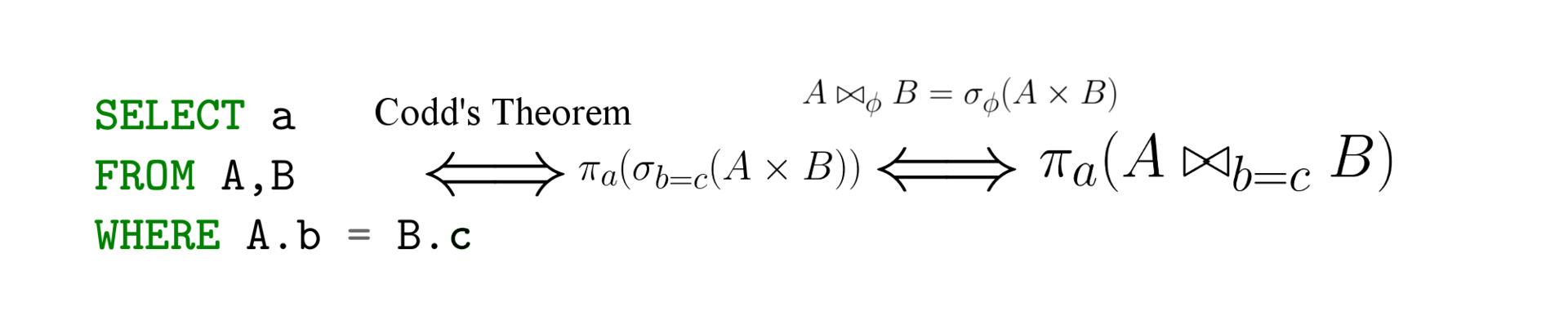
Habré以降では、リレーショナル代数とSQL がしばしば議論されますが 、これらの形式主義の間の関係に焦点を当てることはあまりありません。 この記事では、クエリ理論のまさに根源である、リレーショナル計算、リレーショナル代数、SQL言語について説明します。 簡単な例を使用してそれらを分析し、クエリの分析と作成のために形式を切り替えることが有用であることも確認します。
今日、なぜこれが必要なのでしょうか? データアナリストやデータベース管理者がデータを操作する必要があるだけでなく、実際には(半)構造化データから何かを抽出したり、既存のデータを変換したりする必要のある人はほとんどいません。 クエリ言語が特定の方法で構造化されている理由をよく理解し、それらを意識的に使用するには、基礎となるコアに対処する必要があります。 今日はこれについてお話します。
記事のほとんどは、理論が散りばめられた例で構成されています。 セクションの最後には、追加資料へのリンクがあります。興味がある人のために、最後にいくつかの文献とコースがあります。
内容
関係代数
キーオペレーター
 -リレーションA自体(ここでのリレーションは表および述語と同義です)はさらに、リレーション代数の表現です。リレーションA
-リレーションA自体(ここでのリレーションは表および述語と同義です)はさらに、リレーション代数の表現です。リレーションA
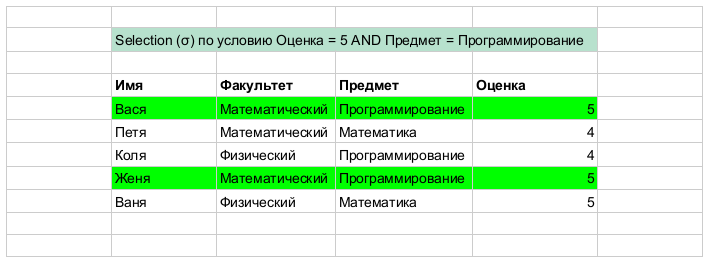
選択(選択、制限)
 -選択(選択、制限)、A-関係(述語、表)、
-選択(選択、制限)、A-関係(述語、表)、  -行(タプル、レコードなど)の選択に使用されるブール式
-行(タプル、レコードなど)の選択に使用されるブール式
選択は基本的に水平の行フィルターです。つまり、各行に沿って条件を満たしているものだけを残すことを想像できます。 。 わかりやすくするための簡単な例:
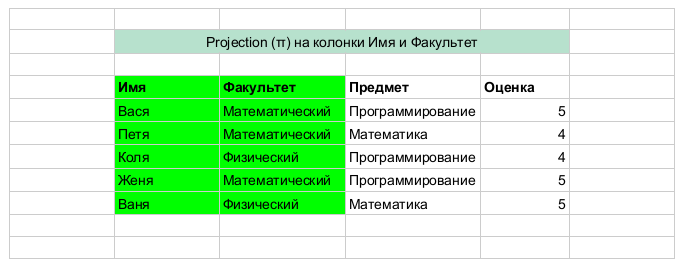
投影
 -属性A、B、...の投影(投影) 列(属性)A、B、...のみが残っているテーブルを返します。 以下の簡単な例。 実際、それは属性によるフィルターです。 ある意味、垂直フィルターです。
-属性A、B、...の投影(投影) 列(属性)A、B、...のみが残っているテーブルを返します。 以下の簡単な例。 実際、それは属性によるフィルターです。 ある意味、垂直フィルターです。
名前を変更
 -Aに関して列aの名前をbに変更します(属性、述語引数など)。 名前変更演算子を使用すると、代数が厳密に表現しやすいことを示す紳士へのお茶2杯
-Aに関して列aの名前をbに変更します(属性、述語引数など)。 名前変更演算子を使用すると、代数が厳密に表現しやすいことを示す紳士へのお茶2杯  )
)
デカルト積
 -2つの関係のデカルト積。AとBの文字列のすべての可能な組み合わせの大きな比率。
-2つの関係のデカルト積。AとBの文字列のすべての可能な組み合わせの大きな比率。

セット操作
関係代数は、集合上の古典的な演算子の集合の拡張です(関係は、順序付けられたタプルの集合です。これは、順序付けられたタプルの集合とまったく等しくないことに注意してください)。 StudentMarkテーブル(Name、Mark、Subject、Date)があり、タプル(Vasya、5、Informatics、2010年5月5日)が順序付けられていると仮定します-最初に、最初の(ok、またはゼロ)位置のName行、2番目の整数、 3番目の行と4番目の日付。 さらに、順序付けられたタプル自体(名前、マーク、件名、日付)は、関係の「内側」に順序付けられていません。
統一
 -AとBのすべての行の結合。制限は同じ属性です
-AとBのすべての行の結合。制限は同じ属性です
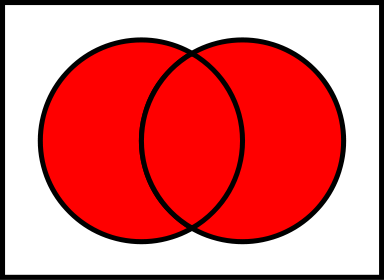
