 実際に最もよく使用される集計関数は、 COUNT 、 SUM、およびAVGの 3つです。
実際に最もよく使用される集計関数は、 COUNT 、 SUM、およびAVGの 3つです。
そして、最初のものがすでに議論されている場合、残りの部分にはパフォーマンスに興味深いニュアンスがあります。 しかし、すべてについて順番に話しましょう...
実行計画で集計関数を使用する場合、入力ストリームに応じて、 Stream AggregateとHash Matchの 2つの演算子が発生する場合があります。
最初のものを実行するには、事前に並べ替えられた値の入力セットが必要な場合がありますが、 Stream Aggregateは後続のステートメントの実行をブロックしません。
Hash Matchは、ブロッキング演算子であり(まれな例外を除きます )、入力ストリームの並べ替えを必要としません。 Hash Matchの作業では、メモリ内に作成されるハッシュテーブルが使用されます 。予想される行数が正しく推定されない場合、オペレーターは結果をtempdbにマージできます 。
したがって、 Stream Aggregateは小さなソート済みデータセットでうまく機能し、 Hash Matchはソートされていない大きなデータセットでうまく機能し、並列処理に適していることがわかりました。
理論を克服したので、集計関数がどのように機能するかを調べ始めます。
すべての製品の平均価格を計算する必要があるとします:
SELECT AVG(Price) FROM dbo.Price
かなり単純な構造の表によると:
CREATE TABLE dbo.Price ( ProductID INT PRIMARY KEY, LastUpdate DATE NOT NULL, Price SMALLMONEY NULL, Qty INT )
スカラー集約があるため、実行計画ではStream Aggregateが表示されることが期待されます。

内部的に、この演算子はPrice列で2つの集計操作COUNT_BIGおよびSUMを実行します(ただし、物理レベルでは単一の操作として実行されます)。
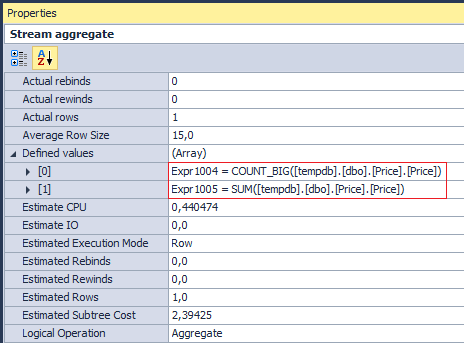
操作COUNT_BIGはアスタリスクではなく列に沿って進むため、平均はNOT NULLについてのみ計算されることを忘れないでください。 したがって、このような要求:
SELECT AVG(v) FROM ( VALUES (3), (9), (NULL) ) t(v)
結果として4ではなく6を返します。
では、 Compute Scalarを見てみましょう。その中には、ゼロによる除算をチェックするための興味深い式があります。
Expr1003 = CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005]/CONVERT_IMPLICIT(money,[Expr1004],0) END
合計金額を計算してみましょう。
SELECT SUM(Price) FROM dbo.Price
実装計画は同じままです。

しかし、 Stream Aggregateが実行する操作を見ると...
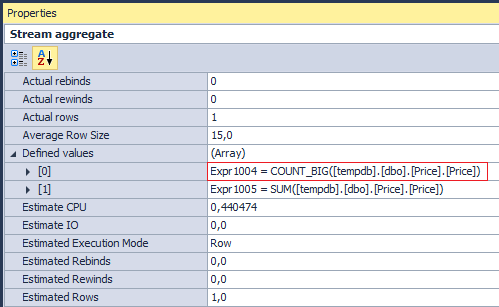
あなたは少し驚くかもしれません。 金額だけが必要な場合、 SQL Serverが金額をカウントするのはなぜですか? 答えはCompute Scalarにあります:
[Expr1003] = Scalar Operator(CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005] END)
COUNTを考慮しない場合、 T-SQL言語のセマンティクスに従って、入力ストリームに行がない場合、 0ではなくNULLを返す必要があります 。 この動作は、スカラーとベクトルの両方の集計に対して機能します。
SELECT LastUpdate, SUM(Price) FROM dbo.Price GROUP BY LastUpdate OPTION(MAXDOP 1)
Expr1003 = Scalar Operator(CASE WHEN [Expr1008]=(0) THEN NULL ELSE [Expr1009] END)
さらに、このようなチェックは、 NULL列とNOT NULL列の両方に対して実行されます。 次に、上記のSUMおよびAVGの機能が役立つ例を見てみましょう。
平均を計算する場合、 COUNT + SUMを使用する必要はありません。
SELECT SUM(Price) / COUNT(Price) FROM dbo.Price
そのような要求はAVGの明示的な使用よりも効率が悪いためです。
さらに...集計関数に明示的にNULLを渡す必要はありません。
SELECT SUM(CASE WHEN Price < 100 THEN Qty ELSE NULL END), SUM(CASE WHEN Price > 100 THEN Qty ELSE NULL END) FROM dbo.Price
この設計では:
SELECT SUM(CASE WHEN Price < 100 THEN Qty END), SUM(CASE WHEN Price > 100 THEN Qty END) FROM dbo.Price
