
はじめに
ビッグデータ業界の爆発的な成長に対応するため、Machine Learingは、大きなデータアレイを操作するための新しいツールとアプローチを必要としていました。 Hadoop 、 Spark 、 Storm 、 Elasticsearchなどのエコシステムおよびビッグデータソフトウェア製品...定義済みのアルゴリズムを備えたさまざまな機械学習フレームワークがあります。 世界の一流大学は、多くの無料の機械学習とビッグデータのコースを作成しています。
データの視覚化タスクを解決するツールもあります。 2つのツールを強調したいと思います。これは、統計データ処理とグラフィックスのために作成されたプログラミング言語Rのエコシステムです 。 Wekaは、データマイニングと予測問題の解決のための視覚化ツールとアルゴリズムのセットです。 ところで、両方のツール/プログラミング言語の開発は1993年に始まり、両方ともニュージーランドからです:)。 そしてもちろん、 D3.js 、 JfreeChart 、 HighCharts.jsなど、一般的なデータ視覚化フレームワークを使用して、最終製品を提供するほぼすべてのチームがすでにそれを行っている多くの視覚化ツールがあります。
それとは別に、ビッグデータや機械学習を操作するための対話型シェルの方向性を強調したいと思います。 最も有名で人気のあるツールは、Pythonコミュニティの製品であるIPythonです。 参照の数から判断すると(私自身は彼と密接に連携していませんでした)、これは機械学習の専門家の間で事実上の標準です。 2014年、IPythonの作成者は新しいプロジェクトJupyter Notebookを開始しました。このプロジェクトの目標は、プログラミング言語から完全に独立したインタラクティブシェルを作成することです。 また、 クラウドに焦点を当てたデータサイエンティスト向けの対話型シェルツールの方向性を開発しているDataBricks 、 Beakerは 、この方向に積極的に取り組んでいます。 Jupyter Notebookに加えて、 Spark Notebookなどの他の同様のツールがあります。
したがって、 Apache Zeppelinは、ビッグデータおよび機械学習を操作するための対話型シェルの方向性の代表の1つです。
Zeppelinの作成作業は、2012年から2013年に韓国のソフトウェア会社NFLabsの腸内で開始されました(システム開発者による作成の詳細な履歴はこちら )。
当初、目標は、Hive、Presto、SharkなどのようなさまざまなSQL over Hadoopシステム用のユーザーインターフェイスを作成することでした。 