現在、膨大な数のタスクには高いシステムパフォーマンスが必要です。 物理的な制限により、プロセッサチップ上のトランジスタの数を無限に増やすことはできません。 トランジスタの幾何学的寸法を物理的に縮小することはできません。許容可能なサイズを超えると、大きなサイズのアクティブエレメントでは目立たない現象が現れ始めるため、量子サイズ効果が強く影響し始めます。 トランジスタはトランジスタのように機能し始めません。
ムーアの法則はそれとは何の関係もありません。 これは価値の法則であり、現在も変わらず、チップ上のトランジスタ数の増加は法の結果である可能性が高いです。 したがって、コンピューターシステムの能力を高めるには、他の方法を探す必要があります。 これは、マルチプロセッサ、マルチコンピュータの使用です。 このアプローチは、多数のプロセッサ要素によって特徴付けられ、各コンピューティングデバイス上でサブタスクを独立して実行します。
並列処理方法:
| 並行性のソース | 加速 | プログラマーの努力 | 人気度 |
|---|---|---|---|
| 多くのコア | 2x-128x | 中程度 | 高い |
| 多くの車 | 1x Infinity | やや高い | 高い |
| ベクトル化 | 2x-8x | 中程度 | 低い |
| グラフィックスアダプター | 128x-2048x | 高い | 低い |
| コプロセッサー | 40x-80x | やや高い | 非常に低い |
システムの効率を向上させる方法はたくさんありますが、どれもまったく違います。 そのような方法の1つは、ベクトルプロセッサの使用です。これにより、計算速度が大幅に向上します。 命令ごとに1つのデータ要素(SISD)を処理するスカラープロセッサとは異なり、ベクトルプロセッサは命令ごとに複数のデータ要素(SIMD)を処理できます。 最新のプロセッサのほとんどはスカラーです。 しかし、彼らが解決するタスクの多くは、ビデオ、サウンド処理、グラフィックス、科学計算など、大量の計算を必要とします。 計算プロセスを高速化するために、プロセッサメーカーは、追加のストリーミングSIMD拡張機能をデバイスに統合し始めました。
したがって、特定のプログラミング手法により、プロセッサでデータのベクトル処理を使用できるようになりました。 既存の拡張機能:MMX、SSE、およびAVX。 追加のプロセッサ機能を使用して、大規模なデータ配列の処理を高速化できます。 同時に、ベクトル化により、明らかな並列処理なしで高速化が可能になります。 つまり データ処理の観点からは存在しますが、プログラマーの観点からは、競合または同期状態を防ぐための特別なアルゴリズムの開発に費用を必要とせず、開発スタイルは同期と変わりません。 あまり手間をかけずに加速し、ほぼ完全に無料です。 それに魔法はありません。
SSEとは何ですか?
