この記事では、Hadoopに含まれるツールとツール、Hadoopのインストール方法、Hadoop用のMapReduceプログラムの開発手順と例について説明します。

Hadoopの一般情報
ご存知のように、MapReduceは2004年にMapReduceの記事「 大規模クラスターでのデータ処理の簡素化 」でMapReduceパラダイムを提案しました。 提案された記事にはパラダイムの説明が含まれていたため、実装はありませんでした-Yahooのプログラマー数人が、 nutch webクローラーの作業の一部として実装を提案しました。 Hadoopのストーリーについて詳しくは、 The Hadoopの歴史:4つのノードからデータの未来までの記事をご覧ください。
当初、Hadoopはまず、データを保存してMapReduceタスクを起動するためのツールでしたが、現在ではHadoopはビッグデータの処理(MapReduceの使用だけでなく)に何らかの関連があるテクノロジーの大きなスタックです。
Hadoopの主な(コア)コンポーネントは次のとおりです。
- Hadoop分散ファイルシステム(HDFS) -ほぼ無制限のボリュームの情報を保存できる分散ファイルシステム。
- Hadoop YARNは、MapReduceフレームワークを含む、クラスターリソースとタスク管理を管理するためのフレームワークです。
- Hadoop共通
Hadoopに直接関連するプロジェクトも多数ありますが、Hadoopコアには含まれていません。
- Hive-ビッグデータに対するSQLのようなクエリのためのツール(SQLクエリを一連のMapReduceタスクに変換);
- Pigは、高レベルのデータ分析プログラミング言語です。 この言語の1行のコードは、MapReduceタスクのシーケンスに変換できます。
- Hbase - BigTableパラダイムを実装する列データベース。
- Cassandra-高性能な分散キーと値のデータベース。
- ZooKeeper-分散構成ストレージおよびこの構成への変更の同期のためのサービス。
- Mahoutは、ビッグデータライブラリおよび機械学習エンジンです。
また、分散データ処理のエンジンであるApache Sparkプロジェクトについても言及したいと思います。 Apache Sparkは通常、HDFSやYARNなどのHadoopコンポーネントを使用して作業を行い、最近ではHadoop自体よりも人気が高まっています。
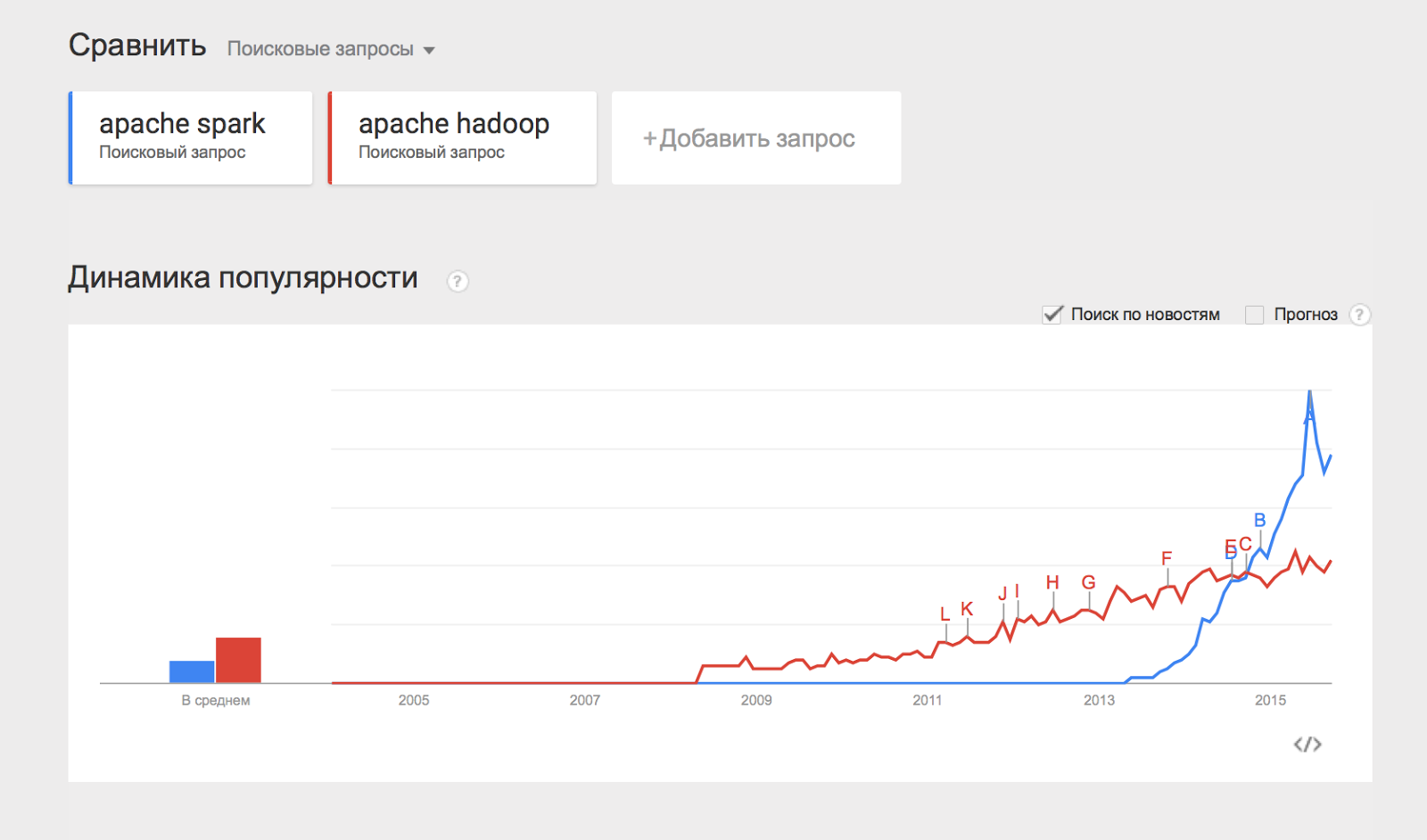