その後、SQLに限定されない大規模プロジェクトでData Scientistが連携するためのより強力なツールを作成する必要があることが明らかになりました。 したがって、Apache Sparkフレームワークとの組み込み統合が実装され、WEBを介してNotebookで機能するようになりました。
Apache Zeppelinの機能:
- インタラクティブコンソール、SQLデータアクセス、Scala、JavaなどへのWEBアクセス。
- 分析および視覚化の結果をノートブック(ノートブック)の形式で保存する概念。
- さまざまなタイプのグラフを使用したデータの視覚化。
- ピボットテーブルの機能
- 特別な形式(動的形式)でのクエリパラメータの動的設定。
- Interpreter APIを使用して、他のランタイム環境、SQLバックエンドを接続する機能。
Apache Zeppelinをインストールする
Apache Zeppelinのシステム要件とインストール手順は、 GitHubのプロジェクトページまたはプロジェクトの Webサイトで入手できます。
クライアントマシンでVagrantを使用して、Apache Zeppelin環境を構成できます。
1. github.com/arjones/vagrant-spark-zeppelin
2. github.com/felixcheung/vagrant-projects
またはdocker:
hub.docker.com/r/internavenue/centos-zeppelin/~/dockerfile
私の作品では、Vagrant +ソースからの手動コンパイルを使用しました。 提案された方法のいずれかを選択できます。
Apache Zeppelin + Oracleバンドルの構成
リンクを介してOracleからJDBCドライバー(たとえば、ojdbc7.jar)をダウンロードし(サイトへの登録が必要)、CLASSPATHパスに沿ってドライバーをアップロードします。 Apache Zeppelinの場合、ドライバーファイルをルートディレクトリ(/ usr / zeppelin)にアップロードします。 Apache Sparkの場合-SPARK_HOME / lib(理論的には、 依存関係ローダーを使用してjdbcドライバーを動的にロードできますが、SparkContextでクラスを表示できませんでした)。
ojdbc7.jarを使用するには、アプリケーションの起動時にタイムゾーンを構成する必要があります。 次のようなエラーが発生した場合:ORA-01882:タイムゾーン地域が見つかりません。データにアクセスしようとすると、Apache Zeppelin設定ファイル/usr/zeppelin/conf/zeppelin-env.shでサーバーにインストールされた値を追加する必要があります。タイムゾーン。 たとえば、次のようになります。ZEPPELIN_JAVA_OPTS -Duser.timezone = UTC
