主な間違いは、作者がそれが必要でないところで普遍性を台無しにしようとし、本当に必要なところで普遍性を提供しないことです。 その結果、処理が遅くなり使用できなくなります。
おそらくそれが、多くの人々がまだビットオフを純粋に学術的な興味のあるアルゴリズムであり、現実にはほとんど適用できないと考える理由です。 ただし、これは誤りです。
最近、それにもかかわらず、許容できるオプションが現れ始めています。 そのうちの1人は Boostに到達しようとしましたが、彼を入れませんでした。
さらに、最初のものが単にあまりうまく設計および実装されていない場合、ブーストになった2番目のものは一般的にはビット単位のソートではなく、小さな配列でstd :: sortを呼び出すことになります一種のハイブリッドです。 したがって、そのインターフェイスには、とりわけ、要素を比較するための関数が含まれており、std :: sortに渡す必要があります。
私の意見では、これらのオプションは両方とも、インターフェイスの点でも速度の点でも、真の、忠実な、正統なビット単位のソートに到達しません。
この記事の目的は、アルゴリズムの分析でも実装の詳細の詳細な説明でもないことに注意してください。 このアルゴリズムは、その「ユーザー特性」の観点から考慮されます。つまり、迅速に機能する必要があり、使いやすいはずです。
まず、理論だけではないことを示すために、ビット単位の並べ替えをstd :: sort and boost :: integer_sortと比較します。
8ビット、100-1000要素 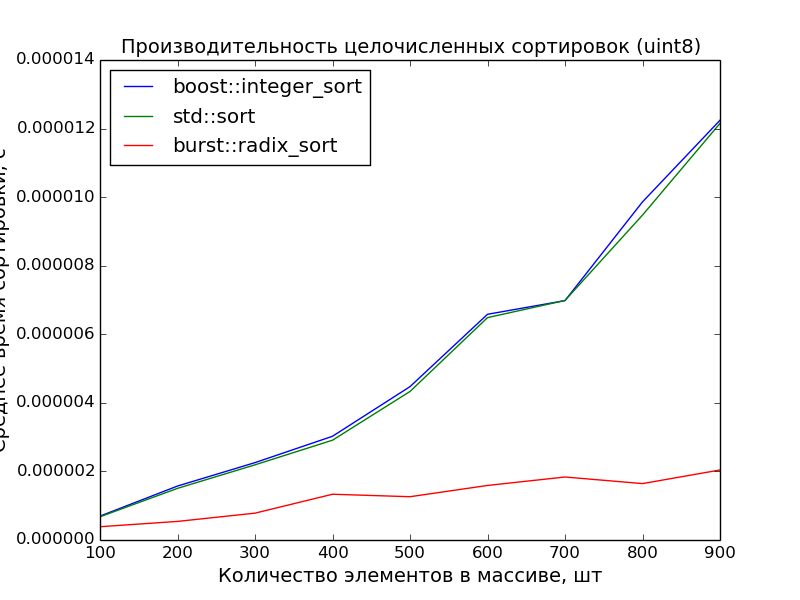
8ビット、1000-10000要素 
8ビット、10,000〜100,000要素 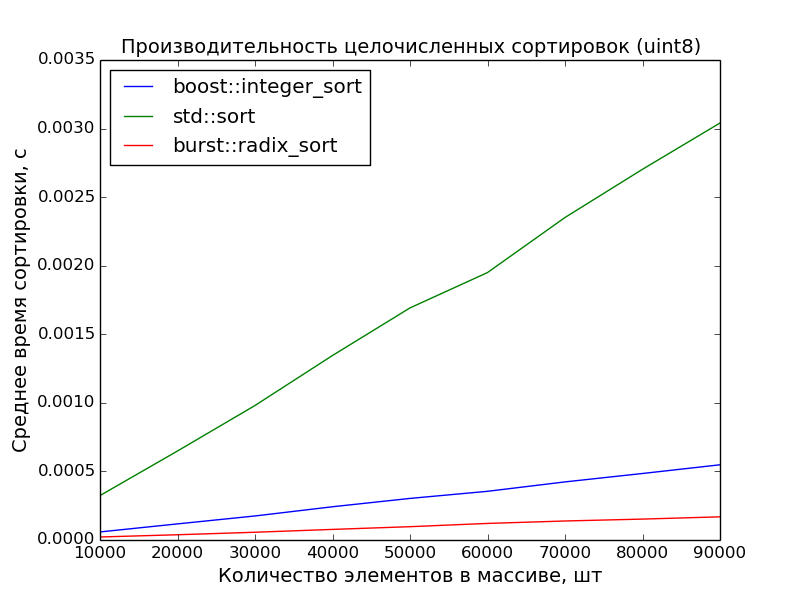
16ビット、100-1000要素 
16ビット、1000-10000要素 
16ビット、10,000-100,000要素 
32ビット、100-1000要素 
32ビット、1000-10000要素 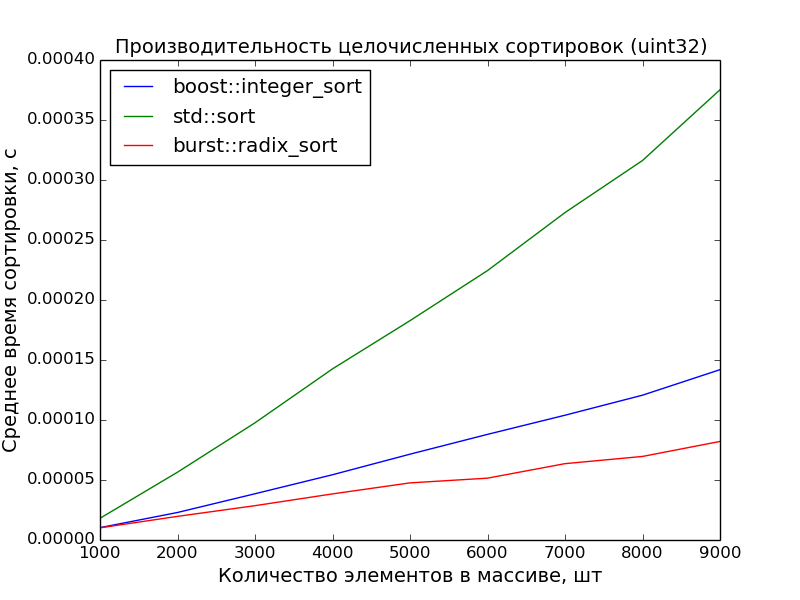
32ビット、10,000-100,000要素 
64ビット、100-1000要素 
64ビット、1000-10000要素 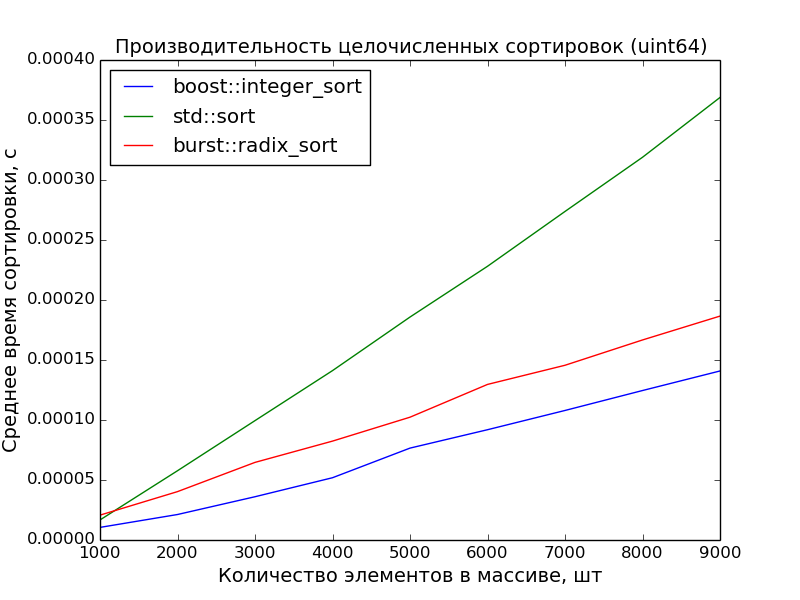
64ビット、10,000〜100,000要素 
測定は、Core i7 3.40GHzプロセッサを搭載したマシンで行われました。 Core 2 Duo 2.26GHzプロセッサを搭載したラップトップでは、ビット単位の並べ替えの利点はさらに明白です。
それでは、設計に取りかかりましょう。
最初のアプローチ
有能なインターフェースを得るには、当然、啓発のために標準ライブラリを使用するのが最善です。
標準のstd :: sortアルゴリズムを使用します。 最初のオプションは、2つの反復子のみを受け入れます。 イテレータはソート可能な範囲を指定しますが、範囲要素については、順序関係が定義されていることが知られています-「より小さい」演算子。 ソートするにはこれで十分です。
template <typename RandomAccessIterator> void sort (RandomAccessIterator first, RandomAccessIterator last);
しかし、要素の「less」演算子が定義されていない場合、または要素を別の方法で比較する必要がある場合はどうでしょうか? 次に、ユーザーは自分で順序関係を設定し、それを3番目の引数として渡す必要があります。
template <typename RandomAccessIterator, typename Compare> void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
