カットの下には多くの写真があり、より正確には交通量があります。
予備情報
タスクについて簡単に説明します。 理想的な世界では完璧な画像が得られると思われます
通常、 通常の平滑化フィルターは、隣接ピクセルに関する情報を使用して各ピクセルに新しい値を設定します。 たとえば、安価で怒っているガウスフィルターは、イメージマトリックスをガウスマトリックスで折りたたみます。 その結果、新しい画像では、各ピクセルは同じ数の元の画像とその近傍のピクセルの加重和になります。 わずかに異なるアプローチでは、中央値フィルターを使用します。つまり、各ピクセルを近くのすべてのピクセルの中央値に置き換えます。 これらの平滑化方法のアイデアの開発は、双方向フィルターです。 この手順では、選択したピクセルまでの距離とカラーのピクセルの近接度の両方に基づいて、加重和を取ります。
フィルターのアイデア
ただし、上記のフィルターはすべて、近くのピクセルに関する情報のみを使用します。 非局所平滑化フィルターの主な考え方は、処理されたピクセルに隣接するピクセルだけでなく、画像内のすべての情報を使用することです。 多くの場合、遠くのポイントの値は互いに完全に独立しているため、これはどのように機能しますか?
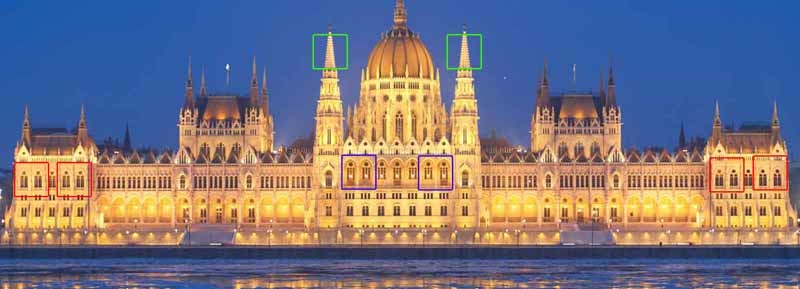
同じオブジェクトの異なるノイズレベルを持つ複数の画像がある場合、それらをノイズのない1つの画像に結合できることは明らかです。 これらの複数のオブジェクトが同じ画像の異なる場所に配置されている場合、この追加情報を使用できます(最初はこれらのオブジェクトを見つけます)。 また、これらのオブジェクトの外観が少し異なっていたり、部分的に重複していても、使用できる冗長データが残っています。 非局所平滑化フィルターはこの考え方を使用します。画像の類似した領域を検出し、それらの情報を相互平均に使用します。 もちろん、画像の部分が類似しているということは、それらが同じオブジェクトに属していることを意味するものではありませんが、原則として、近似は非常に良いことがわかります。 線画を見てください。 明らかに、ウィンドウ2と3はウィンドウ1に似ていますが、ウィンドウ4、5、6は似ていません。 ハンガリー議会の写真では、多数の同一の要素にも気付くことができます。

