
この分野の専門家としてお客様とコミュニケーションをとる際には、適切な用語、特に「認識」という言葉を積極的に使用しています。 同時に、CuneiformとFineReaderで育った聴衆は、この用語で、切り取られた画像セクションを特定の数(シンボルコード)と比較するタスクを正確に行うことがよくあります。これは、今日ニューラルネットワークアプローチによって解決されており、情報認識問題の最初のステップではありません。 最初は、画像内でカードをローカライズし、情報フィールドを見つけて、文字にセグメンテーションを実行する必要があります。 正式な観点からリストされた各サブタスクは、独立した認識タスクです。 また、ニューラルネットワークをトレーニングするための実証済みのアプローチとツールがある場合、毎回オリエンテーションとセグメンテーションタスクに個別のアプローチが必要です。 銀行カードを認識する問題を解決するために使用したアプローチについて学習したい場合は、catにようこそ!
クレジットカードからのデータの認識は、アルゴリズムの観点から非常に関連性が高く、非常に興味深いものです。 適切に実装されたプラスチックカード認識プログラムにより、オンライン支払いやモバイルアプリケーションでの支払いを行う際に、ほとんどのデータを手動で入力する必要がなくなります。 認識の観点から、銀行カードは標準サイズ(85.6×53.98 mm)の複雑な文書であり、標準フォームで実行され、特定のフィールドセット(必須とオプションの両方)を含んでいます:カード番号、カード所有者名、日付発行、有効期限、口座番号、CVV2コードまたはその同等物。 いくつかのフィールドは前面にあり、他の部分は背面にあります。 また、支払いトランザクションを完了するにはカード番号のみが必要であるという事実にもかかわらず、ほとんどすべての支払いシステム(認証として)には、さらにカード所有者の名前、有効期限、CVV2コードが必要です。 カードの表面の情報フィールドを認識するタスクにさらに焦点を当てます(客観的には、それは何倍も複雑です)。
したがって、インターネットで支払いを行うには、ほとんどの場合、カード番号、所有者の名前、画像上のカードの有効性を認識する必要があります。
最初の段階として、カードの角の座標を見つける必要があります。 カードの幾何学的特性は既知であるため(すべてのカードは厳密にISO 781標準に準拠して作られています)、アルゴリズムを使用して直線を検索およびソートし、カードの四角形を決定します。これについては、Habréの出版物で既に説明しました 。
既知の四角形を使用すると、マップ画像を固定解像度の直交ビューに変換する射影変換を計算して画像に適用することは難しくありません。 このような修正された画像は、次の段階、つまり特定の情報フィールドの方向と認識への入り口に来ると想定しています。
アーキテクチャの観点から、3つのターゲットフィールドの認識は同じ部分で構成されています。
- 画像を事前にフィルタリングします(カードの背景を抑制するため、驚くほど変化します)。
- ターゲット情報フィールドのゾーン(行)を検索します。
- 見つかった文字列を「文字ボックス」に分割します。
- 人工ニューラルネットワーク(ANN)を使用して見つかった「シンボルボックス」の認識。
- 後処理の適用(Moonアルゴリズムを使用した認識エラーの検出、名前と姓の辞書の使用、日付の有効性の確認など)。
認識手順の構成は同じですが、複雑さは大きく異なります。 カード番号を認識するのが最も簡単です(正当な理由により、 パブリックドメインに配置されたものを含むさまざまなモバイルプラットフォームに十分な数のSDKがあります )。
- カード番号には数字のみが含まれます。
- 番号の形式は、支払いカードの種類ごとに厳密に定義されています。
- 製造業者に関係なく、数字の幾何学的位置はあまり「歩きません」。
- 数字の認識の正確さを検証できるMoonアルゴリズムがあります。
有効期間とカード名義人の2つのフィールドが残っているため、状況はより複雑です。 この記事では、カードの有効期間を認識する手順について説明します(名前の認識も同様に実行されます)。
有効期限認識アルゴリズム
マップの画像が既にまっすぐになっているようにします(上記のように)。 アルゴリズムの結果は、4桁の10進数である必要があります。1か月は2桁、1か月は有効期限です。 受信した4桁がマップに表示されている数字と一致する場合、アルゴリズムは正しい答えを与えたと考えられています。 それらを区切る記号は考慮されず、何でもかまいません。 認識の拒否は、不正解と解釈されます。