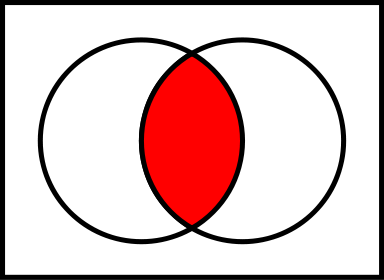
交差点
 -線の交差、同じ制限
-線の交差、同じ制限
差分セット
 -B-A、Bに存在するがAには存在しないすべての行、同じ制限
-B-A、Bに存在するがAには存在しないすべての行、同じ制限
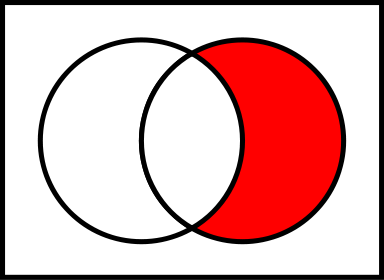
(B \ A; A-左側、B-右側)
ヘルパーオペレーター
 -参加(接続); joinは、テーブルAとBの2つのレコードを結合します。ただし、これら2つのレコードについて条件φが満たされている場合に限ります。
-参加(接続); joinは、テーブルAとBの2つのレコードを結合します。ただし、これら2つのレコードについて条件φが満たされている場合に限ります。

準備運動のタスク
次のスキームで作業します
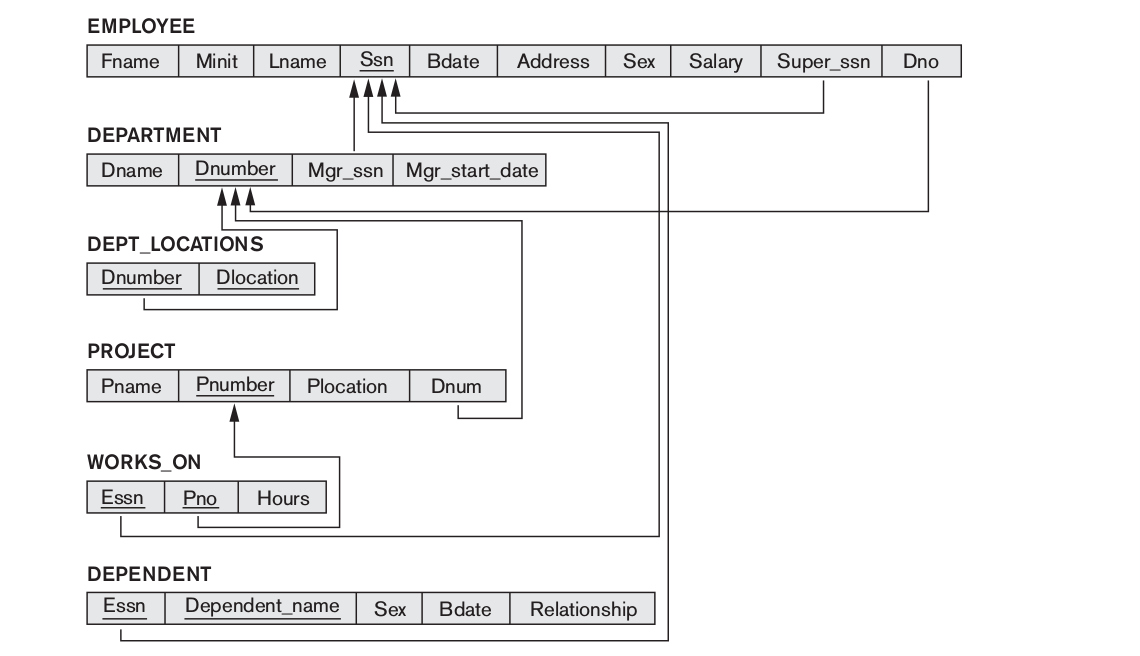
(図は、本から抜粋しています:Elmasri、Navathe-Fundamentals of Database systems;万が一の場合:本を強くお勧めしません;最後の選択を参照してください)
次に、関係代数のいくつかの簡単な問題を考えます。
最初のタスク。 プロジェクトXで週に10時間以上働く第5部門の全従業員の名前を印刷します。
(中間の結果は、新しい関係で「維持」できますが、これは必要ありません。)

2番目のタスク。 フランクリン・ウォンが直接率いる全従業員の名前を印刷します (そして、以下のソリューションで小さな間違いを見つけます)。

3番目のタスクでは、新しい演算子「集計」を使用する必要があります。 例で考えてみましょう:
各プロジェクトについて、すべての従業員がこのプロジェクトに費やした名前と週あたりの総時間数を表示します。

クエリの形式はa F b(A)であることに注意してください。a、bは列、Aは比率、aは集計関数(たとえば、SUM、MIN、MAX、COUNTなど)です。 次のように読み取ります。列aの各値について、bをカウントします。 つまり、複数の行が列aの1つの値に対応し、この行セットの列bの値を関数に入れて、対応する値で新しい属性fun_bを作成できます。
このクエリは、「古典的な」関係代数では表現できません(集約演算子Fなし)。 つまり、スキーマを満たすデータベースに対して正しい答えを与える単一のクエリを書くことはできません。
正確に与えられた結果が続くところで、後で分析しますが、集計を含むクエリは計算の複雑さのより高いクラスに属することに注意することができます。
この記事の後半で、問題のより興味深い例を検討して分析します。 ここで利用可能な解決策を備えたリレーショナル代数の問題の小さな選択もあります
SQL
このパートでは、SQL(構造化照会言語)について説明し、簡単な例を使用してSQLがリレーショナル代数とどのように一致するかを示します。
最初のタスクをもう一度考えてみましょう。
最初のタスク。 プロジェクトXで週に10時間以上働く第5部門の全従業員の名前を印刷します。
従来のソリューションは次のとおりです。

または、次のように書くこともできます。

またはまったく別の方法:

(追加のソリューションはネタバレの下では削除されません)
SQLとリレーショナル代数の類似性を描く
2番目の解決策では、関係代数との明確な類似性が見られます。

結合に等式を使用して、最初のソリューションでのSQLと関係代数の類似性を確認します。

どんなに皮肉なことでも、SQLのSELECTはリレーショナル代数のプロジェクト(π;プロジェクション)です。
次に、集約に関する問題を検討し、それをリレーショナル代数のソリューションと比較します。

記事の後半でさらに興味深いタスクを検討し( ここでも小さな選択)、別のクエリ形式を検討します。
関係計算
気配りのある読者は今、叫ぶかもしれません:ヤギはボタンアコーディオンとは何ですか? ここにいるのは、クエリを記述するための2つの形式が十分ではないということです。
