エントリー
XMLの美しさは何ですか? これはすべてのプラットフォームに実装されており、「人間が読み取れる」データスキーム(条件付きで人間が読み取れる)が作成されています。 ブラウザで25メガバイトのファイルを開くと、このテキスト形式の短所にすぐに気付き、考え始めます。 もちろん、これを頻繁に行うわけではありませんが、それでもXMLを置き換えるものは何でしょうか?
自作のバイナリコンテナをプロジェクトに追加すると、パートナーが来てそれらをこのデータチャネルに接続するように要求すると、失敗します。 Google Protobufは最初は良いように見えますが、すぐにこれがXMLの代わりではなく、機能に欠けることに気付きます。 BSONはProtobufの5倍の速度であり、コンパクト性に劣り、データスキームは実装されていません。
別のバイナリ形式を開発しています。
USDS 1.0
USDS(または$ S)-ユニバーサルシリアル化データ構造-ユニバーサルシリアル化データ構造、XMLおよびJSONを完全に置き換えることができるバイナリ形式。 主な違い:
- テキストタグ/キーの代わりに、整数が使用されます。 関係「名前」-「整数識別子」は、「辞書」で個別に設定されます。 辞書は、USDS文書に添付することも、個別に転送することもできます。
- XMLのような終了タグはありません。
- USDS文書は、辞書にも厳密に指定されているスキームに従って厳密に生成されます。 多態性とオプションのフィールドがサポートされています。
- USDS文書の数値は、バイナリ形式(テキストではなく)で保存されます。
この形式を文書化し、それを使用するライブラリの最初のバージョンを作成したと仮定します。 利益はありますか? ベンチマークはすべてをその場所に配置します。

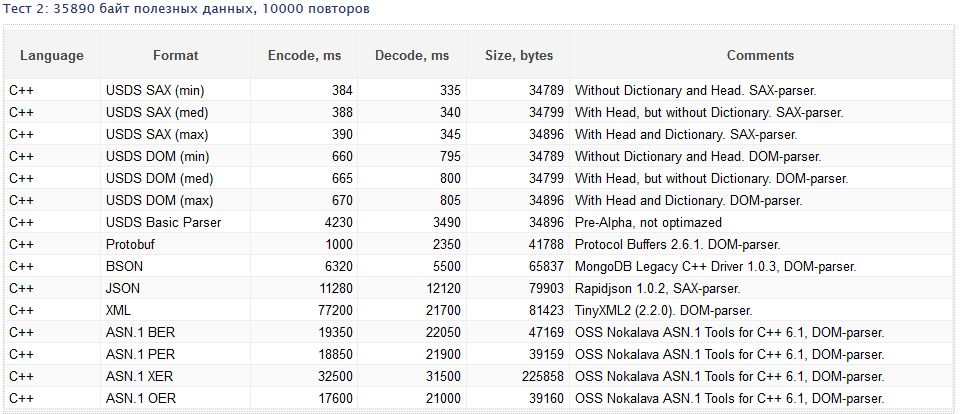
まだ多くの作業がありますが、この中の何かはすでに存在します:Basic Parserは常にGoogle Protobufに譲りますが、それほどではありません。
使用例
バイナリ形式ですが、それを使用することはXMLほど難しくありません。 C ++(および他の言語では遠い未来)でどのように見えるかを見てみましょう。
ステップ1:辞書のコンパイル
上記のように、USDS文書はスキームに従ってのみ構築され、次のようになります。
USDS DICTIONARY ID=1000000 v.1.0 { 1: STRUCT internalObject { 1: UNSIGNED VARINT varintField; 1: UNSIGNED VARINT varintField; 2: DOUBLE doubleField; 3: STRING<UTF-8> stringField; 4: BOOLEAN booleanField; } RESTRICT {notRoot;} 2: STRUCT rootObject { 1: INT intField; 2: LONG longField; 3: ARRAY<internalObject> arrayField; } }
回路を構築するためのすべての規則は、 ここで見つけることができます 。 USDS Basic Parserライブラリは、スキームのすべての要素をまだサポートしていませんが、上記の例は実際のものです。 回路をテキストファイルに保存するか、ソースコードに直接貼り付けます。次は何をしますか?
