しました。 毎日、人類は約2.5キロバイトのデータを生成し、その80%は構造化されていません。 そしてこれは、これらの80%が従来の技術を使用して作成された現代のコンピューターシステムからは見えないことを意味します。
コグニティブコンピューティング。人間の脳の機能を部分的に繰り返し、彼らの有機的な先駆者が救助に来るよりも何倍も効果的に機能することができる技術。 外部からの情報の処理と分析を担当する脳機能のごく一部についてのみ言及していることに言及する価値があります。 自己学習システムについても、一定の前提を置いて話をすることができます。 しかし、それにもかかわらず、認知技術には多くの能力があり、個人とビジネス構造の両方の生活を簡素化します。
このようなシステムは、銀行、材料科学、ビジネス最適化、都市インフラ管理、環境評価、科学および医学のさまざまな分野の研究など、非常に多様な分野で使用できます。 認知技術の主な目的は、非構造化データを便利な方法で操作する機会を人に与えることです。
同時に、特定のアルゴリズムに従うだけでなく、運用中の多くのサードパーティ要因を考慮した新しいタイプのシステムが徐々に作成され、自習し、過去の計算の結果とサードパーティのリソースを使用できます(例としてインターネット)。 新しいシステムのアーキテクチャは、フォンノイマンのアーキテクチャとは異なります。

ジョン・フォン・ノイマン
ご存じのように、 フォンノイマンの原則は次のとおりです。
記憶の同質性の原理 。 コマンドとデータは同じメモリに保存され、外部ではメモリと区別できません。 それらは使用方法によってのみ認識できます。 つまり、メモリセル内の同じ値は、アクセス方法のみに応じて、データ、コマンド、およびアドレスの両方として使用できます。 これにより、コマンドで数値と同じ操作を実行できるため、さまざまな可能性が広がります。 そのため、コマンドのアドレス部分を周期的に変更して、データ配列のシーケンシャル要素へのアクセスを提供できます。 この手法はコマンドの変更と呼ばれ、現代のプログラミングの観点からは歓迎されません。 1つのプログラムのコマンドが別のプログラムの実行の結果として取得できる場合、同質性の原則の別の結果がより有用です。 この機能は、翻訳の基礎です。高レベル言語から特定のコンピューターの言語へのプログラムテキストの翻訳です。
ターゲティングの原理 。 構造的には、メインメモリは番号付きセルで構成されており、プロセッサはいつでも任意のセルを使用できます。 コマンドとデータのバイナリコードは、ワードと呼ばれる情報の単位に分割され、メモリセルに保存されます。対応するセルの番号(アドレス)は、それらにアクセスするために使用されます。
プログラム管理の原則 。 問題を解決するためのアルゴリズムによって提供されるすべての計算は、一連の制御語-コマンドで構成されるプログラムの形式で提示する必要があります。 それぞれが、コンピューターによって実装される一連の操作から特定の操作を規定します。 プログラムコマンドは、コンピューターのシーケンシャルメモリセルに格納され、自然な順序で、つまりプログラム内の位置の順に実行されます。 必要に応じて、特別なコマンドを使用して、このシーケンスを変更できます。 プログラム命令の実行順序を変更する決定は、以前の計算の結果の分析に基づいて、または無条件で行われます。
バイナリコーディングの原理 。 この原則によれば、データとコマンドの両方のすべての情報は、2進数字0と1でエンコードされます。各タイプの情報は、2進シーケンスで表され、独自の形式を持っています。 特定の意味を持つ形式のビットシーケンスは、フィールドと呼ばれます。 数値情報では、通常、符号フィールドと有効数字のフィールドが区別されます。 コマンド形式では、オペレーションコードフィールドとアドレスフィールドの2つのフィールドを区別できます。
コグニティブコンピューティングシステムの基本要素は次のとおりです(IBM Redbook-Rob High-“ The Age of Cognitive Systems”):
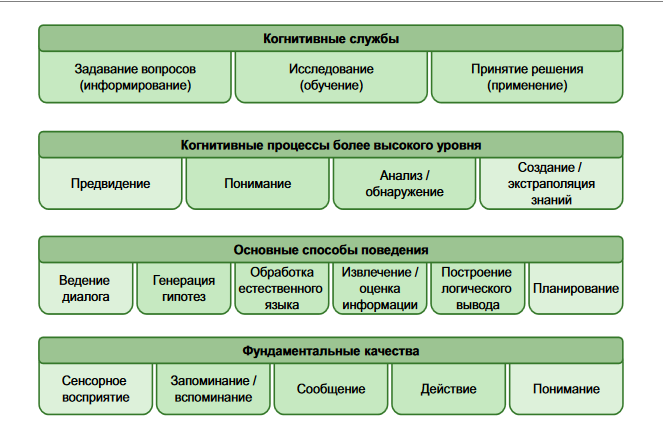
