
近年、世界がソフトウェアへの依存を強めているだけであることは間違いありません。 アプリケーションには高可用性が必要であり、必要な機能を効率的に実行し、適切なコストが必要です。 これらの特性は、ある程度、ソフトウェアアーキテクチャによって決定されます。
IEEE 1471では、次の定義が与えられています 。「アーキテクチャは、このシステム(および外部環境)のコンポーネント間の関係を記述し、その設計と開発の原則を定義するシステムの基本的な組織です。」 ただし、アーキテクチャの他の多くの定義では、構造要素だけでなく、その構成、インターフェイス、その他の接続リンクも認識されます。
これまでのところ、一般的に受け入れられているアーキテクチャのパラダイムの分類はありませんが、それでも、いくつかの基本的で広範なアーキテクチャパターンまたはスタイルを簡単に識別できます。 それらのいくつかを見てみましょう。
「チャンネルとフィルター」(パイプとフィルター)
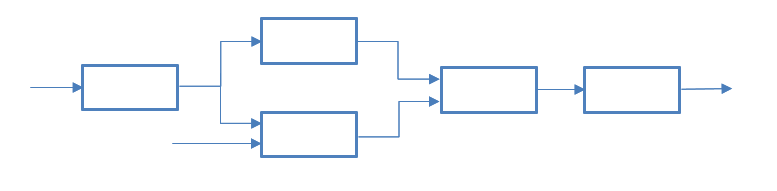
図1-パイプとフィルター
このタイプのアーキテクチャは、アプリケーションプロセスが複数のステップに分割され、個々のハンドラーで実行できる場合に適しています。 主なコンポーネントは「フィルター」と「パイプ」です。 「データソース」と「データコンシューマ」が追加で割り当てられる場合があります。
各データ処理ストリームは、データソースで始まり消費者で終わる一連の交互のフィルターとチャネルです。 チャネルは、データ転送と同期を提供します。 一方、フィルターはデータを入力として受け取り、それを処理し、他の表現に変換してから渡します。
たとえば、フィルターの1つはCaesarの暗号を実装できます。置換暗号では、テキスト内の各文字が、アルファベットの左または右の特定の一定数の位置にある文字に置き換えられます。 Caesarのコードのバリエーションの1つはROT13で、13のステップがあります。
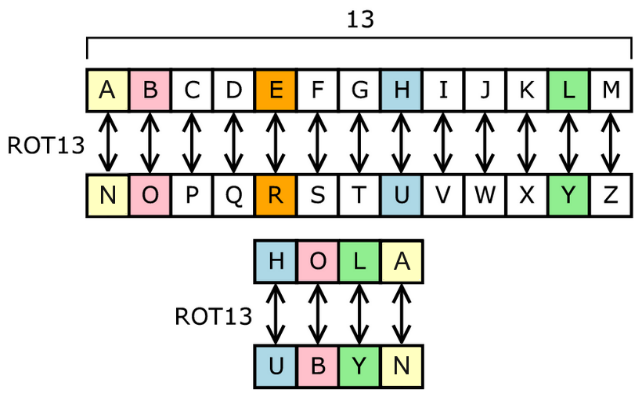
図2-ROT13の原理
標準の端末Unix trユーティリティを使用して実装するのは非常に簡単です。
$ # Map upper case AZ to N-ZA-M and lower case az to n-za-m $ echo "The Quick Brown Fox Jumps Over The Lazy Dog" | tr 'A-Za-z' 'N-ZA-Mn-za-m' Gur Dhvpx Oebja Sbk Whzcf Bire Gur Ynml Qbt $ tr 'A-Za-z' 'N-ZA-Mn-za-m' <<<"The Quick Brown Fox Jumps Over The Lazy Dog" Gur Dhvpx Oebja Sbk Whzcf Bire Gur Ynml Qbt
Pythonコードは次のとおりです。
def rot13(text): rot13ed = '' for letter in text: byte = ord(letter) capital = (byte & 32) byte &= ~capital if ord('A') <= byte <= ord('Z'): byte -= ord('A') byte += 13 byte %= 26 byte += ord('A') byte |= capital rot13ed += chr(byte) return rot13ed
フィルタは簡単に交換、再利用、再配置できるため、限られたコンポーネントセットに基づいて多くの機能を実装できます。 さらに、アクティブフィルターは並行して動作できるため、マルチプロセッサシステムのパフォーマンスが大幅に向上します。 ただし、欠点があります。たとえば、フィルターは入力データの処理よりも入力データの変換により多くの時間を費やすことがよくあります。