リレーショナル計算は、クエリを記述するための1次論理(FOL:1次論理)の適応です。 FOLは数学の最もよく研究された形式の1つであり、クエリの分析と記述にすでに作成された理論的な装置と古典的な結果を使用することを可能にします。
多くの場合、複雑さ、表現性、およびクエリの形成が論理からデータベースにもたらされます。これは、まさにリレーショナル計算のためです。したがって、この形式に慣れる価値があります。
関係計算を解析して話すには、 ここで更新できる1次論理が必要です 。
φ(X)を一次式、Xを自由変数、すなわち、それらは数量化されていません(∀は汎用数量詞、∃は存在数量詞です)ので、関係計算のクエリはセットを定義します:
{X | φ(X)}
形式を分析する簡単な例を考えてみましょう。
Rを3つの属性a、b、cを持つ関係とします。 次に、次のリレーショナル代数クエリを書き換えます。
 リレーショナル用語で:
リレーショナル用語で:
{ra、rb、rc | R®およびra = rc}
単純な言語に翻訳すると、rはRのタプルです(つまり、名前がドットで値を取得できる属性を持つ文字列です。つまり、raはR(テーブル)に対するタプルr(文字列)の属性です)。 ご覧のとおり、rはリクエストの出力にあり、フリーのタプルである必要があるため、ここには数量詞はありません。
別の簡単な例を考えてみましょう:R(a、b、c)∗ S(c、d、e)、ここで*は自然な結合、すなわち 名前で結合-結合条件と同じ名前の属性を取得します。
{rA、rB、rC、sD、sE | R®およびS(s)およびrC = sC}
sDとSeが出力パラメーターに含まれていない場合、リクエストは次の形式になります。
{rA、rB、rC | R®および∃s:S(s)およびrC = sC}
Sはリクエストの「ボディ」にのみ含まれているため、存在の量指定子を配置する必要があります。
そのようなクエリをコンパイルするとき、次の式を(もっぱら説明として)書く場合、普遍性の量指定子に常に注意する必要があります。
{rA | R®および∀s:S(s)およびrC = sCおよびsE = "banana"}
クエリ条件が満たされるためには、長さ3のワールドの各タプルがSに属し、最後の属性「banana」の値を持っている必要があるため、このクエリは常に空のセットを返します。
通常、含意「=>」は汎用数量詞と一緒に使用され、クエリを次のように書き換えることができます。
{rA | R®および∀s:(S(s)およびrC = sC)=> sE = "banana"}
sがSに属し、Cの値がRのCと一致する場合、最後の属性はbananaに設定する必要があります。
ここでは、解を含むリレーショナル計算の問題の簡単な選択を見つけることができます。
形式の平等(コッドの定理)
簡単に言えば、Coddの定理は次のように聞こえます。3つのSQL形式、関係代数、関係計算はすべて同等です。 ここに興味がある人のための多くの理論があります
つまり、ある言語で表現された要求は、別の言語で再定式化できます。 この結果は、クエリ分析に最も便利な形式を使用できるという点で主に便利です。次に、宣言型SQL言語と関係計算を命令関係代数に接続します。 つまり、クエリをSQLからリレーショナル代数に変換すると、クエリを実行(および最適化)する方法が既に得られています。
結合クエリ(CQ)
関係代数のselect(σ)-project(π)-join(⋈)セグメントで構成されるクエリは、結合クエリと呼ばれます(わかりました。名前の変更は省略し、暗黙的に存在すると見なします)。
この行まで読んだ場合、これら3つの演算子(もちろん、関係)のみを使用して、次の問題を解決してください。
チャレンジ。 各プロジェクトで働くすべての従業員の名前を印刷します。
このクラスのリレーショナル代数が属するSQLおよびリレーショナル計算のどのセグメントについて考えます。
計算の複雑さ