この例に基づいて構築した場合、ビット単位のソートはどのようになりますか? 最初のバージョンでは-ほぼ同じです。 入力範囲の要素が整数であることがわかっている場合、結果はstd :: sortとまったく同じです。
template <typename RandomAccessIterator> void radix_sort (RandomAccessIterator first, RandomAccessIterator last);
しかし、入力要素が数字ではない場合はどうでしょうか? 簡単です。これらの要素から数値へのマッピングを指定する必要があります。 このマッピングは、std :: sortの順序関係と同様に、関数の3番目の引数になります。
template <typename RandomAccessIterator, typename Map> void radix_sort (RandomAccessIterator first, RandomAccessIterator last, Map to_integer);
このインターフェイスは、数値からのビットの割り当てに影響を与える方法を提供しません。 一方、ユーザーは数字を並べ替えてすばやく処理したいので、非変態ユーザーの大多数が十分な利用可能なインターフェイスを持っていることは明らかです。 原則として、その実装の詳細はあまり関心がありません。
これは、ビットの割り当てに直接関連する関数のすべての引数が最後のどこかにあることを意味します。
したがって、このステップでは、カテゴリは何らかの形で自動的に選択されると考えており、現時点では他の問題に気を取られる可能性があります。
追加メモリ
ビット単位のソートアルゴリズムが機能するには、追加のメモリが必要です。
- 1ビットでソートした中間結果を保存する配列。
- アイテムカウンターの配列。
中間結果を保存する問題には2つの解決策があります。
- 関数内の配列にメモリを割り当てます。
- バッファを外部に渡します。
少し考えてみると、正しい解決策は明らかです。ユーザーはバッファを外部に渡す必要があります。 さらに、バッファはメモリの先頭にイテレータの形式で設定され、そのサイズはソートされた範囲のサイズ以上になります。
- より柔軟です
ユーザーは、ソートされた範囲のサイズに厳密に等しいメモリを割り当てる必要はありません。 必要に応じて、1つの大きなピースを選択し、それを使用してさまざまなサイズの範囲をソートできます。
- より効率的です。
ソートが複数回実行される場合、バッファにメモリを一度割り当ててから、ソートに転送するだけで十分です。 そして、ソート自体は割り当てに貴重な時間を費やすことはありません。
選択されたソリューションを考えると、更新されたインターフェイスは次のようになります。
template <typename RandomAccessIterator1, typename RandomAccessIterator2> void radix_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer); template <typename RandomAccessIterator1, typename RandomAccessIterator2, typename Map> void radix_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer, Map to_integer);
ユーザーがソートの前に毎回バッファーを作成するのが面倒な場合、基本ラッパーを自分で書くことができます。
