もちろん、これは物語の半分にすぎません。 初歩的な検索はアプリケーションのニーズを満たすことができますが、より深い質問をする必要がある場合、長期的には機能しません。
ソース文書
ドキュメントストレージは非常に大きなトピックです。 私にとって、ドキュメントの保存方法(および保存対象)は、次の3つの領域に分かれています。
- ドキュメント/ドメインモデル。 開発者側からこれをすべて見てみましょうが、DDD(Domain Driven Design)のファンなら、これが役割を果たします。
- 現実の世界。 アカウント、購入、注文-ビジネスはこれらのことで動作します-それについて考えてみましょう。
- トランザクション、プロセス結果、イベントソース。 実際、アプリケーションで「何かが起こる」とき、これを行っている間に起こったすべてを追跡し、それを保持します。
私は後者に非常に惹かれています。 私は情報記憶装置であり、何かが起こったとき、何を、なぜ、どこで制限するのかを知りたい。
TechPubで購入しているユーザーを追跡するために私が使用していたことは次のとおりです。 これは私がビジネスに投入しようとしていたドキュメントのフォーマットですが、(Plularsightでの販売により)このポイントに到達することはありませんでした。
{ "id": 1, "items": [ { "sku": "ALBUM-108", "grams": "0", "price": 1317, "taxes": [], "vendor": "Iron Maiden", "taxable": true, "quantity": 1, "discounts": [], "gift_card": false, "fulfillment": "download", "requires_shipping": false } ], "notes": [], "source": "Web", "status": "complete", "payment": { //... }, "customer": { //... }, "referral": { //... }, "discounts": [], "started_at": "2015-02-18T03:07:33.037Z", "completed_at": "2015-02-18T03:07:33.037Z", "billing_address": { //... }, "shipping_address": { //... }, "processor_response": { //... } }
これは素晴らしい文書です。 素晴らしいドキュメントが大好きです! このドキュメントは、チェックアウトプロセス中のすべての情報の動きの正確な結果です。
- 顧客の住所(請求、配達用)
- お支払い情報と購入内容
- 彼らはどのようにしてここに来たのか、途中で起こったことに関する簡単な情報(メモの形で)
- プロセッサからの正確な回答(それ自体は大きなドキュメントです)
このドキュメントは、他のドキュメントを完成させる必要のない独立した自己完結型のオブジェクトにしたいです。 つまり、次のことができるようになりたいと思います。
- 注文する
- いくつかのレポートを実行する
- 変更、実装などについてクライアントに通知します。
- 必要に応じてさらにアクションを実行します(キャンセル、キャンセル)
このドキュメントは単独で完成し、素晴らしいです!
それでは、レポートをいくつか作成しましょう。
データ生成。 実テーブル
アナリストを率いるとき、2つのことを覚えておくことが重要です。
- 実行中のシステムで実行しないでください
- 非正規化は標準です
結合されたテーブルで巨大なクエリを実行するには永遠に時間がかかり、これは最終的には何にもつながりません。 経時的に変化しない(またはほとんど変化しない)履歴データに関するレポートを作成する必要があります。 非正規化は速度の向上に役立ち、レポートを作成するときは速度があなたの友人です。
これを考えると、PostgreSQLの長所を利用して、データを販売ファクトテーブルにまとめる必要があります 。 「実際の」テーブルは、システム内のイベントを表す非正規化されたデータセットであり、消化される実際の情報の最小量です。
私たちにとって、この事実はセールであり、このイベントは次のようになります。

Fakerで作成されたランダムな販売データを含むサンプルチヌークデータベースを使用しています 。
これらの各レコードは、蓄積したい単一のイベントであり、それらを組み合わせるディメンション(時間、サプライヤ)に関するすべての情報はすでに含まれています。 (カテゴリなど)を追加できますが、今のところこれで十分です。
これらのデータは表形式です。つまり、上記のドキュメントからデータを抽出する必要があります。 PostgreSQLを使用しているため、タスクは簡単ではありませんが、はるかに簡単です。