オプティマイザーは置換を自動的に実行します。
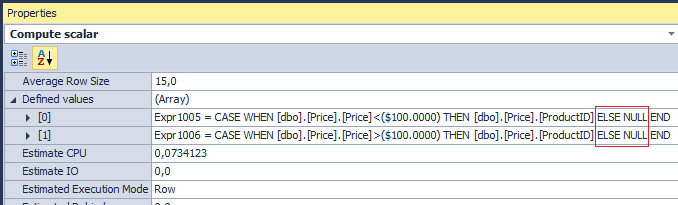
しかし、結果にNULLではなく0を取得したい場合はどうすればよいですか? 非常に多くの場合、彼らはELSEを使用し、考えていません:
SELECT SUM(CASE WHEN Price < 100 THEN Qty ELSE 0 END), SUM(CASE WHEN Price > 100 THEN Qty ELSE 0 END) FROM dbo.Price
明らかに、この場合、私たちは目的を達成します...そして、1つの警告でさえ目障りではなくなります:
Warning: Null value is eliminated by an aggregate or other SET operation.
次のようなクエリを記述するのが最善ですが:
SELECT ISNULL(SUM(CASE WHEN Price < 100 THEN Qty END), 0), ISNULL(SUM(CASE WHEN Price > 100 THEN Qty END), 0) FROM dbo.Price
CASEステートメントが高速になるため、これは良くありません。 オプティマイザがELSE NULLを自動的に置換することは既にわかっています...では、後者のオプションの利点は何ですか?
結局のところ、 NULL値が優先される集計操作はより高速に処理されます。
SET STATISTICS TIME ON DECLARE @i INT = NULL ;WITH E1(N) AS ( SELECT * FROM ( VALUES (@i),(@i),(@i),(@i),(@i), (@i),(@i),(@i),(@i),(@i) ) t(N) ), E2(N) AS (SELECT @i FROM E1 a, E1 b), E4(N) AS (SELECT @i FROM E2 a, E2 b), E8(N) AS (SELECT @i FROM E4 a, E4 b) SELECT SUM(N) -- 100.000.000 FROM E8 OPTION (MAXDOP 1)
処刑には私がかかりました:
SQL Server Execution Times: CPU time = 5985 ms, elapsed time = 5989 ms.
今変更:
DECLARE @i INT = 0
そしてもう一度やります:
SQL Server Execution Times: CPU time = 6437 ms, elapsed time = 6451 ms.
それほど重要ではありませんが、それでも特定の状況で最適化の機会を与えます。
演劇の終わりとカーテン? いや それだけではありません...
私の友人の一人が言ったように、 「黒も白もありません...世界は多色」です。したがって、最後に、 NULLが有害な場合の興味深い例を示します 。
遅い関数とテストパターンを作成します。
USE tempdb GO IF OBJECT_ID('dbo.udf') IS NOT NULL DROP FUNCTION dbo.udf GO CREATE FUNCTION dbo.udf (@a INT) RETURNS VARCHAR(MAX) AS BEGIN DECLARE @i INT = 1000 WHILE @i > 0 SET @i -= 1 RETURN REPLICATE('A', @a) END GO IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL DROP TABLE #temp GO ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b) SELECT * INTO #temp FROM E4
そして、リクエストを実行します:
SET STATISTICS TIME ON SELECT SUM(LEN(dbo.udf(N))) FROM #temp
SQL Server Execution Times: CPU time = 9109 ms, elapsed time = 11603 ms.
次に、 SUMに渡される式の結果を試して、 ISNULLでラップします。
SELECT SUM(ISNULL(LEN(dbo.udf(N)), 0)) FROM #temp
SQL Server Execution Times: CPU time = 4562 ms, elapsed time = 5719 ms.
実行速度が2倍に低下しました。 これは魔法ではないことをすぐに言わなければなりません...しかし、 MicrosoftがSQL Server 2012 CTPで既に修正した SQL Server エンジンのバグ 。
問題の本質は次のとおりです。オプティマイザーがNULLを返すと見なす場合、 SUMまたはAVG関数内の式の結果を2回実行できます 。
すべてがMicrosoft SQL Server 2012(SP3)(KB3072779)-11.0.6020.0(X64)でテストされました。
この記事を英語圏の聴衆と共有したい場合:
SUM&AVG内で高速なものは何ですか:0またはNULL?