
私は最近、簡単な例を使用して、モーション認識アルゴリズムがどのように機能するかを著者が説明している記事を読みました 。 これは、ビデオストリーム分析アルゴリズムに関する私自身の研究を思い出しました。 多くの人々は、優れたOpenCVプロジェクトがあることを知っています。 これは、コンピュータビジョンの広範なクロスプラットフォームライブラリであり、さまざまなアルゴリズムが含まれています。 しかし、それを理解することはそれほど簡単ではありません。 マシンビジョンを使用する方法と場所に関する多くの出版物と例を見つけることができますが、その仕組みはわかりません。 つまり、これはプロセスを理解するのに十分ではないことがよくあります。特にこのトピックを勉強し始めたばかりの場合はなおさらです。
この記事では、ビデオ分析のアーキテクチャについて説明します。
ビデオ画像分析の一般的なスキームを以下に示します。
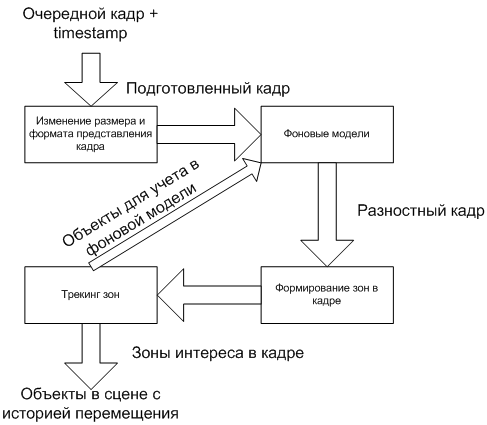
プロセスは、いくつかの連続した段階に分割されます。 それらのそれぞれの出力では、フレームで何が起こっているかについての情報がさらに詳細に補足されます。 フレームの変更によりきめ細かく対応するために、ステップ間にフィードバックがある場合もあります。
スキームをより詳細に検討してください。
ビデオストリームとは
最初に、ビデオストリームとは何かを決定する必要があります。 ビデオデータには多くの形式がありますが、その本質は1つに要約されます。1秒あたり特定の周波数を持つフレームのシーケンスです。 フレームは、解像度とフォーマット(ピクセルあたりのビット数とその解釈:どのビットがどの色成分に対応するか)によって特徴付けられる画像です。 ストリーム内では、フレーム圧縮を使用して送信データの量を減らすことができますが、画面に表示されると、フレームは常に初期状態に拡張されます。 直接、分析アルゴリズムは非圧縮フレームでも常に同じように機能します。
したがって、ビデオストリームは、フレームレート、フォーマット、および解像度によって特徴付けられます。
アナリティクスは常に一度に1つのフレームのみを処理することに注意することが重要です。 つまり、それらは順番に処理されます。 さらに、次の処理中に、前のフレームから経過した時間を知ることが重要です。 この値は頻度から計算できますが、より実用的なアプローチはタイムスタンプ-タイムスタンプでフレームを追跡することです。
プレゼンテーションフレームのサイズと形式を変更する
最初のステップはトレーニングです。 原則として、サイズは大幅に縮小されます。 実際には、画像の各ピクセルはさらなる処理に関与します。 したがって、フレームが小さいほど、すべてが高速に動作します。 当然、圧縮中に、フレーム内の情報の一部が失われます。 しかし、これは重要ではありませんが、有用ですらあります。 分析の対象となるオブジェクトの大部分は、圧縮中にフレームから消えない程度の大きさです。 ただし、カメラの品質、照明、自然要因に関連するあらゆる種類の「ノイズ」は低減されます。
解像度の変更は、元の画像の複数のピクセルを1つに結合することにより発生します。 格納される情報の部分は、統合の方法によって異なります。
たとえば、元の画像の3 x 3の正方形ピクセルは、結果の1ピクセルに変換する必要があります。 9ピクセルすべてを集計したり、4コーナーピクセルの合計のみを取得したり、中央ピクセルを1つだけ使用したりできます。
4角ピクセル:

すべてのピクセルの合計:

中央のピクセル:

結果はどこでも速度と品質がわずかに異なります。 しかし、時々、より多くの情報を失う方法が、すべてのピクセルを使用する方法よりも均一な画像を提供することが起こります。
この段階でのもう1つのアクションは、画像形式の変更です。 原則として、カラー画像は使用されません。これにより、フレームの処理時間が長くなるためです。 たとえば、RGB24にはピクセルあたり3バイトが含まれます。 そして、Y8は1つに過ぎませんが、情報コンテンツの最初のものよりもそれほど劣っていません。
Y8 =(R + G + B)/ 3。
結果は同じ画像ですが、グレースケールです:


背景モデル
これは最も重要な処理ステップです。 このステージの目的は、シーンの背景を形成し、背景と新しいフレームの違いを取得することです。 全体としての回路全体の品質は、この段階のアルゴリズムに依存します。 一部のオブジェクトが背景として受け入れられる場合、またはその逆の場合、背景の一部がオブジェクトとして選択される場合、さらに修正するのは困難です。
最も単純な場合、背景として、空のシーンのあるフレームを使用できます。