クエリの計算の複雑さを測定する方法はいくつかありますが、それらはしばしば混同されるため、定義とその名前を書きます。
Qをクエリ、Dをデータベース、Q(D)とする
- Qが固定されている場合、f(D)の計算の複雑さはデータの複雑さと呼ばれます
- Dが固定されている場合、f(Q)の計算の複雑さはクエリの複雑さと呼ばれます。
- 何も固定されていない場合、複雑度f(Q、D)は複合複雑度と呼ばれます
重要な事実: データ (およびその他すべて)に応じた SQLの複雑度はクラスAC0に属します-これは非常に優れた複雑度クラスです。つまり、クエリを非常に効率的に計算できます。
理論的な観点から、この写真を見ることができます:

AC0はNL内にあります(より正確には、NL内のNC「レイヤー」の1つ内にあります)。
計算の複雑さに関連する次の興味深い質問を考えてみましょう。fを式の充足可能性関数、つまり、クエリごとにQ(D)が真になるようなデータベースがあるかどうかを調べます。 Coddの定理から、関係代数とSQLは関係計算と同等であることがわかります。 これは、fの計算が停止問題に相当することを意味します(SATは1次論理では計算できません)。 したがって、任意のSQLクエリの一貫性を判断できるアルゴリズムはありません。
興味のある人には、以下をお勧めします: Trachtenbrotの定理
困難な連言クエリ
CQは、データベースクエリの大部分を構成するため、最もよく研究されているクエリクラスの1つです(1つのプレゼンテーションで90%の数値を見ましたが、今はソースを見つけることができません)。 したがって、それらの複雑さをより詳細に検討し、実際にそれらの複合された複雑さはNPに等しいことを証明します。 タスクはNP完了です。 ( こことここで NP全体を読むことができます 。)
これを行うには、リレーショナル計算で任意のCQクエリを次の形式で記述します。
{X | [∃X0:] p0(X0)および[∃X1:] p1(X1)および[∃X1:] p(X2)...}
ここで、[。]は数量詞のオプションです。 なぜこのような表現が常に有効なのですか? ここでのプロジェクトは常にXで表現できるためです。  、結合は変数の等式を通じて表現されます
、結合は変数の等式を通じて表現されます  、および上の条件を選択します リクエストの本文。
、および上の条件を選択します リクエストの本文。
問題がNP完全のクラスに属することを示すには、2つのことを行う必要があります
- NPクラス内のタスクを表示
- NP完全問題が所定の値に減少することを示す
最初の条件は簡単に満たされます。関係の値は有限であるため(つまり、あらゆる種類の可能な値のセット)、関数を非決定的に「推測」できます。  このように、存在の数量詞の下ですべての関係が真になります。
このように、存在の数量詞の下ですべての関係が真になります。
グラフの色の問題は、CQクエリの実行可能性の問題に帰着することを示します。
Dを1つの関係エッジで構成する= {(red、green)、(green、red)、(blue、red)、(green、blue)...}-2つの頂点が同じ色を持たないように、グラフの可能なすべての正しい色付け。
初期グラフはエッジのセットとして与えられます 
次に、次のクエリを書き留めます
{()| ∃X0...∃XN:エッジ(V1、V2)および...エッジ(V_i、V_j)...}
つまり、クエリのソースグラフの各アークは、対応する引数とのエッジ関係に対応します。 クエリが空のタプルを返した場合、そのような関数があることを意味します 表示する  、さらに、2つの頂点が同じ色を持つことはありません(Dの定義に従う)。 C.T.D.
、さらに、2つの頂点が同じ色を持つことはありません(Dの定義に従う)。 C.T.D.
アスタリスク付きの質問:select-project-joinセグメントからプロジェクトを除外します。計算の複雑さはどのように変わりますか?