試行番号1
Oracleへの最初のアクセスは、Apache Spark環境から行われました。 バージョンSpark 1.3以降、 Spark SQLデータソースAPIを使用してデータベースを操作することをお勧めします 。 データベースに接続するためのデータベースアクセスURL、テーブル/データセット、およびjdbcドライバーを指定します。 どのフィールドが選択可能かを確認し、registerTempTable()プロシージャを使用して、SQLContextの環境でテーブルとしてデータセットをメモリにロードします。その後、データソースに対してクエリを実行できます。
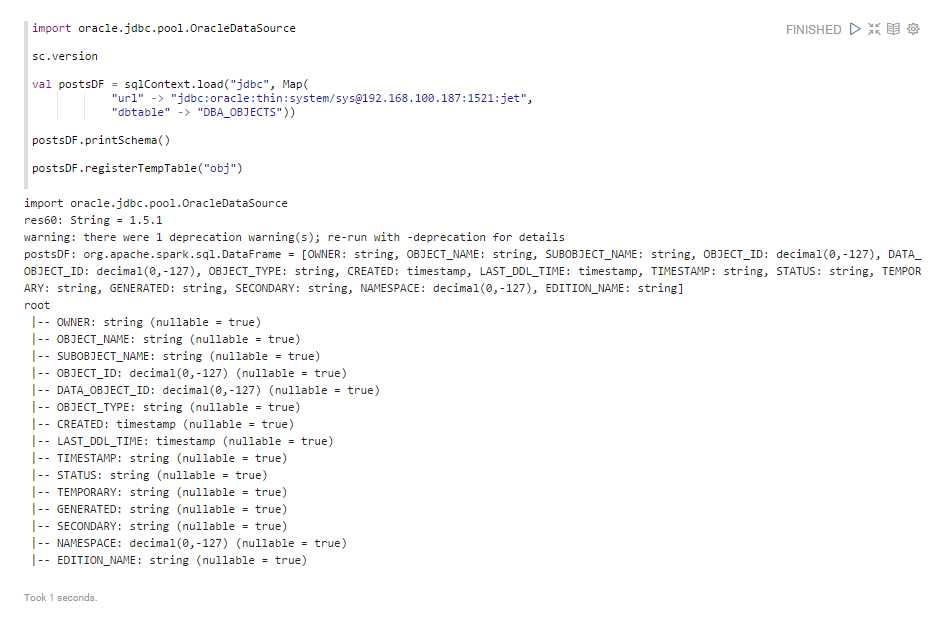
これで、すべてがOBJテーブルでクエリを実行する準備ができました。
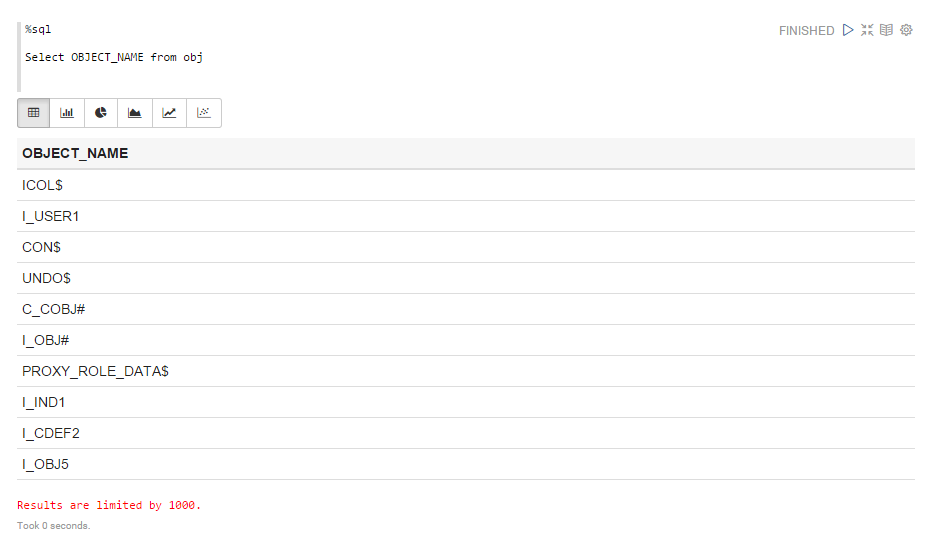
残念ながら、Apache SparkでのOracleデータへのフルアクセスは機能しません。 データ型がNUMBERのデータを選択しようとすると、次のエラーが表示されます。