ステップ2:パーサーを初期化します。
いずれにせよ、データスキームは「text_dictionary」配列にあることが判明したため、パーサーにフィードします。
BasicParser* clientParser = new BasicParser(); clientParser->addDictionaryFromText(text_dictionary, strlen(text_dictionary), USDS_UTF8);
パーサーは、バイナリUSDSドキュメントを生成する準備ができています。 バイナリのみをデコードする必要がある場合、辞書による初期化は必要ありません。パーサーはバイナリUSDSドキュメントから直接辞書を自動的に抽出します。
ステップ3:バイナリドキュメントを作成します。
このアルゴリズムは、他のDOMパーサーでの作業と同じです。複数のルートオブジェクトを追加し、値で初期化して、出力データ配列を生成します。
UsdsStruct* tag = clientParser->addStructTag("rootObject"); tag->setFieldValue("intField", 1234); tag->setFieldValue("longField", 5000000000); ... BinaryOutput* usds_binary_doc = new BinaryOutput(); clientParser->encode(usds_binary_doc, true, true, true); const unsigned char* binary_data = usds_binary_doc->getBinary(); size_t binary_size = usds_binary_doc->getSize();
配列を操作する機能は省略されています。サンプルのソースコードをダウンロードすることで、それらを個別に表示できます。
ステップ4:バイナリドキュメントのデコード:
実験の純度を高めるために、個別のパーサーオブジェクトを作成し、辞書で初期化せずにバイナリドキュメントを解析するかどうかを確認します。
BasicParser* serverParser = new BasicParser(); serverParser->decode(binary_data, binary_size); int int_value = 0; long long long_value = 0; tag->getFieldValue("intField", &int_value); std::cout << "\tintField = " << int_value << "\n"; tag->getFieldValue("longField", &long_value); std::cout << "\tlongField = " << long_value << "\n";
「サーバー」は事前にデータスキームについて何も知らないが、冷静にバイナリを受信し、テキスト名でフィールドを見つけ、C ++変数値に正しく変換したことに注意してください。 この機能は、Google ProtobufおよびASN.1では使用できません。
フィールドを数値識別子(辞書で指定されたものと一致するID)で初期化すると、プログラムを大幅に高速化できます。例のソースコードを参照してください。
人間の可読性
これは本当に非常に重要な機能です。外部のGoogle ProtobufまたはASN.1バイナリパッケージ(XERを除く)を読むことはできません。 BSONを使用すると、任意のデータパケットをJSONに変換できますが、これは既に適切です。 USDSも彼に遅れをとっていません。
std::string json; serverParser->getJSON(USDS_UTF8, &json); std::cout << "JSON:\n" << json << "\n";
サーバーは任意のバイナリドキュメントを受信しただけでなく、JSONに変換することもできました。 「クライアント」側でも同じ操作を実行できます。DOMオブジェクトを作成し、すぐにJSONに変換します。これはデータスキームにも厳密に対応しています。
USDS開発計画には、フルGUIを備えたUSDSドキュメントエディターが含まれます。 近い将来、USDS Basic Parserはあらゆる方向のXML、JSON、USDS間の変換を実装します。
おわりに
プロジェクトでの使用が強く推奨されていない生の製品(Pre-Alpha)を公開したのはなぜですか? あなたの反応は私にとって重要です:
- 製品には何が欠けていますか?
- 彼はまったく必要ですか?
- ドキュメントとソースコードは明確に書かれていますか?
ソース:
プロジェクトページ: USDS 1.0
ここからサンプルのライブラリとソースコードをダウンロードします 。
ライブラリのソースコードはこちらから入手できます 。