推移閉包
データおよびクエリによる複雑さの定義は、1つのよく知られている結果にも光を当てます-古典的なSQL(withなし)では、固定クエリでは推移的閉包は表現できません。 データベースに対して述語閉包を計算するようなクエリを書くことはできません。 つまり、エッジ関係として保存されたグラフがある場合、任意のグラフの到達可能性関係を計算する固定クエリを記述できません。 直感的には、このような要求は明らかにCQクラスにあるはずです。
これは、「データによる」計算の複雑さから、またはより建設的かつ興味深いことに、コンパクト性定理とCoddの定理(SQL = First Order Logic)からわかります。
証明は自明ではなく、さらなる資料の理解を失うことなくスキップすることができます。
Gödel: 1次論理はコンパクトです。
Codd:SQL-一次ロジック
逆の証明として、T(a、b)をaからbへのパスとする。 P_n(a、b)は、長さnのaからbへのパスです。 次に〜P_n(a、b)-aから長さnのbへのパスはありません。
次の有限集合を取る{T(a、b)、〜P_1(a、b)、〜P_2(a、b)...〜P_k(a、b)}-それは実行可能です。なぜなら、長さk + 1とTのパスを取るからです(a、b)が満たされ、すべての〜P_1 ...〜P_kも満たされます。 さらに、この種の有限集合は充足可能であり、したがって、コンパクト性定理により、それらの無限結合も実現可能でなければなりません。
ただし、〜P_k-すべてのkに対してtrueでなければなりません。つまり、aからbまでの長さのパスが存在してはならず、T(a、b)が存在するには、そのようなパスが存在する必要があります。 論争。 QED
