
コンテナに関する情報を記事
実際、開発者が実行中のコンテナ内の何かを変更したくない場合、それは一時的またはテスト専用になりますが、画像の構造、そのレイヤー、サイズを考慮する必要はありません。 完成した製品では、各冗長レイヤーが余分なメガバイトの情報に注がれます。この情報は、Docker Hubへの低速接続を介してダウンロードするか、圧縮ファイルに転送する必要があります。 また、製品バージョンを更新する必要がある場合は、システム全体よりも、イメージとそれに依存する1つのコンテナーを置き換えるほうが便利です。 この場合、コンテナーのイメージを実稼働で便利に使用し、製品をタイムリーに更新し、クラスターに展開するときに作業を楽にするために、コンテナーのイメージを最適に組み立てる方法について考えが生じます。
まず、画像のレイヤーが何であるかを判断しましょう。 Dokerfileを可能な限り詳細にペイントすると、新しいレイヤーが追加または変更されたファイルになります(将来のコンテナー内の環境変数であっても)。 混乱しないように、テンプレートとは、コンテナの不完全なイメージを意味します。
同じタイプの要素のセットとしてのファイルを想像してください。Q.システムに存在するすべてのプロセスまたはコンテナを定義し、セットXを構成します。このような各プロセスは、ファイルの他の要素に依存するある種の実行可能ファイルに対応しますシステム。 このようなセットA、B、C、D、およびEのセットQ上のプロセス(セットXの要素)の投影を検討します。

ファイル(ライブラリなど)間の依存関係を要素の上の行の形式で表し、セットA(a1-a2、a2-a3、a3-a4)、B(b1-b2)、C(c1-c2、c2- c3、c3-c4、c5-c6、c6-c4)、D(d1-d2、d2-d3、d3-d4、d5-d6、d6-d4、d7-d4)。 セットXのプロセスが右側に表示され、実行可能ファイル(a4、b2、c4、d4、e1)とその依存関係が左側に表示されます。 実行可能ファイルについては、ライブラリ、環境変数、デバイスを定義し、対応する要素の形で反映します。 各プロセスには複数の実行可能ファイルがないため、コンテナを作成する際にこれらの要素が重要になります。 また、各ファイルを詳細に説明する必要はありません。 ライブラリが他の場所で使用されていない場合は、ユーティリティを説明するだけで十分です。たとえば、 curlユーティリティを1つの要素と見なします。
最終製品の記事の冒頭で決定された条件に従って、セットQのすべての要素をコンテナとテンプレートに組み立てます。 各反射について、いくつかのセットに同時に存在する共通要素(ノード)を決定し、それらをマークしますQ(q1)= A(a1)= C(c1)= D(d1)、Q(q2)= A(a3)= B( b1)、Q(3)= C(c5)= D(d5)、Q(4)= C(c6)= D(d6)そして、個々の要素を無視して、対応する依存関係を確立します。
将来、これらの要素を使用して、それらに基づいてコンテナテンプレートを作成します。 各セットの要素は絶えず変化するため(一部の要素はより頻繁に、他の要素はそれほど頻繁ではない)、特別な方法でそれらを強調する必要があります。 これを行うには、実行可能ファイルに対応する要素(a1-a2-a3-a4など)から開始して、セット間の依存関係によって最も長いチェーンを見つけます。 そのようなチェーン内のノードの数は、セット内の要素を更新する最大の度合い、つまり4に対応します。 次数が1の場合、システム内のこの要素はほとんど更新または変更されないため、別のテンプレートで選択することを想定しています。 最大限、この要素は絶えず変化するため、コンテナですでに選択されている必要があります。
各プロセスの表示は相互に依存する要素のセットであるため、この構造にもインデックスを付ける必要があります。 節点要素はすべてのセットに存在し、各セットに対して個別にインデックスが付けられます。 例:A(a1 = 1、a2 = 2、a3 = 3、a4 = 4)、B(b1 = 2、b2 = 3)、C(c1 = 1、c2 = 2、c3 = 2、c4 = 3、 c5 = 2、c6 = 2)、D(d1 = 2、d2 = 2、d3 = 3、d4 = 4、d5 = 2、d6 = 3)、E(e1 = 3)。 節点要素を更新する最終的な度合いは、すべてのセットの中で最大のインデックスになります。 次のようになります:q1 = 2、q2 = 3、q3 = 2、q4 = 3。
定義上、各コンテナは1つのパターンのみで構築されるため、2つの同一のパターンでノード要素を形成することはできません。 したがって、同じ程度の要素のすべての依存関係を1つのテンプレートに含める必要があります。

結合の結果、新しい依存関係が表示されるため、この操作を数回繰り返す必要があります。
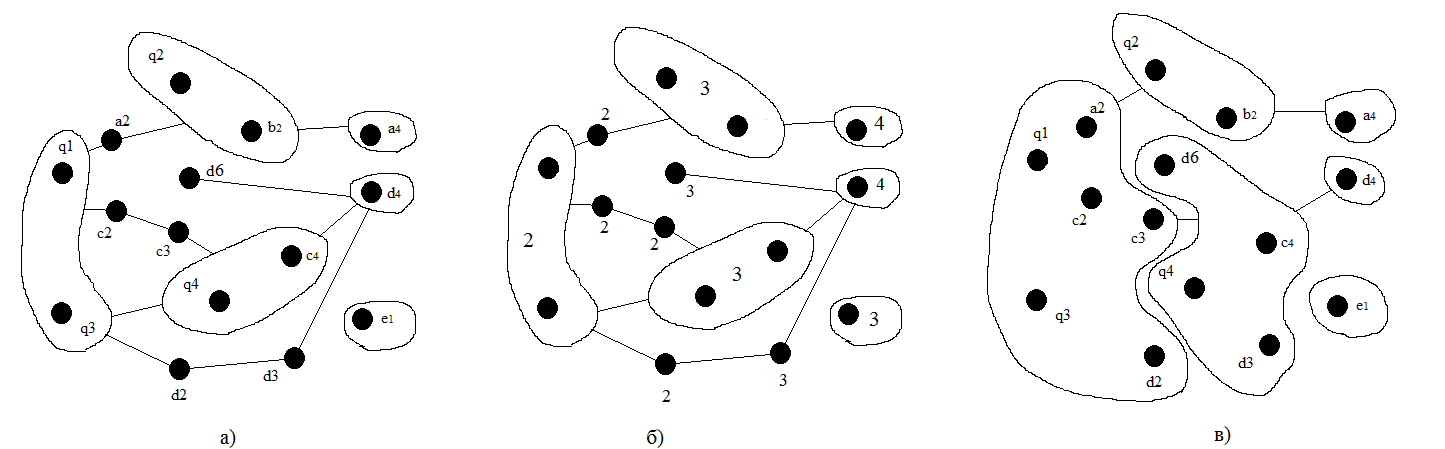
最後に、テンプレートが依存するすべての要素を選択し、それらを1つに結合する(インデックスが一致する場合)か、それらに依存するテンプレートを使用する必要があります。 結果の構造は関係を反映し、その形成は要素の更新の程度とそれらの依存性を考慮に入れました。
結果の画像とコンテナの最終的な構造を図に示します。

この記事の結果は、使用されているファイルシステム全体が要素に分割されている場合に、Dockerイメージを形成するアプローチです。 これらの要素は、最終製品または開発段階での更新の頻度に応じてマークされます。 そして、それらは、起動されるコンテナーに基づいて、論理的に完全なイメージに結合されます。
PS:記事の間違いと少し厄介なプレゼンテーションのために謝罪しますが、写真を見て結論を読むだけで記事の意味を把握できると思います。