
データ管理システムの歴史は、磁気テープの出現にさかのぼりますが、磁気ディスクの出現により現代的な外観を獲得しました。 今日、私たちはファイルシステムのさらなる開発の方向性を検討することにしました。
従来のデータストレージシステムでは、特定のサイズの小さな情報ブロックとメタデータの両方でアクションが実行されます。 現在まで、オブジェクト用のストレージシステムが開発されており、データのあるブロックの代わりに、さまざまなパラメーターを持つオブジェクトが操作されています。 オブジェクトストレージシステムは、T-10 Object Storage Devices(OSD)標準に基づいています。
ブロックストレージシステムとオブジェクトストレージシステムの基本的な違いは、最初の場合はデータとメタデータを含むブロックのセットからオブジェクトを作成し、2番目の場合はオブジェクトとそれに対応するメタデータを直接操作することです。
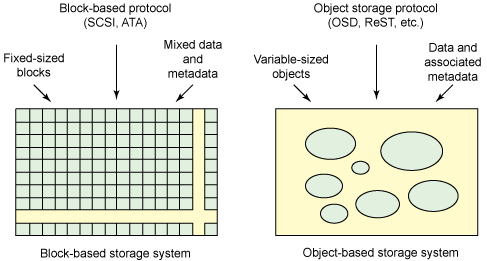
図1-ブロックおよびオブジェクトストレージシステム
オブジェクトストレージシステム上に構築されたファイルシステムの一例は、 exofs (拡張オブジェクトファイルシステム)です。
exofsスキーマは次のように表すことができます。
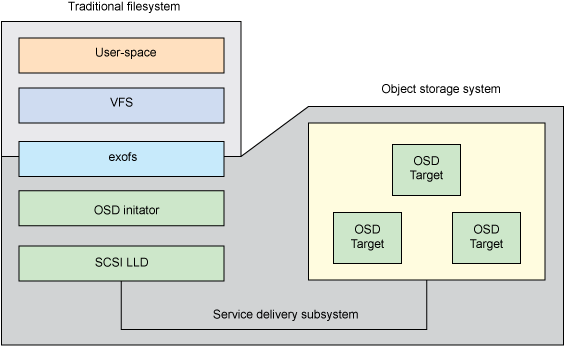
図2-exofsのスキーム
仮想ファイルシステムスイッチVFS(仮想ファイルシステムスイッチ)はexofへのアクセスを提供し、exofはすでにローカルOSDイニシエーターを介してストレージシステムと対話します。
オブジェクトの保存は興味深いアイデアですが、コンピューターサイエンス学部を卒業したRavi Tandonは、ログ構造化ファイルシステムに未来があると考えています。 「フラッシュとSSDテクノロジーがストレージシステムのさらなる開発に大きな役割を果たすため、これは私の意見です」とRavi氏は言います。 ログ構造のファイルシステムは、ソリッドステートドライブに最適です。この場合、書き込み操作はデバイス全体に均等に分散され、データ消去サイクルの数が減少するため、SSDの寿命を大幅に延ばすことができます。
ログ構造化ファイルシステムのアイデアは、1988年にJohn OusterhoutとFred Douglisによって提案され、1992年にSpriteオペレーティングシステムに実装されました。 一番下の行はこれです:ファイルシステムは、新しいデータとメタデータが書き込まれる循環ログの形式で提示され、空き領域は常に最後から取得されます。 つまり、ジャーナルには1つのファイルのコピーが多数含まれることがありますが、最新のものは常にアクティブと見なされます。 この興味深い機能にはいくつかの利点があります。
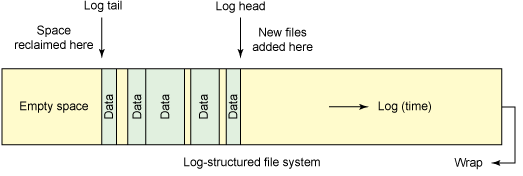
図3-ログ構造化ファイルシステム
このデータストレージへのアプローチにより、記録のオーバーヘッドが削減されます。記録は順次行われ、データはディスク上で高速になるため、ファイルシステムは高速になります。 また、Ravi Tandonは、ログ構造化システムがバージョン管理やデータリカバリなどの機能をサポートし、実際に「時間内に移動する」ことができると書いています。
ログ構造化ファイルシステムの例はNILFS2です。 NILFS2は、ファイルシステムの状態のスナップショットを取る方法を本当に知っています。 以前に削除または失われたファイルを回復する必要がある場合、これは非常に便利です。 ただし、すべての費用を支払う必要があります。ログ構造のファイルシステムにも欠点がないわけではありません。ここでは、ガベージコレクタを使用して古いデータとメタデータを削除する必要があります。 これらの時点で、パフォーマンスが大幅に低下する可能性があります。