要求が修正されない場合、タスクは簡単に解決可能になります。 データベースにkエッジしかない、つまり最大パスが最大kであると仮定すると、クエリを長さ1、2、... kのパスのユニオンとして明示的に記述し、グラフの到達可能性を計算するクエリを取得できます。
クエリのプロパティと分析
さて、前に提案した問題に戻りましょう。
各プロジェクトで働くすべての従業員の名前を印刷します。
この問題がCQクラスで解決しない理由は、リクエスト自体とCQクラスの主要なプロパティを定義することで理解できます。
定義、Qクエリは、任意の2つのデータベースに対して、モノトーンと呼ばれます。  それは本当です
それは本当です  。 つまり、データベースの増加は、出力内のタプルの数を増やすか、そのままにすることができます。
。 つまり、データベースの増加は、出力内のタプルの数を増やすか、そのままにすることができます。
観察:CQは単調に増加するクエリのクラスです。 任意のCQクエリQを想像してください-select-project-joinで構成されています。 それぞれが単調演算子であることを示します。
Dに別のエントリを追加しましょう
select-レコードを垂直方向にフィルターします。新しいレコードが要求を満たす場合、回答のセットは増加し、そうでない場合は同じままです。
プロジェクト-追加のタプルには影響しません
join-対応するレコードが2番目のセットにもある場合、応答セットは拡張され、そうでない場合は同じままになります。
単調演算子の重ね合わせは単調です=> CQは単調クエリのクラスです。
