長い間、 XMLとXQueryを使用する際の「落とし穴」について話す計画がありました。
SQL Server 、 XQueryなどを頻繁に使用してXML値を解析する場合は、次の資料を読むことをお勧めします...
最初に、実験を行うためのテストXMLを生成します 。
USE AdventureWorks2012 GO IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL DROP TABLE ##temp GO SELECT val = ( SELECT [@obj_id] = o.[object_id] , [@obj_name] = o.name , [@sch_name] = s.name , ( SELECT i.name, i.column_id, i.user_type_id, i.is_nullable, i.is_identity FROM sys.all_columns i WHERE i.[object_id] = o.[object_id] FOR XML AUTO, TYPE ) FROM sys.all_objects o JOIN sys.schemas s ON o.[schema_id] = s.[schema_id] WHERE o.[type] IN ('U', 'V') FOR XML PATH('obj'), ROOT('objects') ) INTO ##temp DECLARE @sql NVARCHAR(4000) = 'bcp "SELECT * FROM ##temp" queryout "D:\sample.xml" -S ' + @@servername + ' -T -w -r -t' EXEC sys.xp_cmdshell @sql IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL DROP TABLE ##temp
xp_cmdshellを無効にしている場合は、以下を行う必要があります。
EXEC sp_configure 'show advanced options', 1 GO RECONFIGURE GO EXEC sp_configure 'xp_cmdshell', 1 GO RECONFIGURE GO
その結果、指定されたパスに沿って、次の構造を持つファイルを作成します。
<objects> <obj obj_id="245575913" obj_name="DatabaseLog" sch_name="dbo"> <i name="DatabaseLogID" column_id="1" user_type_id="56" is_nullable="0" is_identity="1" /> <i name="PostTime" column_id="2" user_type_id="61" is_nullable="0" is_identity="0" /> <i name="DatabaseUser" column_id="3" user_type_id="256" is_nullable="0" is_identity="0" /> <i name="Event" column_id="4" user_type_id="256" is_nullable="0" is_identity="0" /> <i name="Schema" column_id="5" user_type_id="256" is_nullable="1" is_identity="0" /> <i name="Object" column_id="6" user_type_id="256" is_nullable="1" is_identity="0" /> <i name="TSQL" column_id="7" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="XmlEvent" column_id="8" user_type_id="241" is_nullable="0" is_identity="0" /> </obj> ... <obj obj_id="1237579447" obj_name="Employee" sch_name="HumanResources"> <i name="BusinessEntityID" column_id="1" user_type_id="56" is_nullable="0" is_identity="0" /> <i name="NationalIDNumber" column_id="2" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="LoginID" column_id="3" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="OrganizationNode" column_id="4" user_type_id="128" is_nullable="1" is_identity="0" /> <i name="OrganizationLevel" column_id="5" user_type_id="52" is_nullable="1" is_identity="0" /> <i name="JobTitle" column_id="6" user_type_id="231" is_nullable="0" is_identity="0" /> <i name="BirthDate" column_id="7" user_type_id="40" is_nullable="0" is_identity="0" /> ... </obj> ... </objects>
さて、フェンスの実験を始めましょう...
XMLからデータをロードする最も効率的な方法は何ですか? おそらく、メモ帳でファイルを開き、内容をコピーして変数に貼り付ける必要はありません... OPENROWSETを使用する方が適切だと思います。
DECLARE @xml XML SELECT @xml = BulkColumn FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x SELECT @xml
しかし、面白いキャッチがあります。 結局のところ、ロード操作とXMLからの値の解析の組み合わせにより、パフォーマンスが大幅に低下する可能性があります。 以前に作成したファイルからobj_id値を取得する必要があるとします。
;WITH cte AS ( SELECT x = CAST(BulkColumn AS XML) FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x ) SELECT tcvalue('@obj_id', 'INT') FROM cte CROSS APPLY x.nodes('objects/obj') t(c)
私のマシンでは、このリクエストには非常に長い時間がかかります。
(495 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 20788, ..., lob logical reads 7817781, ..., lob read-ahead reads 1022368. SQL Server Execution Times: CPU time = 53688 ms, elapsed time = 53911 ms.
ダウンロードと解析を分離してみましょう。
DECLARE @xml XML SELECT @xml = BulkColumn FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x SELECT tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj') t(c)
すべてが非常に迅速に解決しました。
(1 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 7, ..., lob logical reads 2691, ..., lob read-ahead reads 344. SQL Server Execution Times: CPU time = 15 ms, elapsed time = 51 ms. (495 row(s) affected) SQL Server Execution Times: CPU time = 47 ms, elapsed time = 125 ms.
それで、問題は何でしたか? 実行計画を分析しましょう:

判明したように、問題は型変換にあるため、最初はXML型のパラメーターをノード関数に渡してみてください。
次に、解析にフィルタリングが必要な一般的な状況を検討します。そのような場合、 SQL ServerはXMLを操作するための関数呼び出しを最適化しないことに注意してください。
明確にするために、このリクエストでは、 value関数が2回実行されることを示します。
SELECT tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj') t(c) WHERE tcvalue('@obj_id', 'INT') < 0
(404 row(s) affected) SQL Server Execution Times: CPU time = 116 ms, elapsed time = 120 ms.