リストされたコンポーネントの一部は、この一連の資料の別の記事で説明しますが、ここでは、Hadoopでの作業を開始して実践する方法について説明します。
Cloudera Managerを使用してクラスターにHadoopをインストールする
以前は、Hadoopのインストールはかなり難しいタスクでした。クラスター内の各マシンを個別に構成し、忘れていないことを確認し、監視を慎重に構成する必要がありました。 Hadoopの人気が高まるにつれて、独自のHadoopアセンブリとHadoopクラスターを管理するための強力なツールを提供する企業( Cloudera 、 Hortonworks 、 MapRなど )が登場しました。 マテリアルサイクルでは、Cladodera Hadoopアセンブリを使用します。
クラスターにHadoopをインストールするには、いくつかの簡単な手順に従う必要があります。
- ここからクラスター内のマシンの1つにCloudera Manager Expressをダウンロードします。
- 実行権を割り当てて実行します。
- インストール手順に従ってください。
クラスタは、サポートされているLinuxファミリオペレーティングシステムのいずれかで実行する必要があります:RHEL、Oracle Enterprise linux、SLES、Debian、Ubuntu。
インストール後、インストールされたサービスの監視、サービスの追加/削除、クラスターステータスの監視、クラスター構成の編集ができるクラスター管理コンソールが表示されます。
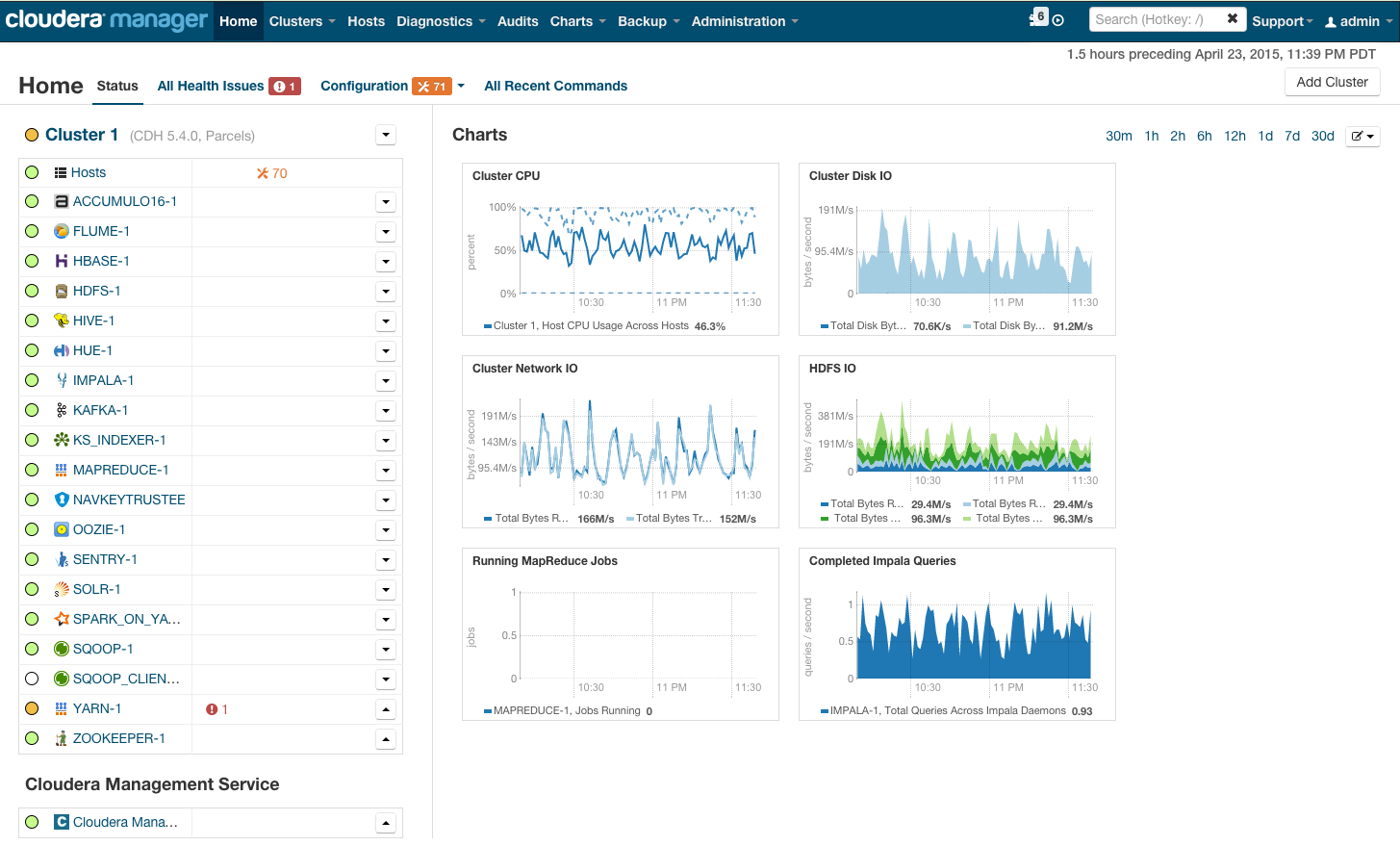
clouderaマネージャーを使用してクラスターにHadoopをインストールするプロセスの詳細については、「クイックスタート」セクションのリンクを参照してください 。
「試用」のためにHadoopを使用する予定がある場合は、高価なハードウェアを購入してHadoopを構成することはできませんが、 リンクから事前構成済みの仮想マシンをダウンロードして構成済みのhadoopを使用するだけです。
HadoopでMapReduceプログラムを実行する
次に、HadoopでMapReduceタスクを実行する方法を示します。 タスクとして、シリーズの前の記事で 説明した古典的なWordCountの例を使用します。 実際のデータを試すために、サイトlenta.ruからランダムなニュースのアーカイブを作成しました。 リンクからアーカイブをダウンロードできます。
問題の声明を思い出させてください 。文書のセットがあります。 文書のセットで出現する各単語について、単語がセットで出現する回数を計算する必要があります。
解決策 :