このアーキテクチャの使用例は、 UNIX Shellです。その設計者の1人はDouglas McIlroyでした。 別の例として、コンパイラのアーキテクチャがあります。これをフィルタのシーケンスと見なす場合、レクサー、パーサー、セマンティックアナライザー、コードジェネレーターです。
このタイプのアーキテクチャの詳細については、 こちらとこちらをご覧ください 。
階層化アーキテクチャ
これは、各層が特定の機能を実行する最も有名なアーキテクチャの1つです。 必要に応じて、任意の数のレベルを実装できますが、レベルが多すぎるとシステムが過度に複雑になります。 多くの場合、3つの主要なレベルがあります:プレゼンテーションレベル、ロジックレベル、およびデータレベル。
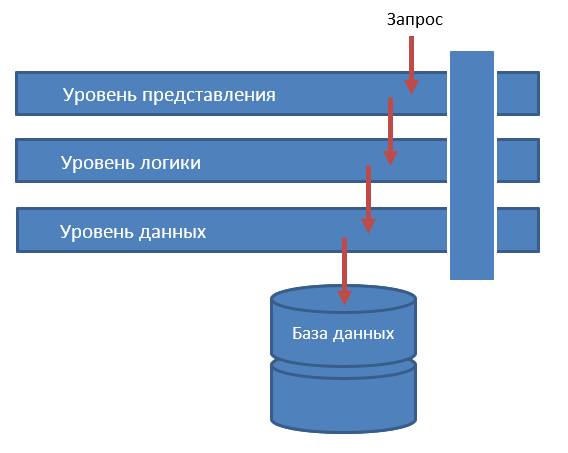
図2-階層化アーキテクチャ
レイヤーは、その隣人が何をするかを知る必要はありません。 ここでは、責任の分割などのプロパティが明示されます。 3つのレイヤーすべてが閉じている場合、上位レベルへのユーザーのリクエストは、上位レベルから最下位へのヒットのチェーンを開始します。 この場合、プレゼンテーションレイヤーはユーザーインターフェイスとユーザーのデータ表示を担当し、物理データウェアハウスの存在については何も知りません。 ロジックレベルはデータベースの存在について何も知りません。ビジネスロジックのルールだけがそれを「心配」します。 データベースへのアクセスは、データ管理のレベルを通してのみです。
このようなアーキテクチャを使用する利点は、開発の容易さ(主にこのタイプのアーキテクチャは誰もが知っているという事実による)とテストの容易さです。 欠点の中で、パフォーマンスとスケーリングの潜在的な問題を特定することができます-全体の障害は、すべてのレベルでクエリとデータを通過する必要があることです(再び、すべてのレイヤーが閉じられた場合 )。
このパターンの最も有名な例の1つは、 OSIネットワークモデルです。 マルチレベルアーキテクチャの詳細については、たとえば、次の3人のプログラマと開発者のブログをご覧ください。
イベント駆動型アーキテクチャ(EDA)
これは、スケーラブルなシステムを作成するために広く使用されている一般的な適応パターンです。 イベント指向アーキテクチャの原則を理解するために、 Complexity Academyからこのビデオを見ることができます。

図3-イベント指向のアーキテクチャ
ソフトウェアについて話すと、このスキームには、開始イベントとハンドラーが応答するイベントの2種類のイベントがあります。 ハンドラーは、1つのタスクを(理想的には)担当し、作業に必要なビジネスロジックを含む、独立した独立したコンポーネントです。
メディエーターはいくつかの方法で実装できます。 最も簡単な方法は、Apache Camel、Spring Integration、またはMule ESB統合用のフレームワークを使用することです。 より複雑な管理機能を必要とする大規模なアプリケーションの場合は、ビジネスプロセス管理の概念(たとえば、jBPLエンジン)を使用して中間体を実装できます。
イベント駆動型アーキテクチャは、比較的複雑なパターンです。 この理由は、その分散された非同期の性質にあります。 ネットワークの断片化の問題を解決し、イベントキューエラーを処理する必要があります。 このアーキテクチャの利点は、高いパフォーマンス、展開の容易さ、驚くべきスケーラビリティです。 ただし、システムのテストプロセスが複雑になる場合があります。
イベント指向アーキテクチャの詳細については、 こちらをご覧ください 。
マイクロカーネルアーキテクチャ
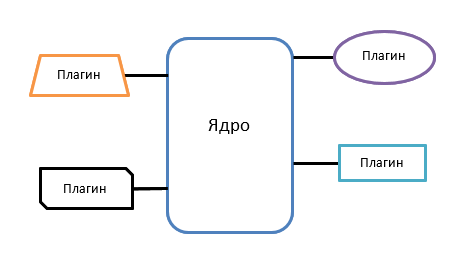
このパターンは、メインシステム(カーネル)とプラグインの2つのコンポーネントで構成されています。 カーネルには最小限のビジネスロジックが含まれていますが、必要なプラグインのロード、アンロード、および起動を管理します。 したがって、プラグインは互いに切断されます。