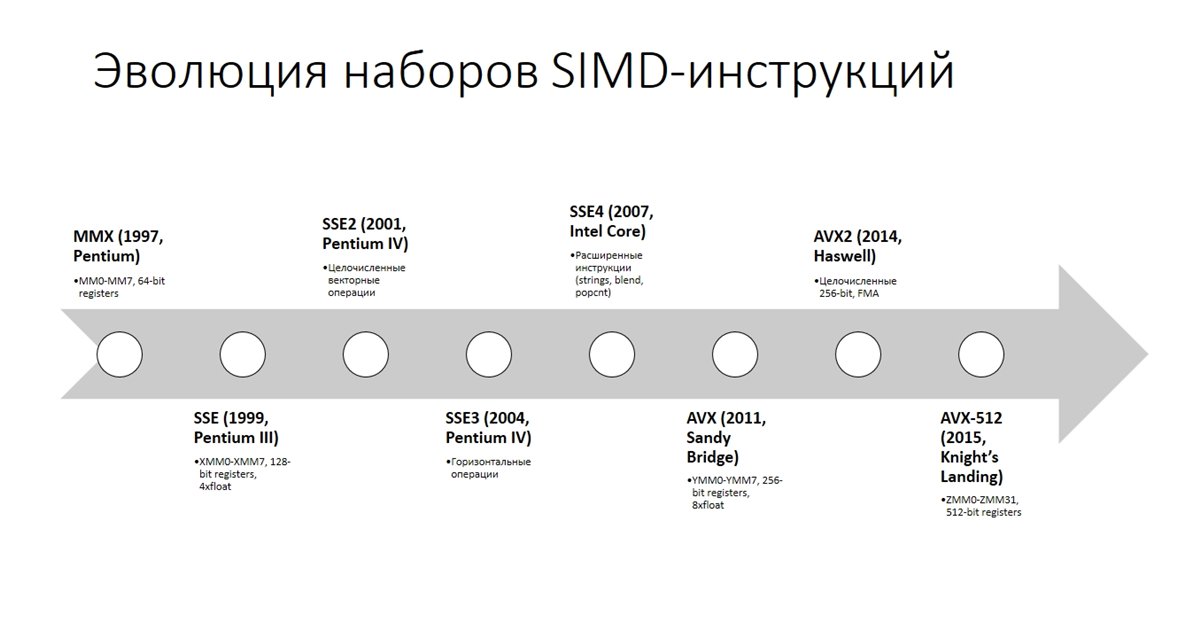
SSE(Eng。Streaming SIMD Extensions、ストリーミングSIMD-extension of processor)は、SIMD(Eng。Single Instruction、Multiple Data、One instruction-lot of data)の命令セットです。 SSEには、プロセッサアーキテクチャに8つの128ビットレジスタと命令セットが含まれています。 SSEテクノロジーは、1999年にPentium IIIで初めて導入されました。 時間が経つにつれて、この命令セットはより複雑な操作を追加することにより改善されました。 8つの(x86-64では-16)128ビットレジスタがプロセッサに追加されました:xmm0からxmm7。

当初、これらのレジスタは単精度計算(つまり、float型)にのみ使用できました。 ただし、SSE2のリリース後、これらのレジスタは任意のプリミティブデータ型に使用できます。 このように標準の32ビットマシンを使用すると、並行して格納および処理できます。
- 2ダブル
- 長い2
- 4フロート
- 4 int
- ショート8
- 16文字
AVXテクノロジーを使用する場合は、すでに256ビットのレジスタをそれぞれ1つの命令でより多く操作することになります。 したがって、すでに512ビットのレジスタがあります。
まず、C ++を例として(興味のない人はスキップできます)、float型の8要素の2つの配列を合計するプログラムを作成します。
C ++ベクトル化の例
C ++のSSEテクノロジーは、アセンブリ命令を反映する擬似コードの形式で提示される低レベルの命令によって実装されます。 したがって、たとえば、コマンド__m128 _mm_add_ps(__ m128 a、__m128 b); アセンブラー命令ADDPS operand1、operand2に変換されます 。 したがって、コマンド__m128 _mm_add_ss(__ m128 a、__ m128 b); ADDSS命令operand1、operand2に変換されます 。 これらの2つのコマンドはほぼ同じことを行います。配列の要素を合計しますが、わずかに異なる方法です。 _mm_add_psは完全にレジスタケースであるため、次のようになります。
- r0:= a0 + b0
- r1:= a1 + b1
- r2:= a2 + b2
- r3:= a3 + b3
さらに、レジスタ__m128全体がセットr0-r3です。 ただし、 _mm_add_ssコマンドはレジスタの一部のみを加算するため、次のようになります。
- r0:= a0 + b0
- r1:= a1
- r2:= a2
- r3:= a3
他のコマンドは、減算、除算、平方根、最小、最大、その他の演算など、同じ原理で配置されます。
プログラムを作成するには、フロートの__m128、ダブルの__m128d、int、short、charの__m128iなどの128ビットレジスタを操作できます。 同時に、__ m128型の配列は使用できませんが、__ m128 *型へのfloat配列の指定されたポインターを使用できます。
この場合、いくつかの労働条件を考慮する必要があります。
- __m128オブジェクトにロードおよび保存されるフロートデータは、16バイトのアライメントが必要です
- 一部の組み込み関数は、命令の性質上、引数が整数定数型である必要があります
- 2つのNAN引数に作用する算術演算の結果は定義されていません
理論へのそのような小さな余談。 ただし、SSEを使用したサンプルプログラムを検討してください。
#include "iostream" #include "xmmintrin.h" int main() { const auto N = 8; alignas(16) float a[] = { 41982.0, 81.5091, 3.14, 42.666, 54776.45, 342.4556, 6756.2344, 4563.789 }; alignas(16) float b[] = { 85989.111, 156.5091, 3.14, 42.666, 1006.45, 9999.4546, 0.2344, 7893.789 }; __m128* a_simd = reinterpret_cast<__m128*>(a); __m128* b_simd = reinterpret_cast<__m128*>(b); auto size = sizeof(float); void *ptr = _aligned_malloc(N * size, 32); float* c = reinterpret_cast<float*>(ptr); for (size_t i = 0; i < N/2; i++, a_simd++, b_simd++, c += 4) _mm_store_ps(c, _mm_add_ps(*a_simd, *b_simd)); c -= N; std::cout.precision(10); for (size_t i = 0; i < N; i++) std::cout << c[i] << std::endl; _aligned_free(ptr); system("PAUSE"); return 0; }
- alignas(#)は、変数とユーザータイプのカスタムアラインメントを設定する標準C ++ポータブル方法です。 C ++ 11で使用され、Visual Studio 2015でサポートされています。別のオプション__declspec(align(#))declaratorを使用できます。 静的メモリ割り当て中のアライメント用のデータ管理ツール。 動的選択でのアライメントが必要な場合は、 void * _aligned_malloc(size_tサイズ、size_tアライメント)を使用します。
- 次に、reinterpret_castを使用して、配列aおよびbへのポインターを_m128 *型に変換します。これにより、ポインターを他の型のポインターに変換できます。
- その後、前述の関数を使用して、アライメント済みメモリを動的に割り当てます_aligned_malloc(N * sizeof(float)、16);
- 型の次元を考慮して、要素の数に基づいて必要なバイト数を選択します。16は2のべき乗のアライメント値です。 そして、このメモリへのポインタは別のタイプのポインタに縮小されるため、float型の次元を配列として考慮して作業することができます。
したがって、SSE作業の準備はすべて完了しました。 さらにループでは、配列の要素をまとめます。 このアプローチは、ポインター演算に基づいています。 a_simd 、 b_simd 、およびcはポインターであるため、これらを増やすと、メモリーからsizeof(T)だけオフセットされます。 たとえば、動的配列cを使用すると、 c [0]と* cは同じ値を表示します。 cは配列の最初の要素を指します。 インクリメントcにより、ポインターは4バイト前方にシフトし、ポインターは配列の2つの要素を指すようになります。 したがって、ポインタを増減することで、配列を前後に移動できます。 しかし、同時に、配列の次元を考慮する必要があります。なぜなら、その境界を越えて他の誰かの記憶に向かうのは簡単だからです。 a_simdポインターとb_simdポインターの動作は似ています。ポインターをインクリメントするだけで128ビットの進みが発生し、float型の観点からは、配列aとbの4つの変数はスキップされます。 原則として、ポインターa_simdおよびaは 、それぞれb_simdおよびbと同様に、ポインターのタイプの次元を考慮して異なる方法で処理されることを除いて、メモリー内の1つのセクションを指します。

for (int i = 0; i < N/2; i++, a_simd++, b_simd++, c += 4) _mm_store_ps(c, _mm_add_ps(*a_simd, *b_simd));
これで、このループにこのようなポインターの変更がある理由が明らかになりました。 サイクルの各反復で、4つの要素が追加され、結果がレジスタxmm0(このプログラムの場合)からポインタcのアドレスに保存されます。 つまり このアプローチでは、ソースデータは変更されませんが、レジスタに金額が保存され、必要に応じて必要なオペランドに転送されます。 これにより、オペランドを再利用する必要がある場合に、プログラムのパフォーマンスを向上させることができます。
アセンブラーが_mm_add_psメソッド用に生成するコードを検討してください。