マップはドキュメントを単語に分割し、多くのペア(単語、1)を返します。
Reduceは、各単語の出現を要約します。
| |
ここでのタスクは、Hadoopで実行して実行できるコードの形式でこのソリューションをプログラムすることです。
メソッド番号1。 Hadoopストリーミング
HadoopでMapReduceプログラムを実行する最も簡単な方法は、Hadoopストリーミングインターフェイスを使用することです。 Streamingインターフェースは、mapおよびreduceが、 stdinからデータを受信し、結果をstdoutに出力するプログラムとして実装されていることを前提としています。
map関数を実行するプログラムはmapperと呼ばれます。 reduceを実行するプログラムは、 それぞれreducerと呼ばれます 。
ストリーミングインターフェイスは、デフォルトで、マッパーまたはリデューサーの1つの入力行がマップの1つの入力エントリに対応すると想定しています。
マッパーの出力はペア(キー、値)の形式でリデューサーの入力に送られますが、1つのキーに対応するすべてのペアは次のようになります。
- シングルランレデューサーによって処理されることが保証されています。
- それらは行の入力に送信されます(つまり、1つのレデューサーが複数の異なるキーを処理する場合、入力はキーごとにグループ化されます)。
そのため、Pythonでマッパーとリデューサーを実装します。
#mapper.py import sys def do_map(doc): for word in doc.split(): yield word.lower(), 1 for line in sys.stdin: for key, value in do_map(line): print(key + "\t" + str(value))
#reducer.py import sys def do_reduce(word, values): return word, sum(values) prev_key = None values = [] for line in sys.stdin: key, value = line.split("\t") if key != prev_key and prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + "\t" + str(result_value)) values = [] prev_key = key values.append(int(value)) if prev_key is not None: result_key, result_value = do_reduce(prev_key, values) print(result_key + "\t" + str(result_value))
