ランダム変数のモデリングによる数学的問題。 メソッドの歴史のアイデアとそのアプリケーションの最も簡単な例は、 ウィキペディアで見つけることができます。
メソッド自体に複雑なものはありません。 この方法の人気を説明するのはこの単純さです。
このメソッドには2つの主な機能があります。 1つ目は、計算アルゴリズムの単純な構造です。 2番目-計算誤差は通常比例します
ただし、同じ問題は異なる値に対応する異なるバージョンのモンテカルロ法で解決できます
メソッドの一般的なスキーム
未知の数量mを計算する必要があるとします。 このようなランダム変数を考えてみましょう
検討する
中央極限定理に基づいて(または、Muavre-Laplace極限定理が必要な場合)、関係を取得することは難しくありません。
どこで
これは、モンテカルロ法にとって非常に重要な関係です。 また、計算方法も示します。
実際、私たちは見つけます
目標に応じて、最後の比率はさまざまな方法で使用されます。
- k = 3をとると、いわゆる「ルール
」:
- 特定のレベルの計算の信頼性が必要な場合
、
計算精度
上記の関係からわかるように、計算の精度はパラメーターに依存します
この段落では、2番目のパラメーターの重要性を示したい
特定の積分の計算は面積の計算に相当し、積分を計算するための直感的なアルゴリズムを提供します(Wikipediaの記事を参照)。 より効果的な方法を検討します(ただし、Wikipediaの記事にも記載されている式の特殊なケース)。 ただし、一様に分布した確率変数の代わりに、同じ間隔で与えられたほぼすべての確率変数をこの方法で使用できることを誰もが知っているわけではありません。
したがって、特定の積分を計算する必要があります。
任意のランダム変数を選択してください
最後のランダム変数の数学的期待値は次のとおりです。
したがって、以下を取得します。
最後の関係は、選択した場合
。
したがって、積分を計算するには、ほぼすべてのランダム変数を使用できます
それを示すことができます
数値例
理論はもちろん良いことですが、数値の例を見てみましょう。
2つの異なるランダム変数を使用して積分値を計算します。
最初のケースでは、[a、b]に一様に分布したランダム変数を使用します。つまり、
2番目のケースでは、[a、b]に線形密度を持つランダム変数を取ります。つまり、
以下は指定された関数のグラフです
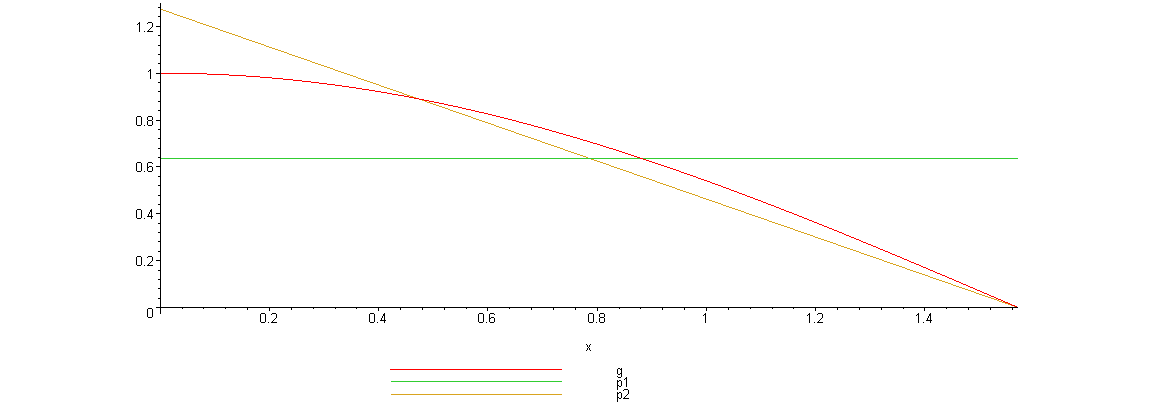
線形密度が関数によりよく対応していることが簡単にわかります
Maple数学パッケージのモデルコードプログラムコード
このプログラムのファイルはここで取得できます
restart; with(Statistics): with(plots): # g:=x->cos(x): a:=0: b:=Pi/2: N:=10000: # p1:=x->piecewise(x>=a and x<b,1/(ba)): p2:=x->piecewise(x>=a and x<b,4/Pi-8*x/Pi^2): # plot([g(x),p1(x),p2(x)],x=a..b, legend=[g,p1,p2]); # I_ab:=int(g(x),x=0..b); # - # INT:=proc(g,p,N) local xi; xi:=Sample(RandomVariable(Distribution(PDF = p)),N); evalf(add(g(xi[i])/p(xi[i]),i=1..N)/N); end proc: # I_p1:=INT(g,p1,N);#c I_p2:=INT(g,p2,N);#c # Delta1:=abs(I_p1-I_ab);#c Delta2:=abs(I_p2-I_ab);#c # delta1:=Delta1/I_ab*100;#c delta2:=Delta2/I_ab*100;#c # Dzeta1:=evalf(int(g(x)^2/p1(x),x=a..b)-1); Dzeta2:=evalf(int(g(x)^2/p2(x),x=a..b)-1); # 3*sqrt(Dzeta1)/sqrt(N); # 3*sqrt(Dzeta2)/sqrt(N);
このプログラムのファイルはここで取得できます
積分の正確な値は分析的に簡単に計算でき、1に等しくなります。
での1つのシミュレーションの結果
一様分布のランダム変数の場合:
線形分布密度のランダム変数の場合:
前者の場合、相対誤差は21%を超え、後者の場合は2.35%です。 精度
このモデルの例は、モンテカルロ法でランダム変数を選択することの重要性を示していると思います。 正しいランダム変数を選択すると、少ない反復回数で計算の精度を高めることができます。
もちろん、1次元積分はこの方法では計算されません;これには、より正確な求積式があります。 しかし、状況は多次元積分への移行によって変わります。なぜなら、 求積式は面倒で複雑になり、モンテカルロ法はわずかな変更のみで適用されます。
反復回数と乱数ジェネレーター
計算の精度が数量に依存することを確認するのは難しくありません
いくつかの問題を解決するとき、許容可能な推定精度を得るために、非常に多数の
何らかの物理現象(物理乱数センサー)がランダム性の原因として使用される場合、すべてが正常に機能します。
多くの場合、擬似乱数センサーはモンテカルロ計算に使用されます。 そのような発電機の主な特徴は、特定の期間の存在です。
モンテカルロ法は値とともに使用できます
大規模な計算を行うときは、乱数ジェネレーターのプロパティでこれらの計算を実行できることを確認する必要があります。 標準的な乱数ジェネレーター(ほとんどのプログラミング言語)では、ほとんどの場合、オペレーティングシステムの処理能力が2を超えず、それ以下です。 このようなジェネレーターを使用する場合、非常に注意する必要があります。 D. Knutの推奨事項を調べて、独自のジェネレーターを構築することをお勧めします。ジェネレーターは、事前に十分に知られた十分に長い期間があります。
文学
1968年の数学に関する一般的な講義。第46号。SobolI.M. モンテカルロ法。 M。:Nauka、1968 .-- 64 p。