mov eax,dword ptr [b_simd] ;// b_simd eax( , ) mov ecx,dword ptr [a_simd] ;// a_simd ecx movups xmm0,xmmword ptr [ecx] ;// 4 ecx xmm0; xmm0 = {a[i], a[i+1], a[i+2], a[i+3]} addps xmm0,xmmword ptr [eax] ;// : xmm0 = xmm0 + b_simd ;// xmm0[0] = xmm[0] + b_simd[0] ;// xmm0[1] = xmm[1] + b_simd[1] ;// xmm0[2] = xmm[2] + b_simd[2] ;// xmm0[3] = xmm[3] + b_simd[3] movaps xmmword ptr [ebp-190h],xmm0 ;// movaps xmm0,xmmword ptr [ebp-190h] ;// mov edx,dword ptr [c] ;// ecx movaps xmmword ptr [edx],xmm0 ;// ecx , (ecx) . xmmword , _m128 - 128- , 4
コードからわかるように、1つのaddps命令が4つの変数を一度に処理します。これは、ハードウェアプロセッサによって実装およびサポートされています。 システムはこれらの変数の処理に関与しないため、不必要な外部コストをかけずにパフォーマンスが向上します。
この場合、この例ではコンパイラがmovups命令を使用するという1つの機能に注目したいと思います。この命令は、16バイト境界に整列する必要のあるオペランドを必要としません。 そこから、配列aを整列できませんでした 。 ただし、配列bは位置合わせする必要があります。そうしないと、128ビットのメモリ位置でレジスタが追加されるため、 addps操作でメモリの読み取りに失敗します。 別のコンパイラまたは環境には他の命令が存在する場合があるため、このような操作に関係するすべてのオペランドが境界整列を行う方が適切です。 いずれにしても、メモリの問題を回避するため。
位置合わせを行うもう1つの理由は、配列の要素を操作するとき(および要素だけでなく)、64バイトのサイズのキャッシュラインを常に操作するときです。 SSEおよびAVXベクトルは、それぞれ16バイトおよび32バイトで位置合わせされている場合、常に同じキャッシュラインに分類されます。 しかし、データが整列されていない場合は、別の「追加の」キャッシュラインをロードする必要があります。 このプロセスはパフォーマンスに重大な影響を与えます。アレイの要素、したがってメモリを一貫性なく扱う場合、すべてがさらに悪化する可能性があります。
.NETでのSIMDサポート
SIMDテクノロジーに対するJITサポートの最初の言及は、2014年4月に.NETブログで発表されました。 その後、開発者は、SIMD機能を提供するRyuJITの新しいプレビューバージョンを発表しました。 追加の理由は、C#とSIMDのサポートリクエストの人気がかなり高かったことです。 サポートされているタイプの初期セットは大きくなく、機能に制限がありました。 最初は、SSEセットがサポートされ、AVXがリリースに追加されることが約束されました。 その後の更新がリリースされ、SIMDをサポートする新しいタイプとそれらを操作する新しい方法が追加されました。最近のバージョンでは、ハードウェアデータ処理用の広範で便利なライブラリを表します。

このアプローチにより、CPU依存のコードを記述する必要のない開発者の作業が楽になります。 代わりに、CLRは、実行時(JIT)またはインストール中(NGEN)にコードをマシン命令に変換する仮想ランタイムを提供することにより、ハードウェアを抽象化します。 CLRコード生成を終了すると、この特定のCPUに固有の最適化をあきらめることなく、異なるプロセッサを搭載した異なるコンピューターで同じMSILコードを使用できます。
現在、.NETでのこのテクノロジーのサポートはSystem.Numerics.Vectors名前空間で表され、SIMDハードウェアアクセラレーションを利用できるベクタータイプのライブラリです。 ハードウェアアクセラレーションは、数学プログラミングや科学プログラミング、およびグラフィックプログラミングの生産性の大幅な向上につながります。 次のタイプが含まれます。