Hadoopが処理するデータは、HDFSに保存する必要があります。 私たちの記事をダウンロードして、HDFSに載せてください。 これを行うには、 hadoop fsコマンドを使用します。
wget https://www.dropbox.com/s/opp5psid1x3jt41/lenta_articles.tar.gz tar xzvf lenta_articles.tar.gz hadoop fs -put lenta_articles
hadoop fsユーティリティは、ファイルシステムを操作するための多数の方法をサポートしています。その多くは、標準のLinuxユーティリティを1対1で繰り返します。 その機能の詳細については、 こちらをご覧ください 。
ストリーミングタスクを実行します。
yarn jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar\ -input lenta_articles\ -output lenta_wordcount\ -file mapper.py\ -file reducer.py\ -mapper "python mapper.py"\ -reducer "python reducer.py"
yarnユーティリティは、クラスター上のさまざまなアプリケーション(map-reduceベースを含む)を起動および管理するために使用されます。 Hadoop-streaming.jarは、このような糸のアプリケーションの一例です。
次は、起動オプションです。
- input-hdfs上のソースデータを含むフォルダー。
- output-結果を配置するhdfs上のフォルダー。
- file-map-reduceタスク中に必要なファイル。
- mapperは、マップステージに使用されるコンソールコマンドです。
- reduceは、reduceステージで使用されるコンソールコマンドです。
コンソールで開始した後、タスクの進行状況とURLを確認して、タスクに関するより詳細な情報を表示できます。
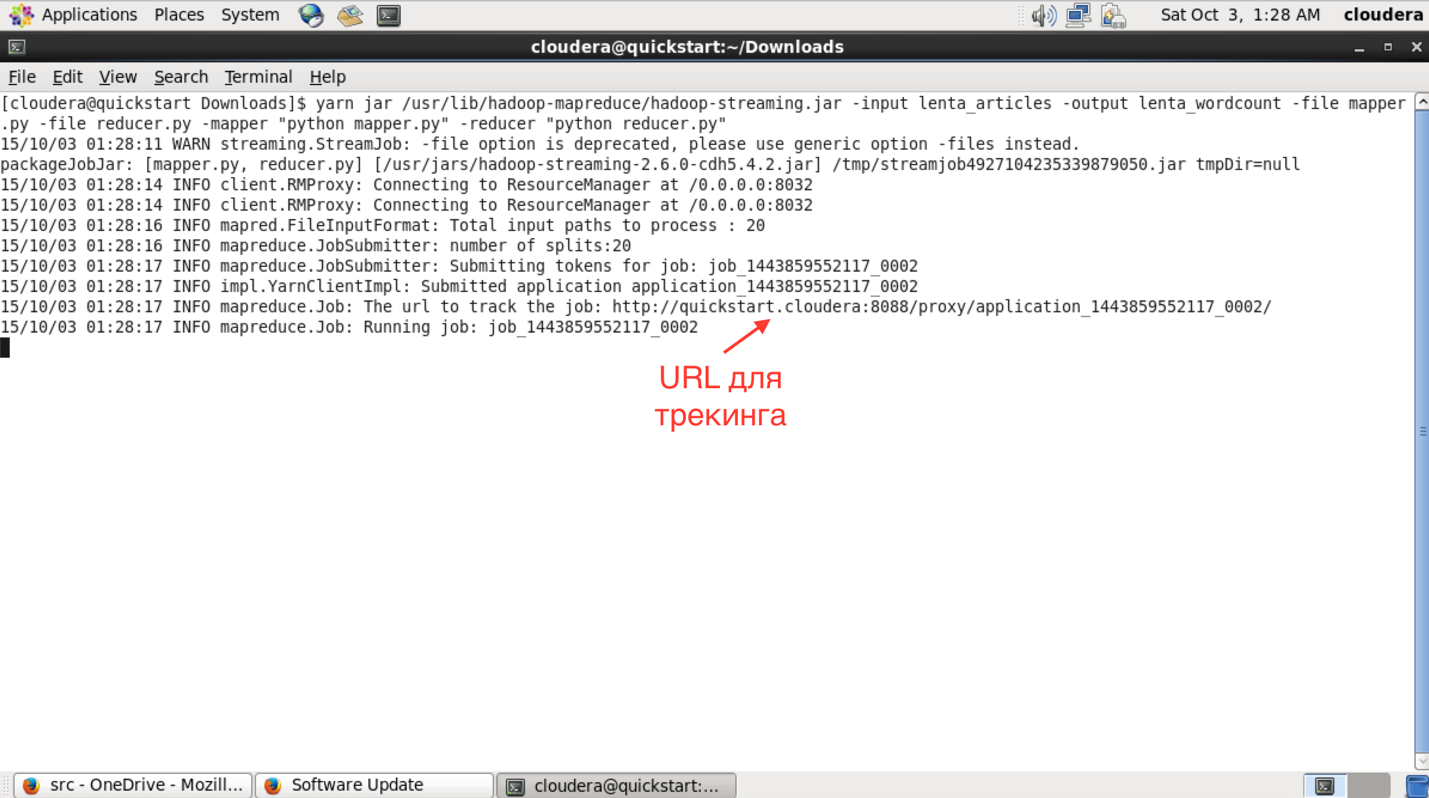
このURLでアクセス可能なインターフェイスでは、タスク実行のより詳細なステータスを確認でき、各マッパーとリデューサーのログを確認できます(タスクが落ちた場合に非常に役立ちます)。
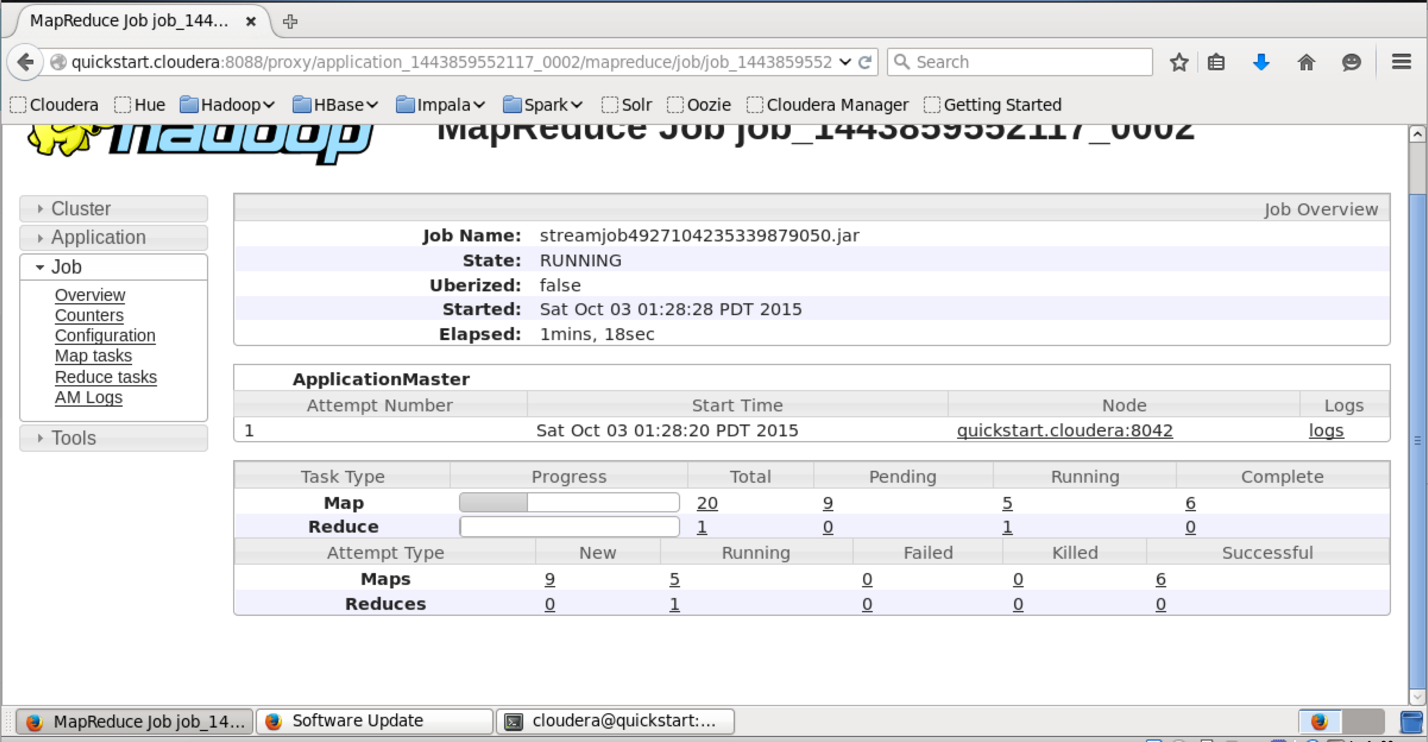