この問題は、Apache SparkプロジェクトのJIRAに記載されており、説明されています。OracleNUMBER型の列でSpark sql jdbcが失敗する
それぞれ完全に直接解決策はありませんが、Apache SparkでOracle DBMSデータを操作するのは簡単ではありません。 回避策として、NUMBERをVARCHAR2に変換するビューをOracle DBMSで作成し、それらを使用してApache Sparkから作業することができます。 しかし、これらは管理、権限の付与などに関する追加の困難です。
試行番号2
Spark経由ではなく、Oracle DBMSに直接アクセスしてみましょう。 開発者は、これらの目的のために、インタープリターと呼ばれる拡張システムを思い付きました。 Oracleデータベース用の個別のプラグインはまだありません。 しかし、Postgresqlでreadyを使用しようとします-結局それはJDBCです。 psqlの[インタープリター]タブで、Zeppelinインターフェイスに必要な変更を加えます。
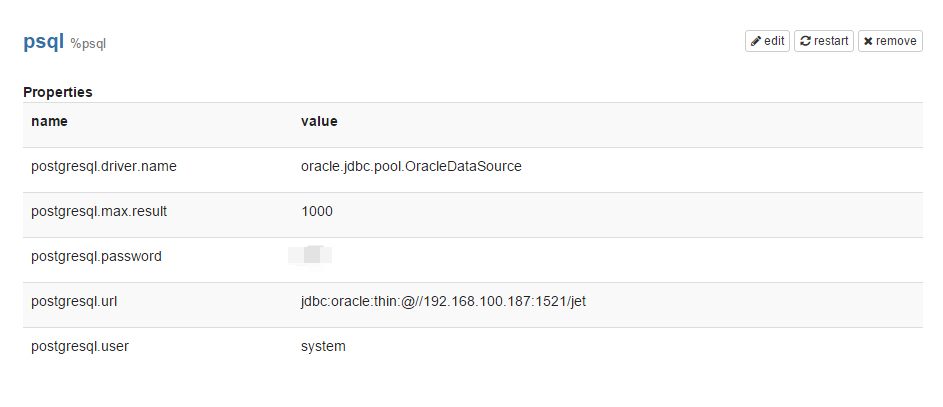
そして、テストリクエストを実行してみてください:

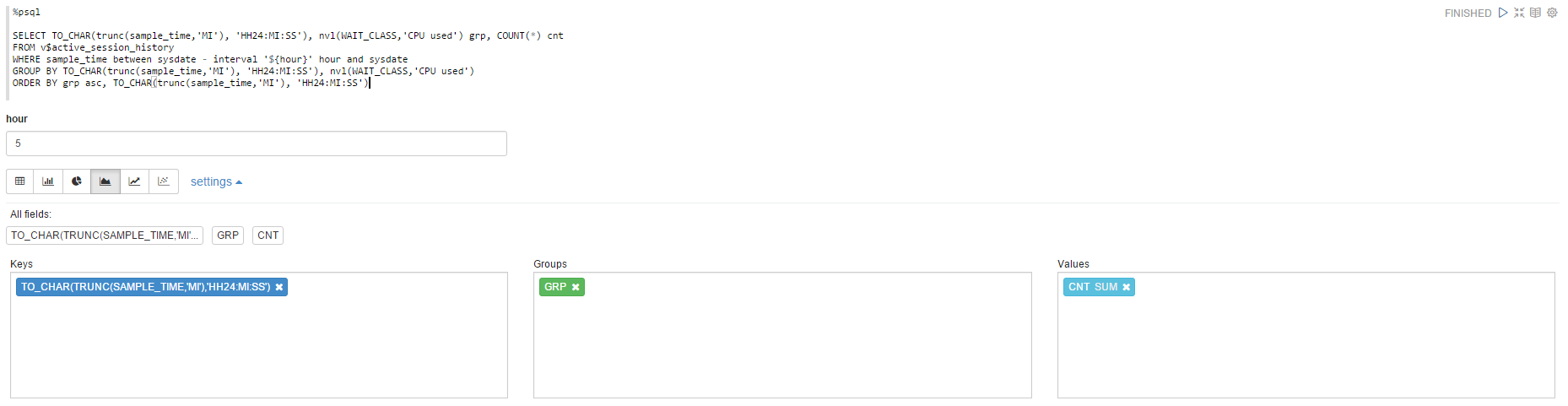
アクティブなセッションの履歴からデータを視覚化してみましょう:
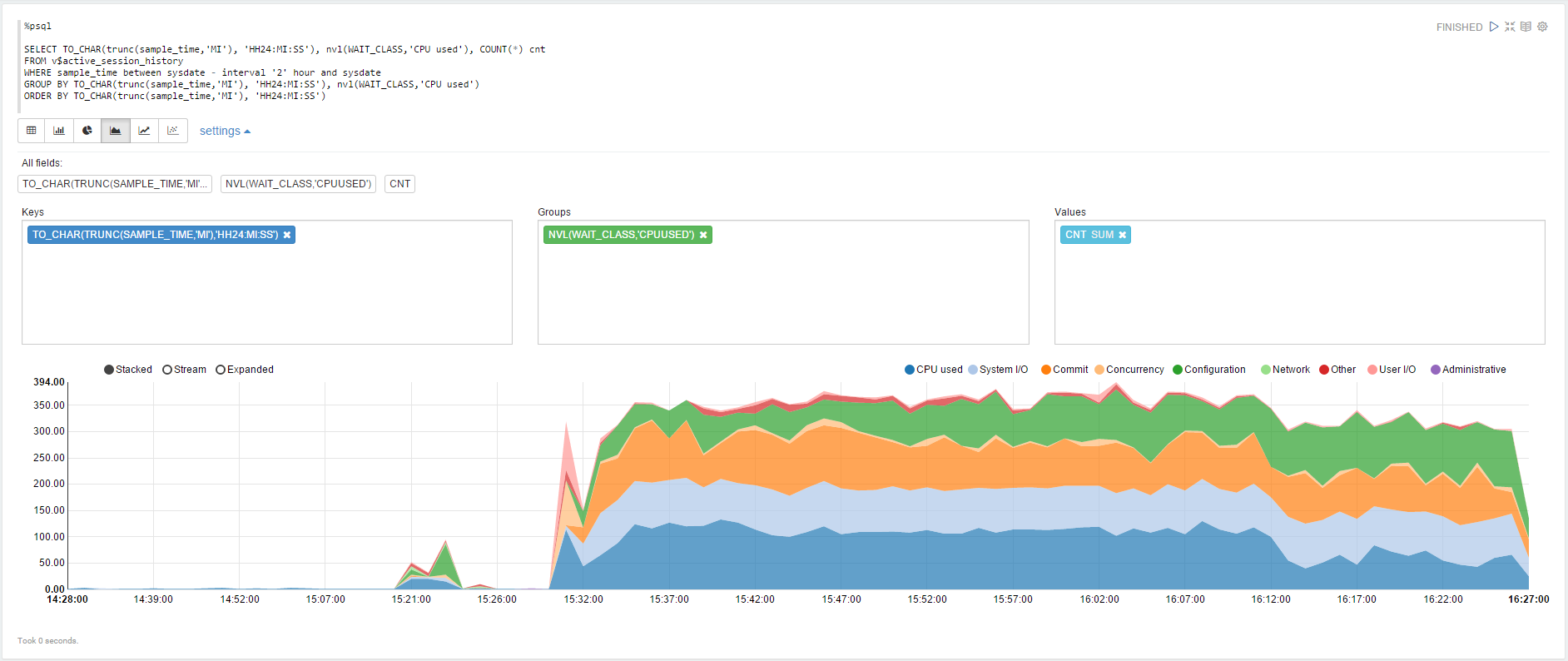
