
この記事(2つの部分で構成されます)では、Ciscoスイッチをスタックするための基本的な技術について簡単に説明します。 各タイプのスタック内のパケット伝送の一般的なアーキテクチャ、障害への応答、およびスループットの数値を理解してみましょう。 最初の部分では、StackWiseおよびStackWise Plusテクノロジーを見ていきます。 2番目の部分-StackWise-160、StackWise-480、FlexStack、およびFlexStack Plus。
スタック機能は誰も驚かないでしょう。 彼は、シスコを含むさまざまなメーカーのスイッチの多くのモデルに所属しています。 しかし、常にそうではありませんでした。 ネットワークテクノロジーの分野での私のキャリアの夜明け(2000年代半ばのどこか)で、シスコはそのポートフォリオで完全なスタックサポートを備えたスイッチを1つだけ持っていました。 これは、Cisco 3750スイッチのモデルであり、2950および3550に基づく擬似スタックは、その時点ではほとんど機能していませんでした。 当時、私は若い専門家として、シスコがスタッキングスイッチの問題にほとんど注意を払っていなかったことに非常に驚きました。 同時に、たとえば3comスイッチ(およそHPで購入)は当時非常に人気があり、多数のモデルのリストでスタッキングが十分にサポートされていました。 アライドテレシスもそうしました。 シスコ製品の支持者が、スタッキングが悪いことを私に説明したことも覚えています。このテクノロジーは実稼働環境では使用しないでください。 残念なことですが、正確な言葉遣いは覚えていませんが、安定性に関するもののようです。 当時のスタッキングの主な理由は、管理の簡素化であったことに注意する価値があります(いずれにせよ、当時はそのように思えました)。 つまり 2つ以上のデバイスを個別に構成する代わりに、スタックは1つの大きなスイッチを取得する機会を提供します。
時間が経ちました。 多くの人がスタッキングの利点を認識しています。 そして現在、ほとんどのシスコスイッチがこのテクノロジーをサポートしています。 現在、スタックについて言えば、アクセスレベル(通常のユーザーを接続する)でスタックを分離し、他のすべてのケースでスタックを分離する価値があります。
最初のケースでは、スタック上のスイッチを組み合わせる主な理由は、管理を簡素化するためです。 ある時点で、これはもはや関連性がなく、マーケティングの瞬間であるように思えました。 しかし、
他のすべての場合、私の意見では、スタックを支持する主な「目的」は、ネットワークで比較的安価なフォールトトレランススキームを編成する能力でした(ネットワークのコアレベルおよびサーバー機器の接続時)。 スタックにより、異なるスイッチに接続された物理チャネルを1つの論理チャネルに集約できます。 これにより、より多くの帯域幅(同時に複数のチャネルを廃棄するため)とフォールトトレランス(スタックスイッチの1つの障害がネットワークのシャットダウンにつながることはありません)だけでなく、場合によってはループを完全に放棄することも可能になります。 そして、それはSTPファミリーのプロトコルの使用から意味します。 つまり ネットワークトポロジを十分に単純化することにより、生活を簡素化します。
シスコの機器では、プラットフォームに応じていくつかのスタッキングテクノロジーが使用されます。 小さな発言。 古典的なスタッキングスキームを検討します。 VSSテクノロジーは舞台裏のままです。
| テクノロジー | プラットフォーム | スタック内のスイッチの数 | 総スタック帯域幅 | スタックキットの必要性 |
|---|---|---|---|---|
| スタックワイズ | 3750、3750G | 9 | 32 Gbps | いや |
| Stackwise plus | 3750-E、3750-X | 9 | 64 Gbps | いや |
| Stackwise-160 | 3650 | 9 | 160 Gbps | はい |
| Stackwise-480 | 3850 | 9 | 480 Gbps | いや |
| フレックススタック | 2960-S、2960-SF | 4 | 40 Gbps | はい |
| FlexStack Plus | 2960-X、2960-XR | 8 | 80 Gbps | はい |
スタックワイズ
StackWiseテクノロジーを検討してください。 彼女は残りの中で最も古いです。 StackWiseテクノロジーを使用して、専用のスタックケーブルを使用してスイッチをスタックに接続します。 同時に、個別のスタックモジュールはありません;スタックポートはすぐにスイッチに組み込まれます(それぞれ2つのポート)。

16 Gb / sスタックケーブル帯域幅(各方向)。 各スイッチには2つのスタックポートがあるため、スタックバスのスループットは次のようになります。
16 Gbps * 2(各方向)* 2(ポート数)= 64 Gbps
仕様を見て、32 Gb / sがあります。 帯域幅の半分はどこに行きましたか?
