
面接中に尋ねるのが好きな簡単な質問があります。 たとえば、テーブルへのレコードの総数を計算する方法は? 複雑なことは何もないように思えますが、さらに深く掘り下げると、対話者に多くの興味深いニュアンスを伝えることができます。
簡単なことから始めましょう...これらのクエリは、最終結果の点で互いに何か違うのですか?
SELECT COUNT(*) FROM Sales.SalesOrderDetail SELECT COUNT_BIG(*) FROM Sales.SalesOrderDetail
ほとんどの回答:「いいえ」
あまり頻繁ではありませんが、「クエリは同じ結果を返しますが、 COUNTはINT型の値を返し、 COUNT_BIGはBIGINT型を返します。」
実装計画を分析すると、多くの人が見落としている違いに気付くことができます。 COUNTを使用する場合、プランにはCompute Scalar操作が含まれます。

演算子のプロパティを見ると、そこに表示されます:
[Expr1003] = Scalar Operator(CONVERT_IMPLICIT(int,[Expr1004],0))
これは、 COUNTを呼び出すときに、 COUNT_BIGが暗黙的に使用され、その後、結果がINTに変換されるためです。
そんなことはあまり言いませんが、型変換はプロセッサの負荷を増やします。 もちろん、多くの人は、このステートメントを実行しても費用はかかりませんが、簡単な事実に注意する必要があります 。SQLServerは、Scalarステートメントの計算を過小評価することがよくあります 。
COUNTの代わりにSUMを使用したい人も知っています。
SELECT SUM(1) FROM Sales.SalesOrderDetail
このオプションは、 COUNTとほぼ同等です。 また、実行プランで追加のCompute Scalarを取得します。
[Expr1003] = Scalar Operator(CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005] END)
次に、パフォーマンスの問題について詳しく説明します...
上記のクエリを使用する場合、 SQL Serverレコードの数を計算するには、 フルインデックススキャン (またはテーブルが束である場合はフルテーブルスキャン)を実行する必要があります。 いずれにせよ、これらの操作は最速とはほど遠いものです。 システムビューを使用してレコード数sys.dm_db_partition_statsまたはsys.partitionsを取得するのが最適です ( sysindexesがありますが、 SQL Server 2000との後方互換性のために残されています )。
USE AdventureWorks2012 GO SET STATISTICS IO ON SET STATISTICS TIME ON GO SELECT COUNT_BIG(*) FROM Sales.SalesOrderDetail SELECT SUM(p.[rows]) FROM sys.partitions p WHERE p.[object_id] = OBJECT_ID('Sales.SalesOrderDetail') AND p.index_id < 2 SELECT SUM(s.row_count) FROM sys.dm_db_partition_stats s WHERE s.[object_id] = OBJECT_ID('Sales.SalesOrderDetail') AND s.index_id < 2
実行計画を比較すると、システムビューへのアクセスは安価になります。

AdventureWorksでは、システムビューを使用する利点は明らかではありません。
Table 'SalesOrderDetail'. Scan count 1, logical reads 276, ... SQL Server Execution Times: CPU time = 12 ms, elapsed time = 26 ms. Table 'sysrowsets'. Scan count 1, logical reads 5, ... SQL Server Execution Times: CPU time = 4 ms, elapsed time = 4 ms. Table 'sysidxstats'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 2 ms, elapsed time = 1 ms.
3000万レコードのパーティションテーブルでの実行時間:
Table 'big_test'. Scan count 6, logical reads 114911, ... SQL Server Execution Times: CPU time = 4859 ms, elapsed time = 5079 ms. Table 'sysrowsets'. Scan count 1, logical reads 25, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms. Table 'sysidxstats'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms.
テーブル内のレコードの可用性を確認する必要がある場合、上記のメタデータを使用しても特別な利点は得られません...
IF EXISTS(SELECT * FROM Sales.SalesOrderDetail) PRINT 1 IF EXISTS( SELECT * FROM sys.dm_db_partition_stats WHERE [object_id] = OBJECT_ID('Sales.SalesOrderDetail') AND row_count > 0 ) PRINT 1
Table 'SalesOrderDetail'. Scan count 1, logical reads 2,... SQL Server Execution Times: CPU time = 1 ms, elapsed time = 3 ms. Table 'sysidxstats'. Scan count 1, logical reads 2,... SQL Server Execution Times: CPU time = 4 ms, elapsed time = 5 ms.
また、実際には、 SQL Serverはメタデータからフェッチするためのより洗練された実行計画を生成するため、少し遅くなります 。