このニュアンスによりパフォーマンスが低下する可能性があるため、関数呼び出しを減らすことをお勧めします。
SELECT * FROM ( SELECT id = tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj') t(c) ) t WHERE t.id < 0
(404 row(s) affected) SQL Server Execution Times: CPU time = 62 ms, elapsed time = 74 ms.

または、次のようにフィルタリングできます。
SELECT tcvalue('@obj_id', 'INT') FROM @xml.nodes('objects/obj[@obj_id < 0]') t(c)
(404 row(s) affected) SQL Server Execution Times: CPU time = 110 ms, elapsed time = 119 ms.
しかし、大きな利益について話す必要はありません。 QueryCostは逆のことを言っていますが:
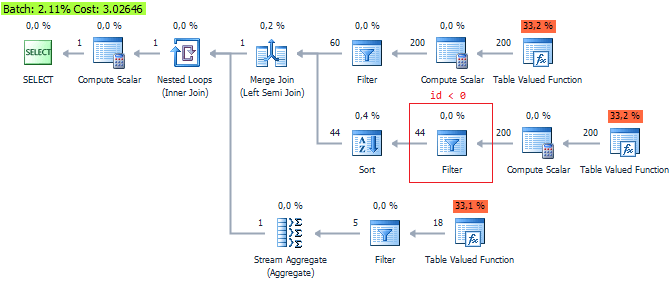
3番目のオプションが最も最適であることが示されています...これは、内部評価であるQueryCostを信頼しない別の引数とします。
スナックの最も興味深い例... XMLから解析する場合、もう1つの非常に重要な機能があります 。 リクエストを実行します:
SELECT tcvalue('../@obj_name', 'SYSNAME') , tcvalue('@name', 'SYSNAME') FROM @xml.nodes('objects/obj/*') t(c)
ランタイムを確認します。これは、急いでいない人にのみ適しています。
(5273 row(s) affected) SQL Server Execution Times: CPU time = 66578 ms, elapsed time = 66714 ms.
なぜこれが起こっているのですか? SQL Serverサーバーには、子ノードから親ノードを読み取る際に問題があります(より簡単に言うと、 SQL Serverは 「振り返る」のが困難です)。

それでは、どのようにすべきでしょうか? それは非常に簡単です...親ノードから読み取りを開始し、 CROSS / OUTER APPLYを使用して子を減算します。
SELECT tcvalue('@obj_name', 'SYSNAME') , t2.c2.value('@name', 'SYSNAME') FROM @xml.nodes('objects/obj') t(c) CROSS APPLY tcnodes('*') t2(c2)
(5273 row(s) affected) SQL Server Execution Times: CPU time = 156 ms, elapsed time = 184 ms.
上記の2つのレベルを調べる必要がある状況を考えることも興味深いです。 親要素の読み取りに関する問題は私には再現しませんでした:
USE AdventureWorks2012 GO DECLARE @xml XML SELECT @xml = ( SELECT [@obj_name] = o.name , [columns] = ( SELECT i.name FROM sys.all_columns i WHERE i.[object_id] = o.[object_id] FOR XML AUTO, TYPE ) FROM sys.all_objects o WHERE o.[type] IN ('U', 'V') FOR XML PATH('obj') ) SELECT tcvalue('../../@obj_name', 'SYSNAME') , tcvalue('@name', 'SYSNAME') FROM @xml.nodes('obj/columns/*') t(c)
また、1つの興味深い機能に言及したいと思いました。 OPENXMLには親の読み取りに問題はありません。
DECLARE @xml XML , @idoc INT SELECT @xml = BulkColumn FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x EXEC sys.sp_xml_preparedocument @idoc OUTPUT, @xml SELECT * FROM OPENXML(@idoc, '/objects/obj/*') WITH ( name SYSNAME '../@obj_name', col SYSNAME '@name' ) EXEC sys.sp_xml_removedocument @idoc
(5273 row(s) affected) SQL Server Execution Times: CPU time = 47 ms, elapsed time = 137 ms.
ただし、 OPENXMLにはXQueryよりも明確な利点があると考える必要はありません。 OPENXMLにも十分な在庫があります。 たとえば、 sp_xml_removedocumentの呼び出しを忘れると、重大なメモリリークが発生する可能性があります。
すべてがSQL Server 2012 SP3(11.00.6020)でテストされました。
この記事を英語圏の聴衆と共有したい場合:
XML、XQuery、パフォーマンスの問題