最初のステップは、カード上のフィールドをローカライズすることです(番号とは異なり、このフィールドの場所は標準化されていません)。 対応するテキストフラグメントが非常に短く(ほとんどの場合5文字)、構文の冗長性が小さく、任意のテキストフラグメントまたは背景の雑多なセクションでさえ誤検出される可能性が許容できないほど大きいため、マップの領域全体で「ブルートフォースメソッド」を使用することはあまり有望ではありません。 したがって、トリックを適用します。日付自体を探すのではなく、カード番号の下にあり、安定した幾何学的構造を持つ情報ゾーンを探します。

図1.必要な3行の情報ゾーンの例
検討中のゾーンは3行に分割され、その1行は多くの場合空です。 このゾーン内の日付文字列の場所が適切に定義されていることが重要です。 この逆説的なフレーズは次のことを意味します:ゾーンに2つの空でない行がある場合、それらの行間隔は3行ゾーンの行間隔と一致するか、2倍の間隔と行の高さの合計にほぼ等しくなります。
ゾーンを検索して3行に分割することは、背景のマップ上に存在するため複雑になります。これは、既に述べたように多様です。 この問題を解決するには、カードの画像にフィルターの組み合わせを適用します。その目的は、文字の垂直方向の境界線を強調表示し、画像の残りの詳細を空白にすることです。 フィルターシーケンスは次のとおりです。
- 式を使用してカラーチャネル値を平均化することによる画像のグレー化
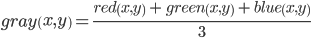 、図2bを参照してください。
、図2bを参照してください。 - 式を使用した垂直境界の画像の計算
 、図2cを参照してください。
、図2cを参照してください。 - 数学的形態学を使用して小さな垂直境界をフィルタリングします(具体的には、長方形サイズのウィンドウで侵食を適用します)
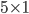 )、図2dを参照してください。
)、図2dを参照してください。

図2.クレジットカード画像の事前フィルタリング:a)元の画像、b)グレースケール画像c)垂直境界画像、d)フィルタリングされた垂直境界画像
実装では、時間を節約するために、van Herkアルゴリズムを使用してモルフォロジー演算を実装しています 。 プリミティブのサイズに依存しない時間で、長方形のプリミティブを使用してモルフォロジー演算を計算できます。これにより、ドキュメントのリアルタイム認識で大面積の複雑なモルフォロジーフィルターを使用できます。
フィルタリング後、処理された画像のピクセル強度が垂直軸に投影されます。
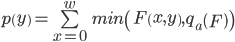
どこで
 -フィルターされた画像
-フィルターされた画像 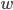 -画像の幅
-画像の幅  -レベル分位
-レベル分位  (この値は、インクなどでペイントされた「有効な」タイプのテキストの存在により通常発生するシャープなノイズ境界の影響を抑えるために、しきい値のクリッピングに使用されます。)
(この値は、インクなどでペイントされた「有効な」タイプのテキストの存在により通常発生するシャープなノイズ境界の影響を抑えるために、しきい値のクリッピングに使用されます。)
得られた投影に従って
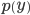 行間隔に水平方向の境界がないと仮定して、行の最も可能性の高い位置を見つけることが可能になりました。 これを行うために、すべての可能な期間にわたって予測の合計を最小化します
行間隔に水平方向の境界がないと仮定して、行の最も可能性の高い位置を見つけることが可能になりました。 これを行うために、すべての可能な期間にわたって予測の合計を最小化します  および初期フェーズ
および初期フェーズ 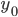 事前定義された間隔から:
事前定義された間隔から:

現地安値以来
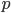 通常、テキストの外側の境界でかなり発音されます。最適な値