with items as ( select body -> 'id' as invoice_id, (body ->> 'completed_at')::timestamptz as date, jsonb_array_elements(body -> 'items') as sale_items from sales ), fact as ( select invoice_id, date_part('quarter', date) as quarter, date_part('year', date) as year, date_part('month', date) as month, date_part('day', date) as day, x.* from items, jsonb_to_record(sale_items) as x( sku varchar(50), vendor varchar(255), price int, quantity int ) ) select * from fact;
これは、一般的なテーブル式(OTV)のセットであり、機能的な方法で結合されています(これについては以下で詳しく説明します)。 OTVを一度も使用したことがない場合、少し変わったように見えるかもしれません...詳しく見て、名前と名前を組み合わせるだけだと理解するまでは。
上記の最初のリクエストでは、セールスIDを取り出してinvoice_idと呼びます。その後、 タイムスタンプを取り出してtimestampzに変換します。単純なアクションは本質的にです。
ここでもっと面白くなっているのはjsonb_array_elementsです 。これは、ドキュメントからオブジェクトの配列を取得し、各オブジェクトのエントリを作成します。 つまり、データベースに3つのオブジェクトを持つ単一のドキュメントがあり、次のクエリを起動した場合です。
select body -> 'id' as invoice_id, (body ->> 'completed_at')::timestamptz as date, jsonb_array_elements(body -> 'items') as sale_items from sales
セールを表す1つのエントリの代わりに、3を取得します。
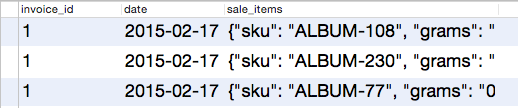
オブジェクトを選択したので、それらを別々の列に分ける必要があります。 これは、 jsonb_to_recordを使用した次のトリックが現れる場所です。 この関数をすぐに使用して、その場で型の値を記述できます。
select * from jsonb_to_record( '{"name" : "Rob", "occupation": "Hazard"}' ) as ( name varchar(50), occupation varchar(255) )
この簡単な例では、 jsonbをテーブルに変換します。これを行う方法をPostgreSQLに指示するだけです。 これは、まさに2番目のOTV(「イベント」)で行っていることです。 また、 date_partを使用して日付を変換します。
これにより、次の場合にビューに保存できるイベントテーブルが得られます。
create view sales_fact as -- the query above
このクエリは非常に遅いと思うかもしれません。 実際、非常に高速です。 これは、ある種のレベルマークやそのようなものではありません-このクエリが実際に高速であることを示す相対的な結果です。 データベースには1000個のテストドキュメントがあり、すべてのドキュメントに対するこのリクエストの実行は、約10分の1秒で返されます。

PostgreSQL かっこいい。
これで節約の準備が整いました!
販売レポート
その後、すべてが簡単になります。 必要なデータを組み合わせるだけで、何かを忘れた場合は、それをビューに追加するだけで、テーブル結合について心配する必要はありません。 本当に速いデータ変換だけです。
トップ5の売り手を見てみましょう。
select sku, sum(quantity) as sales_count, sum((price * quantity)/100)::money as sales_total from sales_fact group by sku order by salesCount desc limit 5
このクエリは、0.12秒でデータを返します。 1000エントリに十分な速度。
OTVおよび機能要求
RethinkDBで私が本当に気に入っていることの1つは、独自のクエリ言語であるReQLです。 Haskellに触発され(チームによる)、それはすべて作曲に関するものです(特に私にとって):
ReQLを理解するには、関数型プログラミングの理解が役立ちます。 関数型プログラミングは宣言型パラダイムの一部であり、プログラマーは、この値を計算するために必要なステップを記述するのではなく、計算したい値を記述することを求めます。 原則として、データベースクエリ言語は宣言型の理想を目指して努力します。これにより、クエリプロセッサは最適な実行プランを選択する際に最大限の自由を得ることができます。 ただし、SQLは特殊なキーワードと特定の宣言構文を使用してこれを実現しますが、ReQLには機能的構成を介して任意の複雑な操作を表現する機能があります。
上記からわかるように、OTVを組み合わせてこれを概算することができます。各OTVは特定の方法でデータを変換します。
おわりに
私が書くことのできるものはもっとたくさんありますが、他のドキュメント指向システムができることをすべてできるように、すべてを要約しましょう。 Postgresのクエリ機能は非常に大きく 、実行できないことのリストは非常に小さく、見たとおり、ドキュメントをスプレッドシートに変換する機能は非常に役立ちます。
そして、これでこの小さなシリーズの記事は終わりです。