質問:元の問題は単調ですか? そうでもない。 2人のプロジェクトAとBで作業している従業員Petyaが1人だけで、AとBのプロジェクトが2つしかないため、Petyaがリクエストを発行する必要があるとします。 3番目のプロジェクトC =>を追加し、Petyaが回答に含まれておらず、応答セットが空であると仮定します。これは、クエリが単調ではないことを意味します。
ここから次の質問が論理的に続きます:解決するタスクのためにselect-project-joinに追加する必要があるものは何ですか? これは非単調でなければなりません!
もちろん読者が推測したように、違いはセットです。 彼の非対称性は私たちを促し、最初から彼を際立たせたように見えました。
ただし、ソリューションを作成する前に、もう1つ観察します。ステートメントの反例が存在しない場合、このステートメントは常に真です。 正式に:
 -p(x)が偽であるようなxはありません。
-p(x)が偽であるようなxはありません。
タスクでは、明示的に「すべて」の数量詞を確認し、二重否定を使用してそれをエミュレートできます。つまり、次のようにクエリを言い換えます。 作業していないプロジェクトがないすべての従業員の名前を表示します
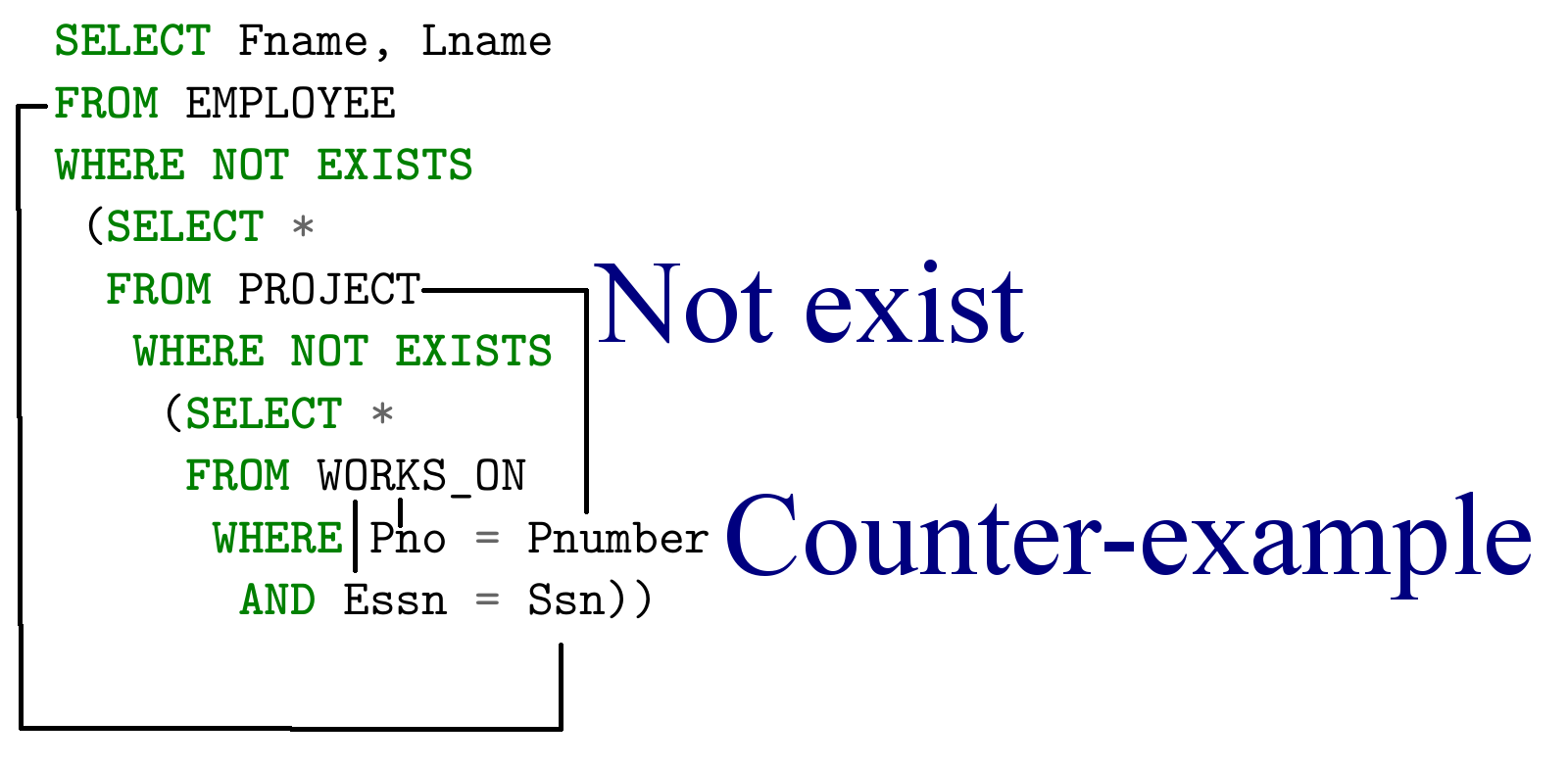
この同じリクエストは、信じられないほどシンプルに見えます  (そして、それはリレーショナル用語です):
(そして、それはリレーショナル用語です):
{e.fname、e.lname | EMP(e)および  PRJ(p)
PRJ(p)  WORKS_ON(w)およびw.Pno = p.Pnumberおよびe.Ssn = w.Essn}
WORKS_ON(w)およびw.Pno = p.Pnumberおよびe.Ssn = w.Essn}
クエリの最適化にRAを使用する例