すべてのテーブルのレコード数を一度に計算する必要がある場合、さらに興味深いものになります。 実際には、一般化できるいくつかのオプションに出会いました。
カーソルを使用してすべてのユーザーテーブルをバイパスする文書化されていない手順を使用するオプション#1:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL DROP TABLE #temp GO CREATE TABLE #temp (obj SYSNAME, row_count BIGINT) GO EXEC sys.sp_MSForEachTable @command1 = 'INSERT #temp SELECT ''?'', COUNT_BIG(*) FROM ?' SELECT * FROM #temp ORDER BY row_count DESC
オプション#2- SELECT COUNT(*)クエリを生成する動的SQL:
DECLARE @SQL NVARCHAR(MAX) SELECT @SQL = STUFF(( SELECT 'UNION ALL SELECT ''' + SCHEMA_NAME(o.[schema_id]) + '.' + o.name + ''', COUNT_BIG(*) FROM [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + ']' FROM sys.objects o WHERE o.[type] = 'U' AND o.is_ms_shipped = 0 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 10, '') + ' ORDER BY 2 DESC' PRINT @SQL EXEC sys.sp_executesql @SQL
オプション#3-毎日の簡単なオプション:
SELECT SCHEMA_NAME(o.[schema_id]), o.name, t.row_count FROM sys.objects o JOIN ( SELECT p.[object_id], row_count = SUM(p.row_count) FROM sys.dm_db_partition_stats p WHERE p.index_id < 2 GROUP BY p.[object_id] ) t ON t.[object_id] = o.[object_id] WHERE o.[type] = 'U' AND o.is_ms_shipped = 0 ORDER BY t.row_count DESC
システムの表現が非常に優れていることを多くの賞賛しました。 しかし、彼らと仕事をするとき、「楽しい」驚きが私たちを待っているかもしれません。
SQL Server 2000から2005に移行するときに、いくつかのシステムビューが誤って更新されたときに、このような面白いバグがあったことを覚えています 。 この場合、特に幸運な人は、テーブル内のレコード数に関する誤った値がメタデータから返されました。 すべてDBCC UPDATEUSAGEコマンドで処理されました。
SQL Server 2005 SP1とともに、このバグは修正され、すべて問題ありません...しかし、 SQL Server 2005 SP4からSQL Server 2012 SP2にバックアップを復元したときに、同様の状況をもう一度観察しました。 残念ながら、実際の環境では問題を再現できません。そのため、オプティマイザーは私を少しtrickしました。
UPDATE STATISTICS Person.Person WITH ROWCOUNT = 1000000000000000000
簡単な例を紹介します。
最も無害なリクエストが通常よりも長く実行され始めました。
SELECT FirstName, COUNT(*) FROM Person.Person GROUP BY FirstName
クエリプランを見ると、そこには明らかに不適切な推定行数の値があります。
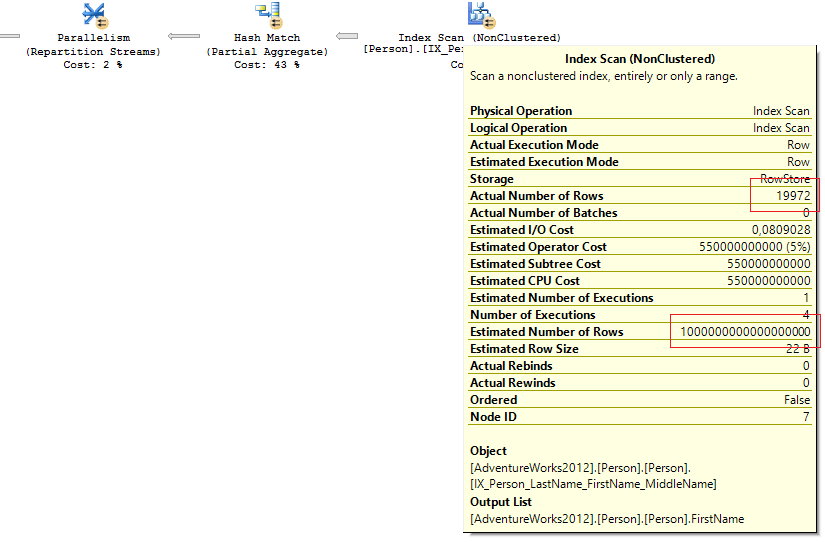
クラスターインデックスの統計を見ました。
DECLARE @SQL NVARCHAR(MAX) DECLARE @obj SYSNAME = 'Person.Person' SELECT @SQL = 'DBCC SHOW_STATISTICS(''' + @obj + ''', ' + name + ') WITH STAT_HEADER' FROM sys.stats WHERE [object_id] = OBJECT_ID(@obj) AND stats_id < 2 EXEC sys.sp_executesql @SQL
すべてが正常でした:

しかし、先ほどお話しした体系的なアイデアでは:
SELECT rowcnt FROM sys.sysindexes WHERE id = OBJECT_ID('Person.Person') AND indid < 2 SELECT SUM([rows]) FROM sys.partitions p WHERE p.[object_id] = OBJECT_ID('Person.Person') AND p.index_id < 2
悲しみがありました:

クエリでフィルタリングするための述語はなく、オプティマイザーはFull Index Scanを選択しました。 フルインデックス/テーブルスキャンでは、オプティマイザーは統計から予想される行数を取得せず、メタデータを参照します(これが常に発生するかどうかは不明です)。
行の推定数に基づいて、 SQL Serverが実行計画を生成し、実行に必要なメモリ量を計算することは周知の事実です。 推定が正しくない場合、実際に必要なメモリよりも多くのメモリがリクエストの実行に割り当てられる可能性があります。
SELECT session_id, query_cost, requested_memory_kb, granted_memory_kb, required_memory_kb, used_memory_kb FROM sys.dm_exec_query_memory_grants
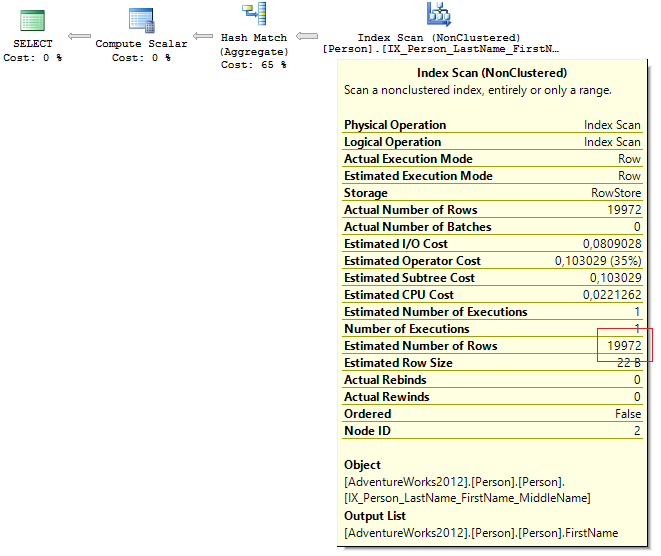
これが、行数の誤った推定がもたらすものです:
query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb ----------- -------------------- -------------------- -------------------- -------------- 1133156839 769552 769552 6504 6026
問題は非常に簡単に解決されました。
DBCC UPDATEUSAGE(AdventureWorks2012, 'Person.Person') WITH COUNT_ROWS DBCC FREEPROCCACHE
リクエストを再コンパイルすると、すべてが正常に戻りました。
query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb ----------- -------------------- -------------------- -------------------- -------------- 0,2919 1168 1168 1024 952
システムの概念がもはや「節約棒」のように見えない場合、どのオプションが残っていますか? 昔ながらの方法ですべてを実行できます。
SELECT COUNT_BIG(*) FROM ...
しかし、テーブルへの集中的な挿入では、結果を信頼しません。 NOLOCKの「魔法の」ヒントは、正しい値を保証しません。
SELECT COUNT_BIG(*) FROM ... WITH(NOLOCK)
実際、テーブル内の行数の正しい値を取得するには、分離レベルSERIALIZABLEで、またはTABLOCKX ヒントを使用してクエリを実行する必要があります。
SELECT COUNT_BIG(*) FROM ... WITH(TABLOCKX)
結果として得られるもの...クエリの期間中の排他的なテーブルロック。 そして、誰もが彼にとって何が良いかを自分で決めなければなりません。 私の選択はメタデータです。
さらに興味深いのは、条件ごとに行数をすばやく計算する必要がある場合です。
SELECT City, COUNT_BIG(*) FROM Person.[Address] --WHERE City = N'London' GROUP BY City
テーブルで頻繁な挿入/削除操作が発生しない場合は、インデックス付きビューを作成できます。
IF OBJECT_ID('dbo.CityAddress', 'V') IS NOT NULL DROP VIEW dbo.CityAddress GO CREATE VIEW dbo.CityAddress WITH SCHEMABINDING AS SELECT City, [Rows] = COUNT_BIG(*) FROM Person.[Address] GROUP BY City GO CREATE UNIQUE CLUSTERED INDEX IX ON dbo.CityAddress (City)
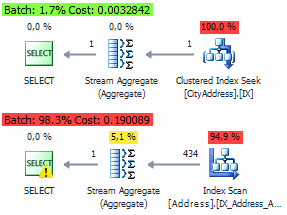
これらのクエリの場合、オプティマイザーはクラスタービューインデックスに基づいて同一のプランを生成します。
SELECT City, COUNT_BIG(*) FROM Person.[Address] WHERE City = N'London' GROUP BY City SELECT * FROM dbo.CityAddress WHERE City = N'London'
インデックス表現の有無にかかわらず実装計画:
この投稿では、あらゆる場合に理想的なソリューションはないことを示したかったのです。 そして、特定の状況ではそれぞれ、個別のアプローチで行動する必要があります。
すべてがSQL Server 2012 SP3(11.00.6020)でテストされました。
結論として ...テーブル内の行の総数を計算する必要がある場合は、メタデータを使用します-これが最速の方法です。 そして、私が上で引用した古いバグの状況を恐れないでください。
フィールドのコンテキスト内または条件ごとに行数をすばやく計算する必要がある場合は、インデックス付きビューまたはフィルター選択されたインデックスを使用しようとします。 それはすべて状況に依存します。
テーブルが小さい場合、またはパフォーマンスの問題がそれほど深刻でない場合は、実際に古い形式でSELECT COUNT(*)を記述する方が簡単です...
この記事を英語圏の聴衆と共有したい場合:
レコードCOUNTを計算する最速の方法は何ですか?