template <typename RandomAccessIterator, typename Map> void im_too_lazy_to_create_a_buffer_for_the_radix_sort (RandomAccessIterator first, RandomAccessIterator last, Map to_integer) { using value_type = std::iterator_traits<RandomAccessIterator>::value_type; std::vector<value_type> buffer(std::distance(first, last)); radix_sort(first, last, buffer.begin(), to_integer); }
カウンターの配列も、原則として明確です。
サイズと桁数を計算し、カウンターに必要な配列を割り当て、これらのカウンターを並べ替え関数に転送する作業は、ユーザーに転送するには複雑すぎることは明らかです。 ユーザーが配列をソートしたい。 残りは彼にとって面白くない。
そして、ここで最も重要なことになります-放電の割り当ての問題であり、これは別々に議論されるべきです。
数字からのビットの割り当て
ビットごとのソートの最も不幸な開発者の数字を区別するためのお気に入りの方法は、整数ベースを関数に渡すことです。除算の残りは1桁と見なされます。 そして、最も一般的なそのような基礎は10です。これは理解することができます。 しかし、許さないでください。
一部の開発者が行うと推測しているこのメソッドのわずかな改善は、2のべき乗を基礎とし、関数の引数で、基礎自体ではなくこの程度を指定することです。 したがって、放電はビット演算を使用して割り当てられます。ビット演算自体は、単純な除算よりもすでに優れていますが、それでも不良です。
たとえば、上記の最初の例の著者など、一部のユーザーは、1回の放電のビット深度と最小値と最大値を設定するようにユーザーに提案しています。 これは、ユーザーが誤った、または一貫性のないパラメーターを渡すことで簡単に関数を壊す可能性があるため、受け入れられません。
したがって、適切なインターフェイスを選択するために、いくつかの重要な考えを策定します。
- ユーザーは、ソートされた数値のすべての数字をソートするために使用したい
実際、主なケースは、最初のランクでソートし、次に2番目、3番目などでソートします。 隙間なく最後まで。
放電または放電の一部の省略は、ユーザーが放電を分離するメカニズムから必要となる可能性がある唯一の重要な機会ですが、調整することができます。これについては後で説明します。
- ベストビットは1バイトです
検証できたすべてのオペレーティングシステムとコンパイラのすべてのプロセッサで、1ビットにつき1バイトを使用すると、ソートが最も速く機能します。 車にとって、これは最も便利なケースです。
実際、顕微鏡配列(10〜20要素)を並べ替える場合、8バイトの数字は半バイトを放電として使用する方が有利ですが、そのようなサイズでは、ビットごとの並べ替えは比較による並べ替えよりも劣ります(特に有利ではありません)。したがって、この場合は興味がありません。
これらのステートメントに基づいて、to_integer関数の結果から基数を整数にマッピングする放電割り当てメカニズムを作成します。 さらに、基数関数によって返される型は1ビットと見なされます。 たとえば、基数がstd :: uint8_tを返す場合、1バイトがビットとして扱われます。
これに基づいて、コンパイル段階で、すべての必要な情報を取得できます:放電のサイズと次の放電を取得するためのシフト(この場合-8)、放電の可能な値の範囲(この場合-[0、256))、ソートされた数字のビット数など
また、動的メモリを完全に取り除くことができ、放電のカウンターでもスタック上に配列を作成できます。
最終的なインターフェイスは次のようになります。