プラグインは互いに独立して開発できるため、そのようなシステムは非常に高い柔軟性を持ち、その結果、簡単にテストできます。 このようなアーキテクチャに基づいて構築されたアプリケーションのパフォーマンスは、接続されているアクティブなモジュールの数に直接依存します。
マイクロカーネルアーキテクチャの最良の例は、おそらくEclipse IDEです。 アドオンなしでEclipseをダウンロードすると、完全に空のエディターが得られます。 ただし、プラグインを追加すると、空のエディターが便利でカスタマイズしやすい製品に変わり始めます。 もう1つの良い例はブラウザです。追加のプラグインを使用すると、その機能を拡張できます。
マイクロカーネルアーキテクチャの詳細については、 こちらとこちらをご覧ください 。
マイクロサービスアーキテクチャ
このタイプのアーキテクチャにより、Martin L. AbbottとMichael T. FisherによるThe Art of Scalabilityで説明されているScale Cubeの Y軸に沿ってアプリケーションをスケーリングできます。 この場合、アプリケーションはマイクロサービスと呼ばれる多くの小さなサービスに分割されます。 各マイクロサービスにはビジネスロジックが含まれており、完全に独立したコンポーネントです。 1つのシステムのサービスを異なるプログラミング言語で記述し、異なるプロトコルを使用して相互に通信できます。
各マイクロサービスは個別のプロジェクトであるため、開発チーム間でそれらの作業を分散できます。つまり、数十人のプログラマーが同時にシステム上で作業できます。 マイクロサービスアーキテクチャにより、アプリケーションを簡単にスケーリングできます-新しい機能を実装する必要がある場合(各マイクロサービスを個別に展開できます)、新しいサービスを作成するだけで、誰も機能を使用しない場合は、サービスをオフにします。
このパターンの明らかな欠点は、マイクロサービス間で大量のデータを転送する必要があることです。 メッセージングのオーバーヘッドが大きすぎる場合は、プロトコルを最適化するか、マイクロサービスを組み合わせる必要があります。 このようなシステムのテストも簡単ではありません。 たとえば、Spring BootでサービスのすべてのREST APIをテストするクラスを作成する場合、テストされたマイクロサービスとそれに関連付けられたマイクロサービスを開始する必要があります。 これは核物理学ではありませんが、プロセスの複雑さを過小評価しないでください。
マイクロサービスアーキテクチャの詳細については、 こちら 、 こちら 、 こちらをご覧ください 。
追加資料
この記事では、いくつかのタイプのソフトウェアアーキテクチャを取り上げました。 もちろん、他の多くのパターンはここでは影響を受けませんでした。 このトピックに関する追加資料として、次のリソースを参照できます。
- O'Reilly :ソフトウェアアーキテクチャに関する一連の記事。
- SE :ソフトウェアアーキテクチャに関する最高の本。
- Fromdev :誰もが読むべきソフトウェアアーキテクチャに関する5つのベストブック
- All Things Distributed :AmazonのテクニカルディレクターであるWerner Vogelsによる、スケーラブルで信頼性の高い分散システムの構築に関するブログ。
- Quora :ソフトウェアアーキテクト向けの最高の本、記事、ブログ。
私たちのブログは、ファイルシステム開発の方向性から業界のイベントまで、 データセンターの信頼性のトピックから仮想化まで、ロシアのビジネスをクラウドに移行するための私たち自身の事例など、幅広い問題を扱っています。
さらに、「クラウド」プロバイダーのサポートサービスの作業とパフォーマンス最適化のトピックについて説明します。これについては、次の資料のいずれかで説明します。