その目的(個人の情報環境での作業の簡素化)を満たすために、認知システムは次のようにする必要があります。
- アダプティブ 。 変化する目標や目的など、情報環境の変化を研究する必要があります。 また、情報を分析するときは、予測できない要因を考慮する必要があります。 コグニティブシステムは、動的データを処理し、リアルタイムまたはそれに近い結果を提供できる必要があります。
- インタラクティブ 。 彼らは、ユーザーであるユーザーが望みの結果を得るのを快適に感じるように、ユーザーと対話する必要があります。 また、このようなシステムは、他のシステム、デバイス、クラウドサービス、および人々と連携できる必要があります。
- 自己学習 認知システムの作業は、新しいデータだけでなく、過去の作業の結果にも基づいている必要があります。 彼らは以前の反復を「記憶」し、必要に応じてこの情報にアクセスする必要があります。
- コンテキスト 。 価値、時間、場所、ユーザープロファイル、目標、プロセス、タスクなどのコンテキスト要素を理解、識別、強調する必要があります。 構造化および非構造化データ、入力デバイスなど、複数の情報源にアクセスできるようにします。
認知システムは統合することも、既存の情報システム(フォンノイマンアーキテクチャのシステムを含む)を使用して、さまざまなインターフェイスやツールと連携することもできます。
認知システムの範囲は非常に広範囲です:
ビジネスでは、認知システムにより、インフラストラクチャ、エンタープライズルーチン、およびその他の要素の問題領域を検出できます。 「ボトルネック」を排除した結果、労働者の労働生産性と部門全体の効率が向上します。 従業員のための多大な資金と時間が、機械時間と同様に節約されます。
認知技術は、次のような多くの場合、ビジネスで役立ちます。
- 関与:特定の各人の側面を理解することで、認知システムはユーザー、顧客との個別の対話を実行できます。
- 専門知識:認知システムを使用して、財務事項を含む企業の活動を監査できます。 その結果、会社はクライアントに対して個別のアプローチを取ります。
- 製品とサービス:同じシステムは、一部の企業のサービスを継続的に改善するのに役立ち、改善および改善が可能な弱点を示しています。
- 発見:はい、企業または個人の科学者が実施する科学研究では、最も暗黙的なデータを表面に取り込み、研究し、記録することができるため、認知技術は非常に有益です。
- 意思決定:情報の依存関係の増加を識別し、このデータを使用して、システムは単一の会社またはその部門の意思決定を改善できます。

IBM Watson Cognitive System機能の適用-トレンド
医療では、認知システムは、患者を治療するための個々のアプローチなどの目標に徐々に移行するのに役立ちます。 これは、たとえば癌などの複雑な場合に特に当てはまります。 ヒトDNAの分析と追加要因(居住地、積載量など)の比較は、以前よりもはるかに効果的に治療するのに役立ちます。 特定の人の身体の遺伝子型と特性を研究することにより、医師は特定の症例で最も効果的な薬と手順を処方できます。
料理において、認知システムはまったく予期しない何かを提供し、新しい分野を切り開き、新しい製品の組み合わせを追加できます。 すでに、いくつかの認知システム(たとえば、Watson)は、製品の事前定義リストに基づいて、さまざまな料理のレシピを作成できます。
スポーツでは、認知計算はリアルタイムでさまざまなアスリートのトレーニングを評価するのに役立ち、トレーナーが必要とする特性を持つ選手のチームを募集します。
そして、これはすべて認知システムができることのほんの一部にすぎません。 このトピックについては、次のいずれかの記事で詳しく説明します。
さまざまな国の多くの組織や政府が認知システムの作成に取り組んでいます。 しかし、現時点では、膨大な数のサブシステムと要素を含む最も完璧で全体的な認知システムはIBM Watsonです。 IBMブログはこのシステムについて何度も書いていますが、毎日システムが開発および改善されるため、このシステムについては引き続き話し合う予定です。 これは、単に思考するだけでなく、先を見越して考える未来のカテゴリーで動作する試みです。
出典:IBMマテリアル。