同じですが、 動的フォームを使用して、選択したデータの範囲を変更します。
また、アカウントのツイート統計など、動的に更新されたページを試すこともできます。 グスタボ・アルジョンスによるTwitterからのツイートのキャプチャー
フィードにアクセスするためのアプリケーション設定を指定します。
魔法を行うコード自体:

別のウィンドウでフィードのツイートの統計を動的に更新します:
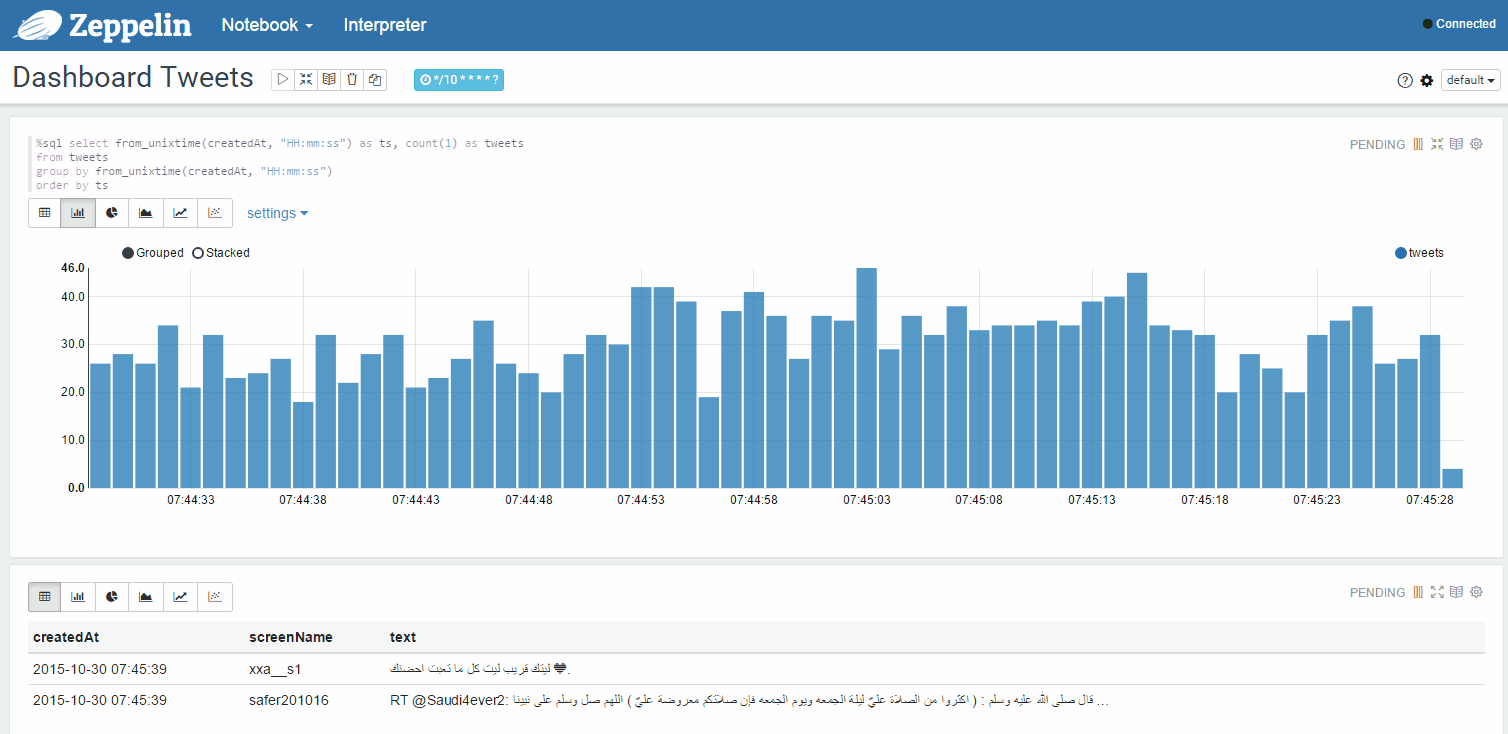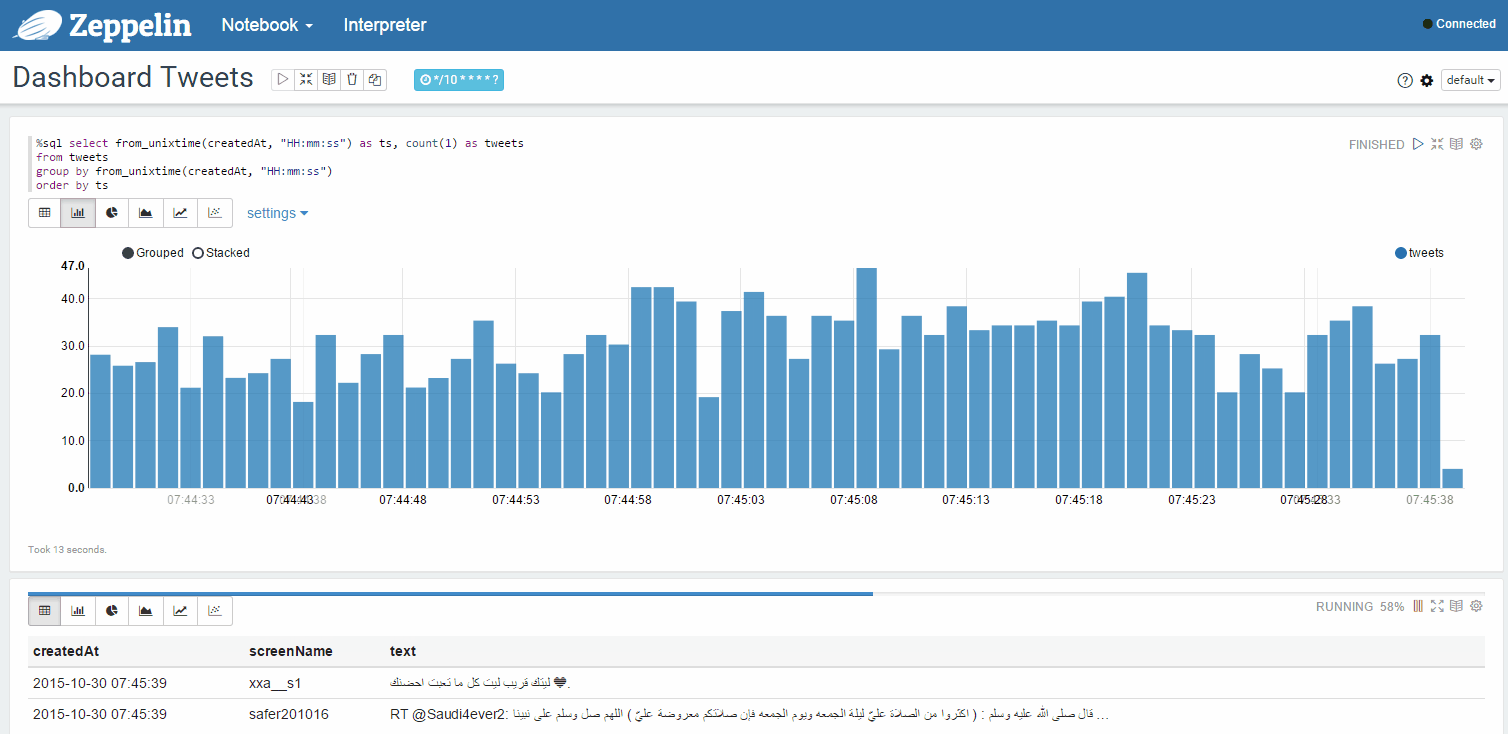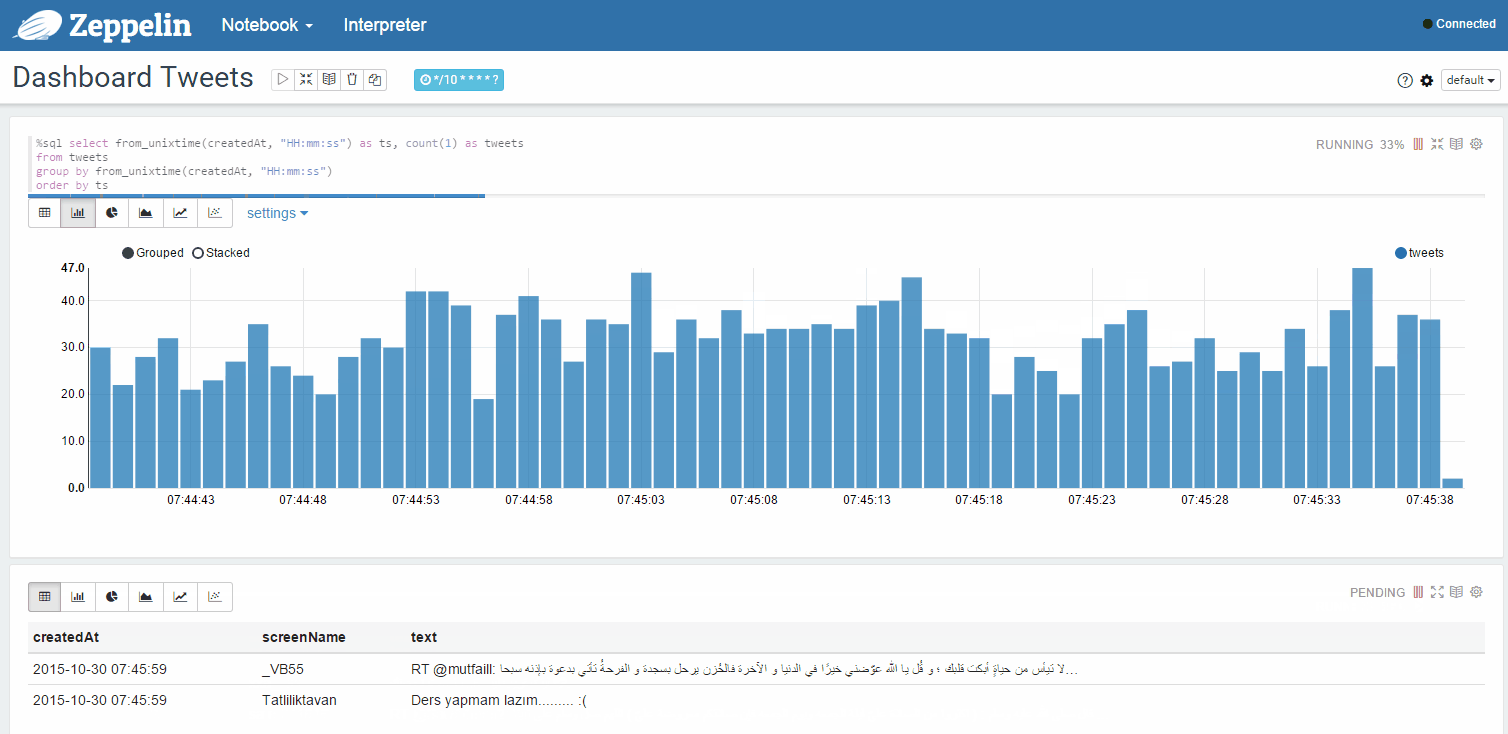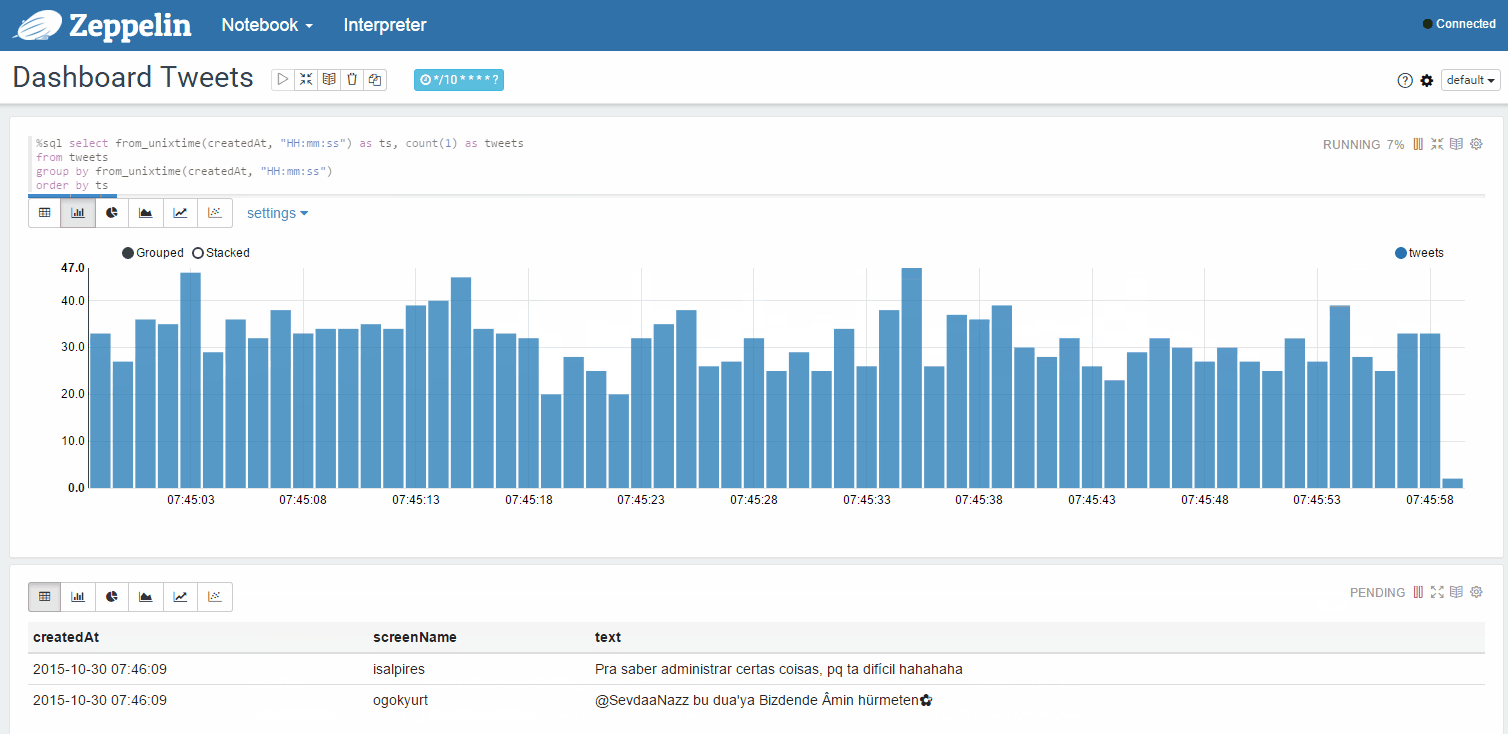
可能なユースケース(オプション):
- アドホックリクエスト用のレポートジェネレータ。
-ITシステムの主要な指標のためのシンプルな監視および観測システムのための柔軟でカスタマイズ可能な環境の作成。
短所:
-開発者コミュニティはまだ未発達です。 Jupiter Notebookと比較したApache Zeppelinのコードライターの数。
-チャートタイプのセットはまだ小さく、競合他社はより豊富です。