考慮される2種類のファイルシステムは確かに優れています(ただし、欠点がないわけではありません)が、他にも価値のあるアイデアがあります。 特に、プログラマーでブロガーのジェフダーシーは、数年以内にローカルファイルシステムと分散ファイルシステムに分割され、後者は前者に基づいて構築されると考えています。 最初のケースに関しては、最近、ZFSおよびBtrfsファイルシステムがますます一般的になりました。
ZFS(Zettabyte File System)は、途方もなく巨大なサイズ(16エクサバイト)のファイルをサポートする128ビットファイルシステムであり、最大256ゼッタバイトのディスクボリュームで動作することができます。 ZFSプロジェクトリーダーのジェフボンウィックは、「128ビットのファイルシステムを実装すると、地球にデータを保存する量子機能を超えることになる」と述べました。 「海を沸騰させずに128ビットボリュームを埋めて保存することはできません」と Bonvik 氏は述べています。
これらの数値の大きさの例:1秒間に1,000個のファイルを作成した場合、ZFSのファイル制限に達するには約9000年かかります。 一般に、ZFSファイルシステムは、近い将来に制限に遭遇することがないように設計されています。
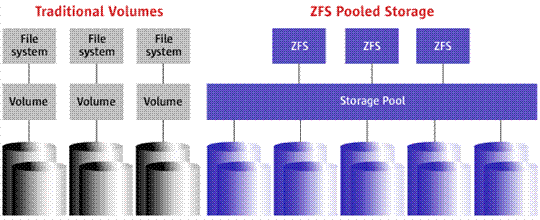
図4-従来のファイルシステムとZFS
ZFSは、データを含む仮想プール(zpool)の上に構築されます。 接続されたすべてのドライブが1つの巨大なパーティションの一部であることがわかります。 さらに、ディスクは、「自己修復」機能を備えた仮想RAIDアレイで相互に通信できます。 このファイルシステムでは、破損した場合にスナップショットを作成してデータを復元することもできます。 ZFSの詳細については、 こちらをご覧ください。
BtrfsファイルシステムはZFSの直接の競合相手であり、ほぼ同じ機能を備えています。 比較分析の例として、次の2つの記事を見ることができます: 1と2 。
www.diva-portal.org/smash/get/diva2:822493 / FULLTEXT01.pdf
分散ファイルシステムに関しては、 GlusterFSを開発しているJeff Darcy氏によると、彼らには未来があります。 ただし、この場合、信頼性に多くの注意を払う必要があります。 一般に、分散ファイルシステムは、ユーザーにとっては単一の統合システムのように見える独立したコンピューターの集まりです。
このコンセプトにはいくつかの利点があります。 例として、スケーリングの可能性が非常に大きい。 従来のファイルシステムは次のように機能します。ユーザーがファイルをサーバーに送信すると、そのコンテンツとメタデータは分離され、関連するストレージに保存されます。
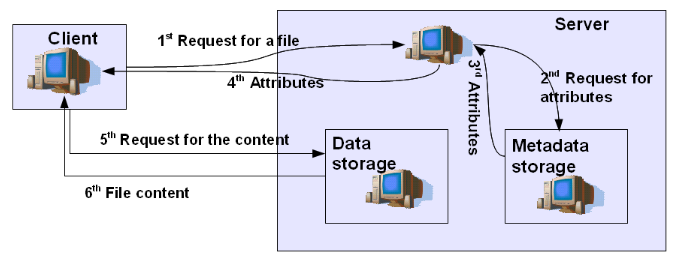
図5- DFSのアップロード
ユーザーがファイルを取り戻したい場合は、ファイルシステムを使用します。ファイルシステムは、ファイルの属性を持つメタデータを抽出し、データウェアハウス内の場所を決定します。 ファイルはクライアントに送信され、クライアントは受信メッセージを送信します。 原則として、このようなスキームには長所と短所の両方があります。
もちろん、ネットワークで作業しているときにディスク容量を節約できるという利点があります。 ただし、一方で、リモートファイルで作業する必要があります。これは、ローカルファイルで作業するよりもはるかに低速です。 さらに、リモートファイルにアクセスする実際の機能は、サーバーとネットワークのパフォーマンスに大きく依存します。
ところで、最近では、データセンターの信頼性を確認する方法について説明しました( こちらとこちら )。 さらに、 事例の例を挙げ、2016年のITインフラストラクチャ、情報セキュリティ、および通信のトピックに関するイベントのカレンダーを準備しました。