3750(3750v2)および3750Gスイッチには、専用の内部スイッチングファクトリはありません(古い共有リングスイッチファブリックアーキテクチャを使用)。 スタックポートは、スイッチの内部バスに直接接続され、スイッチの継続になります。 したがって、1つのスタックのスイッチには、リングの形の1つの大きなバスがあります。 論理レベルのこのバスは、それぞれリングの形の2つのパスを表します。
それぞれの帯域幅は16ギガビット/秒です。 これらのパスは多方向です。パス上のパケットは反対方向に送信されます。 スタック全体に共通のバスがあるので、パケットは、スタックスイッチのポートに到着すると、すべての内部ASICだけでなく、発信ポートが着信スイッチと同じスイッチ上にある場合でも、スタックのリング全体を確実に通過します。 また、パッケージは、円全体を通過して戻ってきた場合にのみバスから削除されます。 これにより、パスの1つを「キャプチャ」したASICは、パケットが到着し、パスを解放できることを確認できます。 このような操作のアルゴリズムは、「送信者による削除」と呼ばれます(Cisco-削除されたソースの観点から)。 パケットを送信するパスの選択は、それぞれの可用性に基づいて決定されます(トークンメカニズムが使用されます:トークンを持つASICはデータを転送します)。
これを例として見てみましょう(図2)。 この場合、パケットはスイッチポート(1)に到達すると、ASICに送られ、次にASICが青いパス(2)を選択します(たとえば、その時点では空いていました)。 さらに、青いパスに沿ったパケットはすべてのスイッチ(3)を通過し、最終的に宛先ポート(4)が配置されているスイッチに到達します。 スイッチは、ローカルポート経由でパケットのコピー(5)を送信します。 ただし、パッケージ自体は、最初に送信したASICに到達するまでスタックリングに沿って移動し続けます(6)(7)。 そこだけがスタックバスから削除されます。
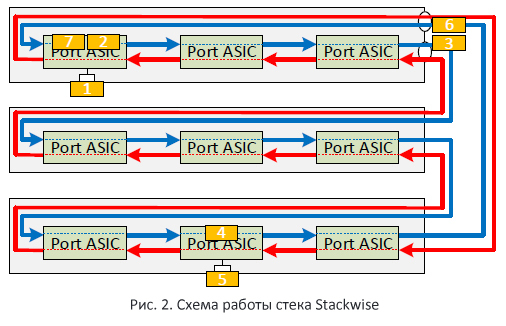
したがって、同じパケットがスイッチのスタックポートを2回通過します(最初は1つ、次に2つ目のポートを通過します)。 これは、スタックバスの合計有効帯域幅が32ギガビット/秒(物理帯域幅の2倍)であることを意味します。
そして、スタックスイッチの1つが故障するとどうなりますか? この場合、パスは互いに閉じており、それによって1つの大きなリングが形成されます(図3)。 スイッチは、スタックされたケーブルの1つが切断された場合にも動作します。
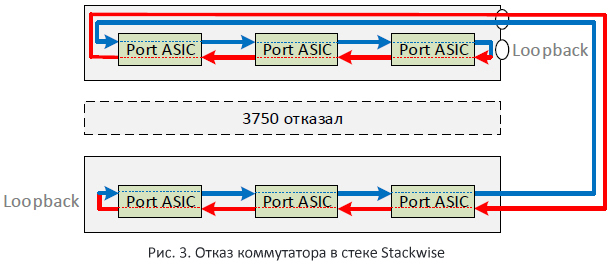
注目に値する他の2つのポイント。 2つの方法が異なる方向に「スピン」します。 これは、スタック内でパケットを送信する際の遅延を平均化するために行われると想定しています。 2番目のポイントは、スタック内のすべてのスイッチが同じ共有バスを使用するため、Stackwiseの場合、スタックバスのスループットはスタックの全体的なパフォーマンスに等しいということです。
Stackwise plus
StackWise Plusテクノロジーに移りましょう。 3750Eおよび3750Xには、専用のスイッチファブリックが追加されています。 これにより、スタックリングに表示されることなくローカルパケットスイッチングが可能になります。 スタックポートは、スイッチングファクトリに直接持ち込まれます。 現在、スイッチングファクトリは、スタックバスを操作するロジックを直接担当しています。 StackWiseテクノロジーの場合、各ASICはスタックバスで個別に動作しました。