-わずかなバグがありますが、基本的な機能を使用して、手間をかけずに完全に干渉することはありません。 「うまくいく」
Apache Zeppelinは、Big Dataでクエリを実行し、Machine Learningと連携して結果の視覚化とチーム開発を行うための対話型シェルです。
データ量の増加に関連して、新しい知識を見つけるための新しいタスクには、研究者が作業に便利なツール(環境)が必要です。 インタラクティブシェルのニッチは現在、有望な分野の1つです。2015年6月12日、注目すべき8つの新しいビッグデータプロジェクト、著者:Alex Woodie 。 私たちは興味深いトレンドを目の当たりにしています-ビッグデータの準備と分析、データサイエンティストの視覚化とコラボレーションのタスクを簡素化するハイブリッドソフトウェアシステムの出現です。 Apache Zeppelinが提供する便利な視覚化インターフェースは、DBAおよびDBA開発者にも役立ちます。
開発チームは、 Apache Incubatorプログラムの一環として、Apache Foundationの翼の下でパブリックドメインにコードを転送し、準備済みのノートブックをレイアウトするための専用ZeppelinHubポータルを作成する活動から判断して、製品を積極的に開発し、より多くのユーザーにリーチすることを計画しています
使用したソフトウェア:
ご清聴ありがとうございました!