- 写真素材-普遍的なベクトルを操作するための静的な便利なメソッドのコレクション
- Matrix3x2-3x2マトリックスを表します
- Matrix4x4-4x4マトリックスを表します
- 平面-3次元の平面を表します
- クォータニオン-3次元の物理的な回転をエンコードするために使用されるベクトルを表します
- Vector <(Of <(<'T>)>)>は、並列アルゴリズムの低レベルの最適化に適した指定された数値型のベクトルを表します
- Vector2-2つの単精度浮動小数点値を持つベクトルを表します
- Vector3-3つの単精度浮動小数点値を持つベクトルを表します
- Vector4-4つの単精度浮動小数点値を持つベクトルを表します
Vectorクラスは、ベクトルの最小値と最大値、および他の多くの変換を追加、比較、検索するためのメソッドを提供します。 同時に、操作はSIMDテクノロジーを使用して動作します。 他のタイプもハードウェアアクセラレーションをサポートしており、特定の変換が含まれています。 行列の場合、これはベクトルの場合、ポイント間のユークリッド距離などの乗算になります。
C#プログラムの例
それでは、このテクノロジーを使用するには何が必要ですか? 最初にRyuJITコンパイラと.NETバージョン4.6が必要です。 バージョンが低い場合、NuGetを介したSystem.Numerics.Vectorsはインストールされません。 ただし、ライブラリがインストールされていても、バージョンをダウングレードすると、すべてが正常に機能しました。 次に、x64向けにビルドする必要があります。そのためには、プロジェクトプロパティの「32ビットプラットフォームを優先」を削除する必要があり、任意のCPUでビルドできます。
リスト:
using System; using System.Numerics; class Program { static void Main(string[] args) { const Int32 N = 8; Single[] a = { 41982.0F, 81.5091F, 3.14F, 42.666F, 54776.45F, 342.4556F, 6756.2344F, 4563.789F }; Single[] b = { 85989.111F, 156.5091F, 3.14F, 42.666F, 1006.45F, 9999.4546F, 0.2344F, 7893.789F }; Single[] c = new Single[N]; for (int i = 0; i < N; i += Vector<Single>.Count) // Count 16 char, 4 float, 2 double .. { var aSimd = new Vector<Single>(a, i); // i var bSimd = new Vector<Single>(b, i); Vector<Single> cSimd = aSimd + bSimd; // Vector<Single> c_simd = Vector.Add(b_simd, a_simd); cSimd.CopyTo(c, i); // } for (int i = 0; i < a.Length; i++) { Console.WriteLine(c[i]); } Console.ReadKey(); } }
一般的な観点から、.NETのC ++アプローチはかなり似ています。 ソースデータを変換/コピーし、最終配列にコピーする必要があります。 ただし、C#を使用したアプローチははるかに単純であり、多くのことがあなたのために行われ、使用して楽しむだけで済みます。 データのアライメントについて考え、メモリを割り当て、特定の演算子で静的または動的に行う必要はありません。 一方、ポインターを使用して何が起こっているかをより詳細に制御できますが、何が起こっているのかについても責任があります。
そして、ループではすべてがC ++のループと同じように起こります。 そして、私はポインターについて話していません。 計算アルゴリズムは同じです。 最初の反復で、ソース配列の最初の4つの要素をaSimd構造とbSimd構造に入力し、合計して最終配列に格納します。 次に、次の反復で、オフセットを使用して次の4つの要素を入力し、それらを合計します。 それはそれが迅速かつ簡単に行われる方法です。 コンパイラーがこのコマンドvar cSimd = aSimd + bSimdに対して生成するコードを検討してください。