オブジェクトのあるフレームを選択します。

これらのフレームをY8に変換し、オブジェクトを含むフレームから背景を減算すると、次のようになります。

便宜上、2値化を実行できます。大きい0のすべてのピクセルの値を255に置き換えます。その結果、グレースケールから白黒画像に切り替えます。

すべてがうまくいくようで、オブジェクトは背景から分離されており、明確な境界があります。 しかし、まず、オブジェクトの影が目立ちました。 次に、画像ノイズによるアーチファクトがフレームの上部に表示されます。
実際には、このアプローチは良くありません。 影、光のフレア、カメラの明るさの変化はすべての結果を台無しにします。 これはまさにタスクの複雑さです。 光のフレア、建物や雲の影、植物の枝の振動、フレーム圧縮のアーチファクトなど、自然の要因と画像ノイズを無視しながら、オブジェクトを背景から分離する必要があります。 さらに、放棄されたオブジェクトを探している場合は、逆に背景の一部になってはいけません。
これらの問題を異なる効率で解決する多くのアルゴリズムがあります。 バックグラウンドの単純な平均化から、確率モデルと機械学習の使用まで。 それらの多くはOpenCVにあります。 さらに、いくつかのアプローチを組み合わせることが可能であり、さらに良い結果が得られます。 ただし、アルゴリズムが複雑になるほど、次のフレームの処理に時間がかかります。 ライブビデオが少なくとも12.5フレーム/秒の場合、システムで処理できるのは80ミリ秒のみです。 したがって、最適なソリューションの選択は、タスクとその実装に割り当てられたリソースに依存します。
ゾーン形成
差分フレームが形成されます。 黒い背景に白いオブジェクトが表示されます。


次に、オブジェクトを互いに分離し、オブジェクトのピクセルを結合するゾーンを形成する必要があります。

これは、たとえば、 接続コンポーネントのラベル付けを使用して実行できます。
ここで、背景モデルのすべての欠陥がすぐに表示されます。 上からの男はいくつかの部分、多くの人工物、人々からの影に分けられます。 ただし、これらの欠陥の一部はこの段階で修正できます。 オブジェクトの面積、その高さと幅、ピクセル密度がわかれば、余分なオブジェクトを除外できます。
上記のフレームでは、青色のフレームは追加の処理に関係するオブジェクトを示し、緑色のフレームはフィルター処理されたオブジェクトを示します。 ここでもエラーが発生する可能性があります。 ご覧のように、いくつかの部分に分割された上部の男性も、そのサイズのためにフィルタリングされました。 この問題は、たとえばパースペクティブを使用して解決できます。
その他のエラーが発生する可能性があります。 たとえば、複数のオブジェクトを1つにまとめることができます。 そのため、この段階では実験のための大きな分野があります。
追跡ゾーン
最後に、最後の段階で、ゾーンはオブジェクトに変わります。 ここでは、最後の数フレームを処理した結果が使用されます。 主なタスクは、2つの隣接するフレームのゾーンが同じオブジェクトであることを確認することです。 サイズ、ピクセル密度、色特性、動きの方向の予測など、サインは非常に多様です。 これは、フレームのタイムスタンプが重要な場所です。 オブジェクトの速度と移動距離を計算できます。
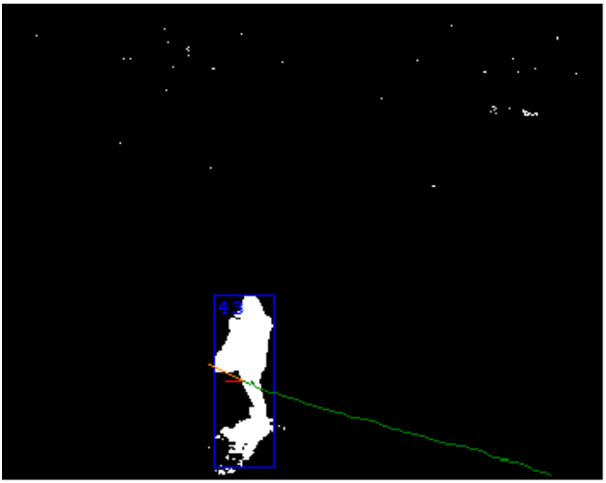
この段階で、前のエラーの1回限りのエラーを修正できます。 たとえば、接着されたオブジェクトは、移動の履歴を考慮して分割できます。 一方、問題があるかもしれません。 それらの中で最も重要なのは、2つのオブジェクトの交差です。 この問題の特殊なケースで、長い間大きなオブジェクトが小さなオブジェクトを隠す場合。
バックグラウンドモデルの会計対象
前の手順のパフォーマンスを向上させるために、アーキテクチャにフィードバックが存在する場合があります。 最初に思い浮かぶのは、背景を作成するときにシーン内のオブジェクトに関する情報を使用することです。
たとえば、この方法では、セットバックオブジェクトを区別して、背景の一部にしないことができます。 または、「ゴースト」と戦う:背景を作成するときにステージに人がいた場合、その人が去ると、その場所に「ゴースト」オブジェクトが表示されます。 オブジェクトの動きの軌跡がこの場所で始まることを理解すると、背景の「ゴースト」をすばやく削除できます。
結果
すべてのステージの結果は、シーン内のオブジェクトのリストです。 それらのそれぞれは、サイズ、密度、速度、軌道、運動の方向、およびその他のパラメーターによって特徴付けられます。
このリストは、シーン分析でも使用されます。 オブジェクトが線を交差しているか、間違った方向に移動しているかを判断できます。 特定のゾーン内のオブジェクトの数、アイドルリール、落下などのイベントをカウントできます。
おわりに
最新のビデオ分析システムは非常に優れた結果を達成していますが、これまでのところ、複雑な多段階プロセスのままです。 さらに、理論の知識は常に良い実用的な結果を与えるとは限りません。
私の意見では、優れたマシンビジョンシステムの作成は非常に複雑なプロセスです。 アルゴリズムの調整は非常に時間がかかり、時間のかかるビジネスであり、ソフトウェア実装の微妙さも干渉します。 多くの実験が必要です。 また、OpenCVはこの点で貴重ですが、OpenCVに含まれるツールも正しく使用できる必要があるため、結果を保証するものではありません。
この記事が、どのように機能し、どのOpenCVツールをどの段階で適用できるかを理解するのに役立つことを願っています。