通常、テキストの外側の境界でかなり発音されます。最適な値  4に等しい(マップ上に3行、したがって4つの極小があると仮定)。 その結果、パラメーターが見つかります
4に等しい(マップ上に3行、したがって4つの極小があると仮定)。 その結果、パラメーターが見つかります 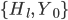 行間隔の中心とテキストの外側の境界を定義します(図3を参照)。
行間隔の中心とテキストの外側の境界を定義します(図3を参照)。
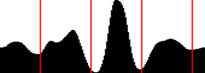
図3.投影のビューと、3行の領域を強調する最適なセクション
この画像で見つかった元の領域の形状と線の位置を考慮して、日付検索領域を大幅に縮小できます。 そのような交点に対して、部分文字列の多くの可能な位置が生成され、それを使用して作業を続けます。
そのようなカード上のすべての文字が等幅である場合、候補部分文字列はそれぞれ文字に分割されます。 これにより、動的プログラミングアルゴリズムを使用して、文字認識なしで記号間セクションを検索できます(必要なのは、文字幅の許容間隔だけです)。 ここでは、アルゴリズムの主要なアイデアの概要を説明します。
- 日付を含む文字列の垂直方向の境界線のフィルターされた画像を取得します。 この画像の投影を水平軸に構築します。 結果の投影には、垂直境界の場所(つまり文字のゾーン)の局所的な最大値と、文字間の最小値が含まれます。 させる -予想される期間、および
 -期間値の最大偏差。
-期間値の最大偏差。 - 構築された投影に沿って左から右に移動します。 追加のバッテリーアレイを開始し、累積されたペナルティが各要素に保存されます。 すべてのステップで
 バッテリーの長さを考慮してください
バッテリーの長さを考慮してください  。 現在のペナルティ値として、ポイントでの投影値の合計を書き込みます および考慮されたセグメントからの最小ペナルティ値。 さらに、指定された最小値を提供する前のステップのインデックスを保存します。
。 現在のペナルティ値として、ポイントでの投影値の合計を書き込みます および考慮されたセグメントからの最小ペナルティ値。 さらに、指定された最小値を提供する前のステップのインデックスを保存します。 - 説明した方法で投影全体を通過した後、罰金の配列アキュムレータを分析し、前の手順のインデックスを保存することで、すべてのセクションを復元できます。
文字にセグメント化したら、人工ニューラルネットワーク(ANN)を使用して認識します。 残念ながら、このプロセスの詳細な説明はこの記事の範囲外です。 いくつかの事実のみに注意してください。
- 認識には、 cuda-convnetツールを使用してトレーニングされた畳み込みニューラルネットワークが使用されます。
- 訓練されたネットワークのアルファベットには、数字、句読点、スペース、および非記号(「ゴミ」)記号が含まれます。
したがって、シンボルの各画像について、この画像内の対応するアルファベット記号の位置の疑似確率推定値を含む配列を取得します。 正しい答えは、最高のオプションのストリングを作成することであると思われます(最高の疑似確率を使用)。 ただし、ANNは時々間違っています。 ANNエラーの一部は、期待される日付値に既存の制限があるため、後処理を使用して修正できます(たとえば、13か月目がありません)。 これを行うために、いわゆる「ルーレット」アルゴリズムが使用され、「行を読み取る」ためのすべての可能なオプションが、全体的な疑似確率の降順で繰り返しリストされます。 既存の制限を満たす最初のオプションが答えと見なされます。
もちろん、説明されている「基本的な」後処理に加えて、システムは追加の状況依存メソッドも使用しますが、その説明はこの記事には記載されていません。
作業結果
SDKの品質を評価するために、異なる銀行が発行するさまざまな支払いシステムのカード画像のデータベースを750画像(一意のカードの数-60枚)で収集しました。 収集された資料で次の結果が得られました。
- 数字認識品質-99%
- 日付認識品質-99%
- カード所有者の名前認識品質-90%
- iPhone 4Sでの合計カード認識時間は0.6秒です。
有用なソースのリスト
- van Herk M.長方形および八角形カーネル上の局所最小および最大フィルターの高速アルゴリズム//パターン認識レター、1992、V。13、No。7、pp。 517-521。