正常に実行されると、作業結果がHDFSで出力フィールドで指定したフォルダーに追加されます。 「hadoop fs -ls lenta_wordcount」コマンドを使用して、その内容を表示できます。
結果自体は次のようにして取得できます。
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 41 43 82 111 194
「hadoop fs -text」コマンドは、フォルダーの内容をテキスト形式で表示します。 結果を単語の出現回数でソートしました。 予想どおり、言語で最も一般的な単語は前置詞です。
メソッド番号2
Hadoop自体はJavaで記述されており、hadoop-aのネイティブインターフェイスもJavaベースです。 wordcountのネイティブJavaアプリケーションがどのように見えるかを見てみましょう。
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://localhost/user/cloudera/lenta_articles")); FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost/user/cloudera/lenta_wordcount")); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
このクラスは、Pythonの例とまったく同じことを行います。 TokenizerMapperクラスとIntSumReducerクラスを作成し、それぞれMapperクラスとReducerクラスから継承します。 テンプレートパラメータとして渡されるクラスは、入力値と出力値のタイプを示します。 ネイティブAPIは、マップ関数にキーと値のペアが提供されることを意味します。 この場合、キーは空なので、キータイプとしてObjectを定義するだけです。
Mainメソッドでは、mapreduceタスクを開始し、そのパラメーター(名前、マッパー、リデューサー、HDFSのパス、入力データの場所、結果の配置先)を決定します。
コンパイルには、hadoopライブラリが必要です。 Mavenを使用してビルドします。clouderaにはリポジトリがあります。 設定手順はリンクにあります。 その結果、pom.xmpファイル(プロジェクトアセンブリを記述するためにmavenによって使用されます)、私は次のようになりました):