また、SQLをリレーショナル代数に変換すると、クエリの実行を最適化できます。 簡単な例を考えてみましょう。
挑戦する
Schmidtという名前の従業員がこのプロジェクトを管理する部門のマネージャーとして働くすべてのプロジェクト番号を表示します。
簡単な解決策は次のとおりです。

これは、次のようにリレーショナル代数で書き直すことができます。
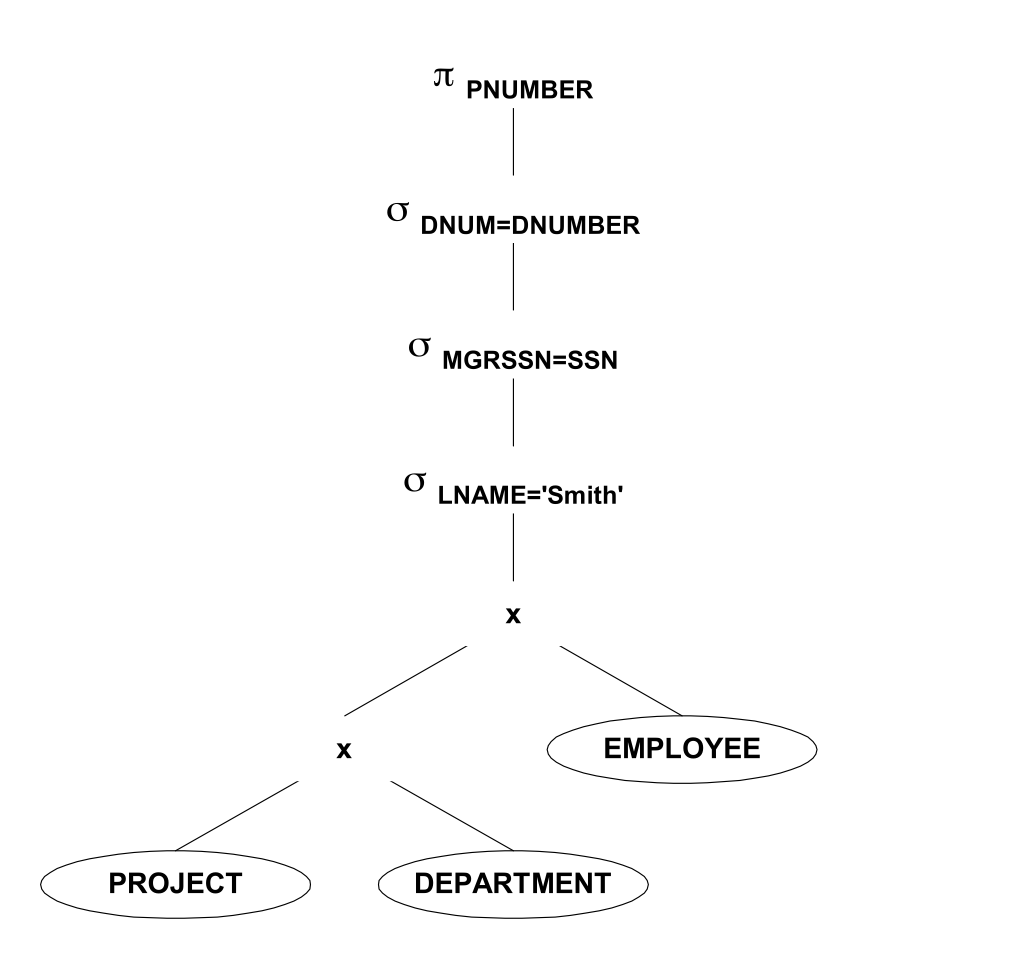
最初の最適化-できるだけ早くselectを使用する必要がある場合、デカルト積は入力でより小さな関係を受け取ります。

等式定数を使用した選択は強力な制約であるため、できるだけ早く計算して接続する必要があります。
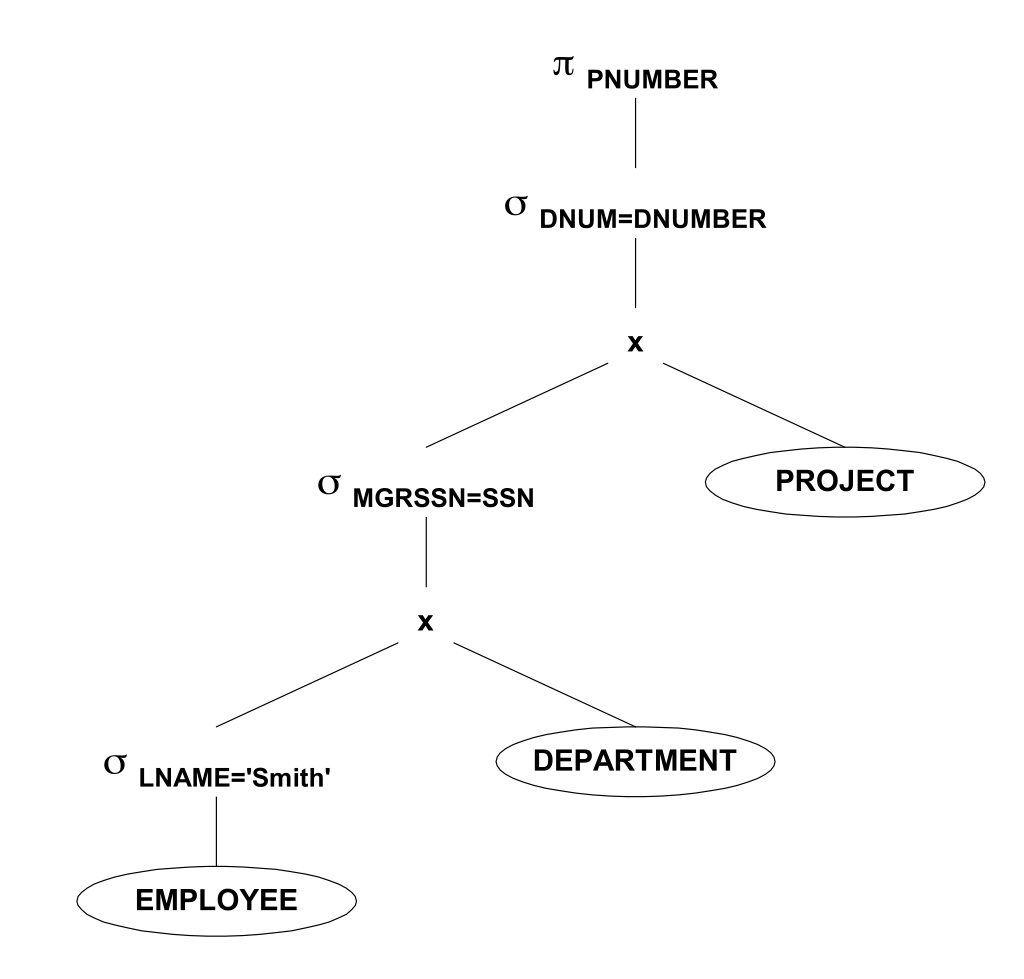
デカルト積をオフにして、結合で選択します(これは、インデックスと特殊なデータ構造で効率的に実装されます)
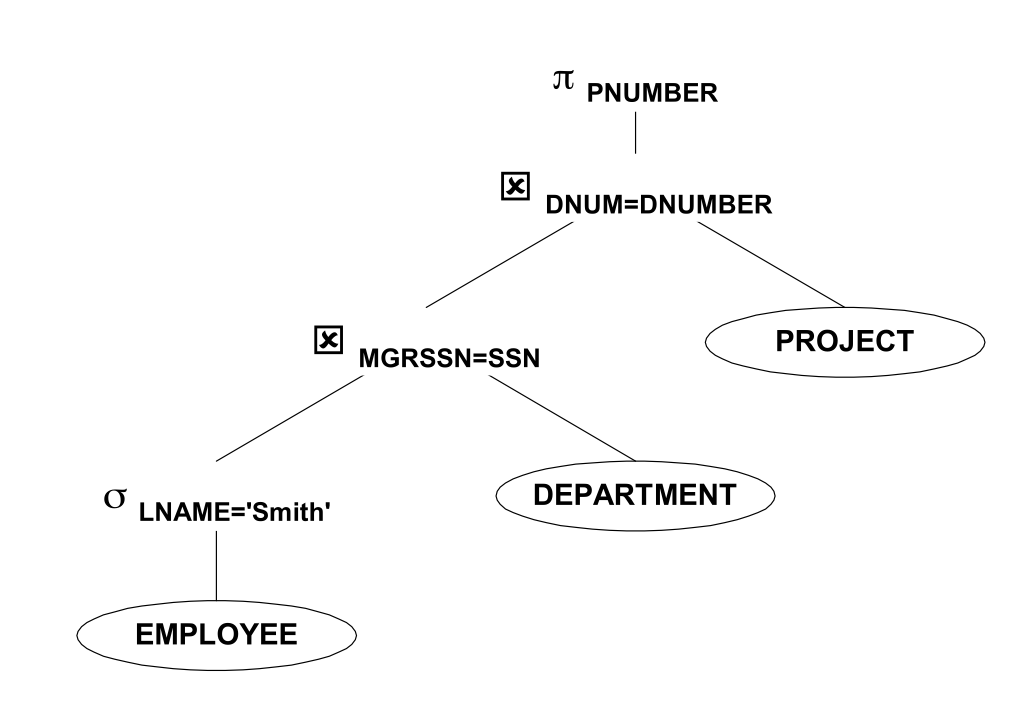
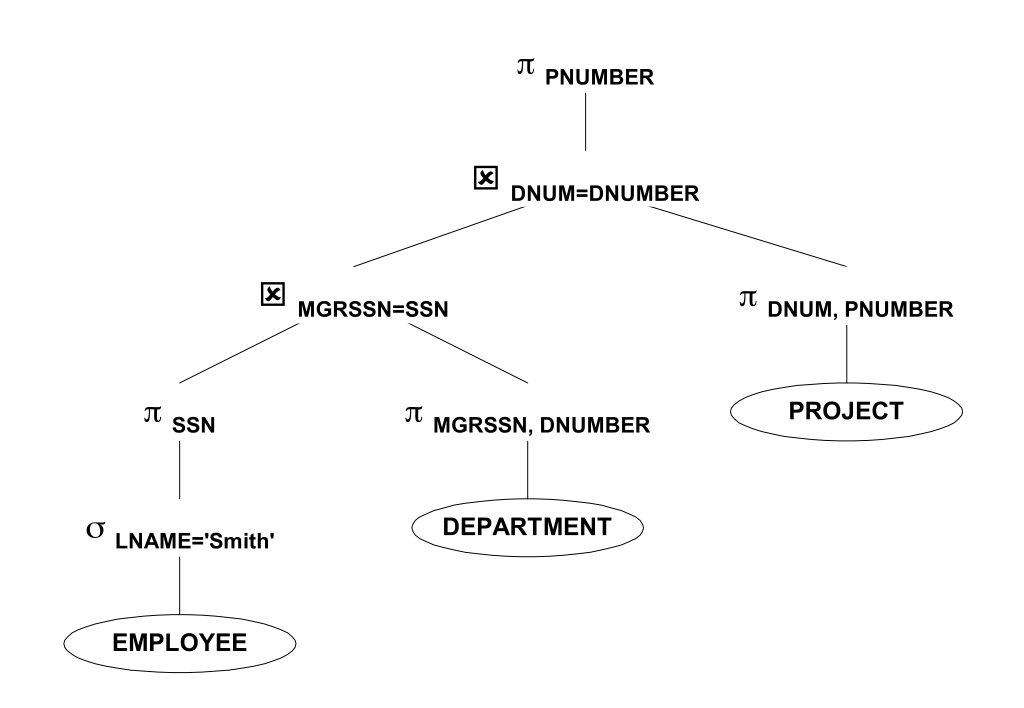
必要な情報だけがツリーに渡されるように、プロジェクトを可能な限り低くします
文学、資料、スライド
スタンフォードオンラインコース-ジェニファーウィドム -素晴らしいコース、お勧め
アリスの本-セルジュアビテブール -ジャンルの古典
Martin Graber-SQL -SQLアルゴリズムと構文がどのように機能するかについてのかなりシンプルで詳細な説明
トピックに関する私のスライド(さまざまな形式の問題を解決する例があるため、非常に役立ちます-オランダ語と英語が混在する場合があります)
良い理論のスライド(重要な理論的資料)