template <typename RandomAccessIterator1, typename RandomAccessIterator2> void radix_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer); template <typename RandomAccessIterator1, typename RandomAccessIterator2, typename Map> void radix_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer, Map to_integer); template <typename RandomAccessIterator1, typename RandomAccessIterator2, typename Map, typename Radix> void radix_sort (RandomAccessIterator1 first, RandomAccessIterator1 last, RandomAccessIterator2 buffer, Map to_integer, Radix radix);
最後の2つの引数はオプションです。 さらに、後者はいくつかの例外的なケースでのみ使用され、最後から2番目のケースは比較的頻繁に使用されます。 おそらくstd :: sortの順序関係とほぼ同じでしょう。
デフォルトでは、基数関数は数値の下位バイトを返し、to_integer関数は恒等変換です。 したがって、通常の整数がソートされる場合、他に何も指定する必要はありません。
パスについて
並べ替えの際に数字または個々の数字のギャップをどのように配置するかにまだ興味がある人は、教えてください。 これを行うには、基数マッピングの不要なビットを破棄するか、すべての不要な桁をゼロにするトリッキーなto_integerマッピングを作成する必要があります。
たとえば、各ビットから上位の半バイトを破棄するには、基数マッピングを次のように記述する必要があります。
たとえば、各ビットから上位の半バイトを破棄するには、基数マッピングを次のように記述する必要があります。
auto radix = [] (auto x) -> std::uint8_t { return x & 0xf; }; // .
結論
ビットごとのソートに対するこのアプローチの利点:
- デフォルトで高性能
ユーザーはさまざまなオプションを試すことができます。たとえば、std :: uint16_tまたはboolを放電として使用できますが、ほとんどの場合、この結果は悪化するだけです。
- 標準ライブラリの互換性
このアルゴリズムは、標準ライブラリの基本設計テンプレートの1つであるイテレータを使用します。 イテレータはアルゴリズムを使用する方が便利であるという事実に加えて、コンテナよりも高速です。 これには個別の説明が必要ですが、これはこの記事の範囲に当てはまりません。
さらに、コンバーター(to_integer)は、std :: transformなどのアルゴリズムによってSBSユーザーにもなじみがあります。
- ユーザーは実装の詳細から最大限離れていますが、何が起こっているかを制御できます。
ユーザーはアルゴリズムを「損なう」ことも、関数に誤った引数を渡すこともできません。 -最悪の場合、そのコードはコンパイルされません。 同時に、彼はまだ自分の手でプロセスを完全に制御しています(「97で並べ替え」などの「アカデミック」実験を除く)。
- 可能なことはすべてコンパイル段階で行われます。
関数には単一の割り当てはありません。 使用されるすべての追加メモリは、外部から取得されるか、スタックに割り当てられます。
さらに、ビットの数もコンパイル段階でわかっているため、テンプレートメタプログラミングを使用すると、サイクルをビット単位でアンワインドできます。
したがって、ビット単位の並べ替えは、戦闘コードでの実用に非常に適したアルゴリズムです。 チェックメイト、「学者」!
内部実装が興味深い場合、 コードはここにあります 。