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0-cdh5.4.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>2.6.0-cdh5.4.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.0-cdh5.4.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-app</artifactId> <version>2.6.0-cdh5.4.2</version> </dependency> </dependencies> <groupId>org.dca.examples</groupId> <artifactId>wordcount</artifactId> <version>1.0-SNAPSHOT</version> </project>
プロジェクトをjarパッケージで収集しましょう。
mvn clean package
プロジェクトがjarファイルに組み込まれた後、ストリーミングインターフェイスの場合と同じように起動が行われます。
yarn jar wordcount-1.0-SNAPSHOT.jar WordCount
実行を待って結果を確認しています:
hadoop fs -text lenta_wordcount/* | sort -n -k2,2 | tail -n5 41 43 82 111 194
ご想像のとおり、ネイティブアプリケーションの実行結果は、以前の方法で起動したストリーミングアプリケーションの結果と一致します。
まとめ
この記事では、ビッグデータを操作するためのソフトウェアスタックであるHadoopを調べ、clouderaディストリビューションの例を使用してHadoopのインストールプロセスを説明し、ストリーミングインターフェースとネイティブHadoop APIを使用してmapreduceプログラムを作成する方法を示しました。
シリーズの以下の記事では、HadoopおよびHadoop関連ソフトウェアの個々のコンポーネントのアーキテクチャをより詳しく調べ、MapReduceプログラムのより複雑なバージョンを示し、MapReduceでの作業を簡素化する方法、およびMapReduceの制限とこれらの制限を回避する方法を検討します。
ご清聴ありがとうございました。ご質問にお答えします。
データ分析に関する著者のYouTubeチャンネル
シリーズの他の記事へのリンク:
パート1:ビッグデータを扱う原則、MapReduceパラダイム
パート3:MapReduceアプリケーションの方法と開発戦略
パート4:Hbase