addps xmm0,xmm1
C ++バージョンとの違いは、両方のレジスタがここに追加されるだけで、レジスタがメモリで折り畳まれていたことだけです。 レジスタ内の配置は、 aSimdおよびbSimdの初期化中に発生します。 一般に、このアプローチは、C ++コンパイラと.NETコンパイラのコードを比較するとき、特に違いはなく、ほぼ同等のパフォーマンスを提供します。 ただし、ポインターを使用したオプションは引き続き高速に動作します。 コードの最適化を有効にすると、SIMD命令が生成されることに注意してください。 つまり デバッグの逆アセンブラでそれらを確認することはできません。これは関数呼び出しとして実装されています。 ただし、最適化が有効になっているリリースでは、これらの指示を明示的な(組み込み)形式で受け取ります。
最後に
私たちは何を持っています:
- 多くの場合、ベクトル化によりパフォーマンスが4〜8倍向上します
- 洗練されたアルゴリズムには工夫が必要ですが、それなしではどこにもありません
- System.Numerics.Vectorsは現在、simd命令の一部のみをカバーしています。 より深刻なアプローチには、C ++が必要です。
- ベクトル化以外にも多くの方法があります:キャッシュの正しい使用、マルチスレッド、異種コンピューティング、メモリを使用した有能な作業(ガベージコレクターが汗をかかないように)など。
.NETでハードウェアアクセラレーションを検討したSasha Goldstein(「.NETプラットフォームでのアプリケーション最適化」の著者の1人)との簡単なtwitterの通信で、.NETで実装されているSIMDサポートとその内容を尋ねました。 C ++との比較。 彼は答えました。「間違いなく、C#よりもC ++の方が多くのことができます。 しかし、C#でクロスプロセッサのサポートを本当に得ることができます。 たとえば、SSE4とAVXの間の自動選択。 一般的に、これは朗報です。 少しの労力で、可能な限りすべてのハードウェアリソースを利用して、システムから可能な限り多くのパフォーマンスを得ることができます。
私にとって、これは生産的なプログラムを開発する非常に良い機会です。 少なくとも物理プロセスのモデリングに関する論文では、基本的に、一定数のスレッドを作成し、異種計算を使用することで効率を達成しました。 CUDAとC ++ AMPの両方を使用します。 開発はWindows 10のユニバーサルプラットフォームで行われ、WinRTに非常に魅力を感じています。これにより、C#とC ++ / CXの両方でプログラムを作成できます。 基本的に、長所では大規模な計算用のカーネルを作成します(Boost)が、C#では既にデータを操作してインターフェイスを開発しています。 当然、2つの言語の相互作用のためのバイナリABIインターフェイスを介したデータ転送には価格がありますが(それほど大きくはありません)、C ++ライブラリのより合理的な開発が必要です。 ただし、必要な場合にのみデータが送信され、結果を表示するためだけに送信されることはほとんどありません。
C#でデータを操作する必要がある場合は、WinRT型で動作しないように.NET型に変換します。これにより、C#で既に処理パフォーマンスが向上します。 たとえば、数千または数万の要素を処理する必要がある場合、または処理要件に特別な仕様がない場合、ライブラリを使用せずにC#でデータを計算できます(構造の300から1,000万インスタンスが、1回の反復でカウントされる場合があります)。 そのため、ハードウェアアクセラレーションアプローチは、タスクを簡素化し、高速化します。

記事を書くときのソースのリスト
- 新しいSIM対応JITに関する.NETブログ記事の翻訳
- .NETブログのSystem.Numerics.Vectorについて
- アラインメントとは何ですか?プログラムにどのように影響しますか?
- ループベクタリングでのデータ調整に関するインテルのブログ
さて、提供されたヘルプと情報を提供してくれたSasha Goldsteinに感謝します。