StackWise Plusテクノロジーは、スタック上のパケットを処理するための新しいアルゴリズム-「受信者による削除」を使用しました(Ciscoの観点では、宛先の削除、空間再利用の別名)。 このアルゴリズムでは、パケットは、発信ポートが配置されているスイッチに到達するとすぐにスタックバスから削除されます(図4)。 これで、パスを解放できることを通知するために、小さなAckパケット(8ビット)が使用されます。

Stackwiseテクノロジーと同様に、論理的には2つのオプションがあります。 ただし、スイッチングファクトリがスタックリングの操作を担当するようになったため、これらのパスを操作するメカニズムはより複雑になりました。 前と同様に、特定のパスへのアクセスは、トークンメカニズムを使用して実行されます。 トークンを受信すると、スイッチングファクトリはスタックリングに沿ってパケットを送信できます。 また、パッケージは各ASICから直接取得されるため、クレジットメカニズムが各ASICのサービス手順を担当します。 これらは、スイッチングファクトリによって配布されます。
これらの革新により、スタックバスの帯域幅がマーケティング64 Gb / sに増加し、物理帯域幅と同等の帯域幅が確保されました。 これで、パケットはスイッチのスタックポートを1回だけ通過します。 両方のテクノロジー(StackwiseとStackWise Plus)が同じタイプのスタックケーブルを使用しているという事実に注目したいと思います。
スタックバスの帯域幅が64 Gb / sに等しくならないことを強調する価値があります。この数値を目指して努力し始めました。 なんで? その理由は、すべてのブロードキャスト、マルチキャスト、および未知のユニキャストトラフィックが、ソースストリップアルゴリズムを使用して引き続き処理されるためです。 つまり これらのタイプのトラフィックは、スタックバスから削除される前にリング全体を通過します。 これは、これらのタイプのトラフィックが2倍の帯域幅を消費することを意味します。
1つのスタックで任意の3750シリーズスイッチを使用できます。たとえば、3750v2(StackWiseをサポート)スイッチと3750X(StackWise Plus)スイッチを同じスタックに追加すると、スタックはStackWiseテクノロジー(ソースストリップアルゴリズム)を使用して機能します。 同時に、3750Xの場合、ローカルポート間のパケットスイッチングは、スタックバスに表示されることなく、スイッチ内でのみ実行されます。 3750v2スイッチの場合、ローカルポート間のパケットは通常どおりスタックバス全体を通過します。
プログラムレベルでスタックのスキームについて簡単に触れましょう。 StackWiseまたはStackWise Plusスタック内で、スイッチの1つがスタックマスターとして選択されます。 スタック全体に対して論理演算(コントロールプレーン)を実行します。 失敗した場合、ユニキャストトラフィックは継続します。 これは、ハードウェアテーブルを同期することで実現されます。 スタックスイッチ間では、MACテーブル、およびシスコエクスプレスフォワーディング(CEF)テーブル、つまりFIBと隣接テーブルが同期されます。 ただし、ルーティングテーブルやマルチキャストトラフィックの送信テーブルなど、残りのテーブルは新しいウィザードで再入力されます。 この場合、NSF機能-ノンストップフォワーディングを使用できます。 つまり 新しいウィザードのコントロールプレーンは最初から始まります。
これについては中断することを提案します。 数日中に継続が表示されます。