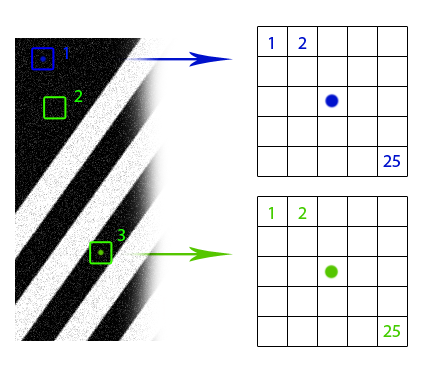
あるウィンドウのピクセルの近傍が別のウィンドウの対応するピクセルの近傍に類似している場合、これらのピクセルの値を相互平均に使用できると仮定します(図の青と緑のドット)。 しかし、これらの同様のウィンドウを見つける方法は? 重みをそれらに合わせてどのように配置し、どのような力で互いに影響を与えますか? イメージの断片の「類似性」の概念を形式化します。 まず、2つのピクセルを区別する関数が必要です。 ここではすべてが単純です。白黒画像の場合、通常はピクセル値の差の単純なモジュールが使用されます。 画像に関する追加情報がある場合、オプションが可能です。 たとえば、きれいな画像が完全に白い背景の完全に黒い色のオブジェクトで構成されていることがわかっている場合、ゼロの距離を色がそれほど変わらないピクセルにマッピングするメトリックを使用することをお勧めします。 カラー画像の場合、オプションも可能です。 RGB形式のユークリッドメトリックまたはHSV形式ではよりトリッキーなものを使用できます。 画像ウィンドウの「相違点」は、ピクセルの違いの合計です。
結果の値をより馴染みのあるウェイト形式に変換するといいでしょう
したがって、非ローカル平均化フィルターの単純な数学モデルは次のようになります。
正規化ディバイダー
上記の代替指標:
すべての場合
よく見ると、最終的な式はバイラテラルフィルターの式とほぼ同じです。ピクセル間の幾何学的な距離と色差ではなく、指数のみが画像のフラップ間の差であり、合計は画像のすべてのピクセルで実行されます。
効率に関する考慮事項と実装
明らかに、提案されたアルゴリズムの複雑さ
- 明らかに、ピクセルの重みは常にすべての重みを再計算する必要はありません。
ピクセル用
そしてその逆-等しい。 計算された重みを保持する場合、実行時間は半分になりますが、時間がかかります
スケールを保存するメモリ。
- ほとんどの実際の画像では、ほとんどのピクセル間の重みはゼロになります。 では、それらをまったくリセットしないのはなぜですか? 画像のセグメンテーションに基づいたヒューリスティックを使用できます。これにより、ピクセル単位で重量をカウントする場所が意味がないことがわかります。
- 重みを計算するとき、出展者は、より安価な計算関数に置き換えることができます。 同じ指数の少なくとも区分的補間。
このアルゴリズムを検討するときに生じる通常の質問は、なぜ領域の中心ピクセルの値のみを使用するのかということです。 一般的に言えば、二国間アンチエイリアシングのように、エリア全体の合計をメイン式に入れることを妨げるものはなく、これは複雑さにわずかに影響を及ぼしますが、修正されたアルゴリズムの結果はぼやけすぎます。 実際の画像では、同じオブジェクトであっても完全に同一であることはめったにないことを忘れないでください。アルゴリズムのこのような修正はそれらを平均化します。 隣接する画像要素からの情報を活用するために、通常の双方向のアンチエイリアスを事前に実行できます。 元のオブジェクトがまったく同じであることがわかっていた場合(テキストを平滑化した場合)には、そのような変更は有益です。
アルゴリズムの単純な実装(C + OpenCV 2.4.11):
#include "targetver.h" #include <stdio.h> #include <math.h> #include <opencv2/opencv.hpp> #include "opencv2/imgproc/imgproc.hpp" #include "opencv2/imgproc/imgproc_c.h" #include "opencv2/highgui/highgui.hpp" #include "opencv2/core/core.hpp" #include "opencv2/features2d/features2d.hpp" #include "opencv2/calib3d/calib3d.hpp" #include "opencv2/nonfree/nonfree.hpp" #include "opencv2/contrib/contrib.hpp" #include <opencv2/legacy/legacy.hpp> #include <stdlib.h> #include <stdio.h> using namespace cv; /* Returns measure of diversity between two pixels. The more pixels are different the bigger output number. Usually it's a good idea to use Euclidean distance but there are variations. */ double distance_squared(unsigned char x, unsigned char y) { unsigned char zmax = max(x, y); unsigned char zmin = min(x, y); return (zmax - zmin)*(zmax - zmin); } /* Returns weight of interaction between regions: the more dissimilar are regions the less resulting influence. Usually decaying exponent is used here. If distance is Euclidean, being combined, they form a typical Gaussian function. */ double decay_function(double x, double dispersion) { return exp(-x/dispersion); } int conform_8bit(double x) { if (x < 0) return 0; else if (x > 255) return 255; else return static_cast<int>(x); } double distance_over_neighbourhood(unsigned char* data, int x00, int y00, int x01, int y01, int radius, int step) { double dispersion = 15000.0; //should be manually adjusted double accumulator = 0; for(int x = -radius; x < radius + 1; ++x) { for(int y = -radius; y < radius + 1; ++y) { accumulator += distance_squared(static_cast<unsigned char>(data[(y00 + y)*step + x00 + x]), static_cast<unsigned char>(data[(y01 + y)*step + x01 + x])); } } return decay_function(accumulator, dispersion); } int main(int argc, char* argv[]) { int similarity_window_radius = 3; //may vary; 2 is enough for text filtering char* imageName = "text_noised_30.png"; IplImage* image = 0; image = cvLoadImage(imageName, CV_LOAD_IMAGE_GRAYSCALE); if (image == NULL) { printf("Can not load image\n"); getchar(); exit(-1); } CvSize currentSize = cvGetSize(image); int width = currentSize.width; int height = currentSize.height; int step = image->widthStep; unsigned char *data = reinterpret_cast<unsigned char *>(image->imageData); vector<double> processed_data(width*height, 0); //External cycle for(int x = similarity_window_radius + 1; x < width - similarity_window_radius - 1; ++x) { printf("x: %d/%d\n", x, width - similarity_window_radius - 1); for(int y = similarity_window_radius + 1; y < height - similarity_window_radius - 1; ++y) { //Inner cycle: computing weight map vector<double> weight_map(width*height, 0); double* weight_data = &weight_map[0]; double norm = 0; for(int xx = similarity_window_radius + 1; xx < width - similarity_window_radius - 1; ++xx) for(int yy = similarity_window_radius + 1; yy < height - similarity_window_radius - 1; ++yy) { double weight = distance_over_neighbourhood(data, x, y, xx, yy, similarity_window_radius, step); norm += weight; weight_map[yy*step + xx] = weight; } //After all weights are known, one can compute new value in pixel for(int xx = similarity_window_radius + 1; xx < width - similarity_window_radius - 1; ++xx) for(int yy = similarity_window_radius + 1; yy < height - similarity_window_radius - 1; ++yy) processed_data[y*step + x] += data[yy*step + xx]*weight_map[yy*step + xx]/norm; } } //Transferring data from buffer to original image for(int x = similarity_window_radius + 1; x < width - similarity_window_radius - 1; ++x) for(int y = similarity_window_radius + 1; y < height - similarity_window_radius - 1; ++y) data[y*step + x] = conform_8bit(processed_data[y*step + x]); cvSaveImage("gray_denoised.png", image); cvReleaseImage(&image); return 0; }
例
いくつかの結果を見てみましょう:


線のほぼ完璧な平滑化と明確なエッジに注意してください。 画像内の正方形領域が同じであるほど、アルゴリズムの動作は向上します。 ここでは、ラインに沿ったすべての正方形の領域がほぼ同じであるため、プログラムには各タイプの近隣の十分な例がありました。
もちろん、単純な正方形のウィンドウではエリアの「類似性」を検出できない場合には、すべてがそれほどバラ色ではありません。 例:


背景と円の内側は滑らかになりましたが、アーチファクトは円に沿って残りました。 もちろん、アルゴリズムは円の右側が左側と同じであり、180度回転していることを理解できないため、これを平滑化の際に使用します。 このような明らかなミスは、回転したウィンドウを調べることで修正できますが、実行時間はウィンドウの回転数を考慮した回数だけ増加します。
アルゴリズムが直線だけでなく平滑化できることは間違いないので、平滑化パラメーターを選択することの重要性を同時に示す別の例を次に示します。




2番目の図では、前のケースとほぼ同じアーティファクトが表示されています。 ここでは、同様のウィンドウが不足しているわけではありませんが、パラメーターが小さすぎます
テキストの作業の別の例。 小さくて非常にノイズの多い画像でさえ、その後のマシンでの使用に十分に処理されます(もちろん、ヒストグラムをイコライズし、シャープにした後):



すでに最適化された非ローカルアンチエイリアシングアルゴリズムを適用できるサイトのいくつかの例:


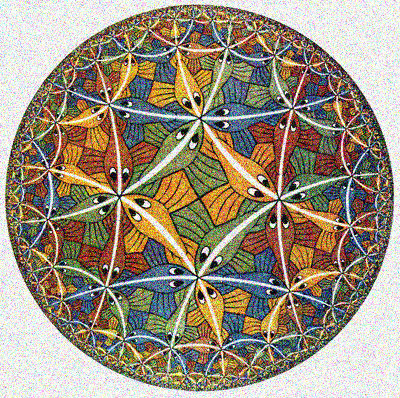



順序:元の、うるさい、復元された。 似たような要素が多いエッシャーの図面がどれほどきれいに掃除されたかに注目してください。 黒い線のみがより透明になり、テクスチャが滑らかになりました。
特徴点記述子を使用した重みのカウント
残念ながら、アルゴリズムの計算の複雑さが高いため、その実用的な用途が制限されていますが、繰り返し要素を使用して画像を平滑化する問題については良い結果を示しています。 このアルゴリズムの主な問題は、重みを計算するという基本的な考え方にあります。 各ピクセルが他のすべてのピクセルを回る必要があります。 すべてのピクセルをダブル表示することは避けられない悪であると想定しても、ウィンドウ3の半径でさえ重みを計算する時間が49倍増加するため、その隣のピクセルを表示することは不要に思えます。 元のアイデアに戻りましょう。 互いに滑らかにするためにそれらを使用するために、画像内の同様の場所を見つけたいです。 ただし、画像内のすべての可能なウィンドウをピクセルごとに比較して、同様の場所を見つける必要はありません。 興味深い画像要素を特定して比較する良い方法はすでにあります! もちろん、私はさまざまな機能記述子について話している。 通常、これはSIFTを意味しますが、この段階の目標は、まったく同じではなく、かなり類似した領域を多数見つけることであるため、精度が低いものを使用することをお勧めします。 記述子を使用する場合、重みを計算する手順は次のようになります。
- 画像の各ポイントで事前カウント記述子
- 画像を見て、ピクセルごとに
- o互いのピクセルを通過します
- o比較ハンドル
- o記述子が類似している場合、ピクセルごとにウィンドウを比較し、重みを考慮します
- o異なる場合、重量をゼロにする
- 二度目に画像を通過しないように、計算された重みとピクセルの座標が別のリストに入力されます。 リストに十分な数の要素が蓄積されたら、検索を停止できます。
- 指定した数の類似点が見つからない場合(ピクセルは目立たない)、画像を調べて、通常どおりに重みを検討します
このアプローチの利点:
- 特別なポイントでアンチエイリアシングを改善します。これは通常、私たちにとって最も興味深いものです。
- 画像内に同様の特異点が多数ある場合、速度が向上します
短所:
- ディスクリプタのカウントを回収するのに十分な類似点があるという事実ではありません
- アルゴリズムの結果と加速は、記述子の選択に大きく依存します
おわりに
結論:
- アルゴリズムは周期的なテクスチャーでうまく機能します
- アルゴリズムは、均一な領域を滑らかにします
- 画像が大きいほど、領域が類似し、アルゴリズムの動作が向上します。 しかし、 不敬に長い。
- 類似のものを見つけることができなかった領域は、うまく平滑化されません(最初にバイラテラルフィルターを適用するか、ウィンドウの回転を考慮することによって解決されます)
- 他の多くのアルゴリズムと同様に、平滑化パラメーターの値を調整する必要があります
このため、画像内の類似オブジェクトに関する情報を使用して、きれいな画像に最も近似する平滑化アルゴリズムを検討しました。 このような「疑似認識」から、類似オブジェクトの選択後、実際のスムージングへの移行はそれほど遠くありません。 実際、画像復元の最新のアプローチでは、この目的のためにニューラルネットワークを使用しており、原則として、実際にはより良く、より速く動作します。 ただし、ニューラルネットワークにはより多くのプログラミングスキルと微調整が必要です。 このようなアルゴリズムでさえ、認識のシミュレーションのみで、同等の、場合によってはより良い結果が得られます。
ソース
Antoni Buades、Bartomeu Coll画像ノイズ除去のための非ローカルアルゴリズム
Yifei Lou、Paolo Favaro、Stefano Soatto、Andrea Bertozzi非局所類似画像フィルタリング