ハブラーのトライについてはすでに書いた 。
配列マッピングされたトライ構造
Trieは文字列を保存することが多いため、要素を構成できるアルファベットの概念があります。 x32で最適化するには、アルファベットのサイズを32(0-31)に制限します。
配列マッピングされたトライがどのように見えるかを見てみましょう。それはAMTです([1]から取得):

AMTは、ノードと、ノードと他のノードを接続するいくつかのセグメントで構成されています。 各セグメントは、アルファベットの可能な文字の1つを表します。
ノードには32ビット構造(ビットマップ)が格納され、構造の各ビットは32セグメント(0-いいえ、1-そこ)のいずれかの状態を反映します。 また、ノードには、サブツリーへのポインターまたは指定されたサブストリング(葉)の最後の文字を格納するテーブルがあります。 テーブル内のポインターは順番に保存され、各ポインターはビット構造のビット= 1に対応します。
例:文字「s」を見つけるには、ビット構造を介して対応するビットに移動する必要があります。 構造に沿って進みながら、ビット= 1(コックされたビット)をカウントします。 5つのコックされたビットをカウントし、「s」に対応するビットが6番目のコックされたビットであることが判明したとします。 したがって、このノードのテーブルに6番目のポインターが必要です。 ビットが未設定(= 0)であることが判明した場合、このシンボルは未設定です。
ハッシュ配列マッピングのトライ構造
それでは、 HAMTに進みましょう。 アルファベットの代わりに、ハッシュの上位ビットが使用されます。 HAMTは次のようになります([1]から引用):
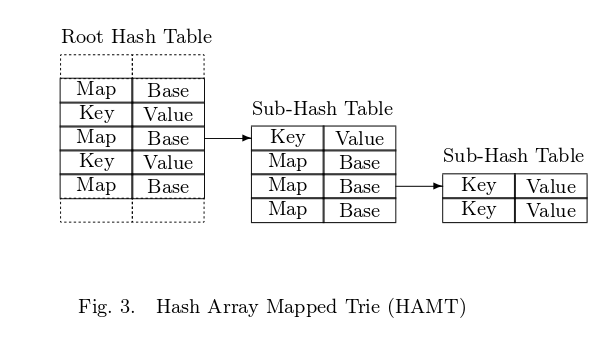
HAMTは、サイズ2 ^ tのメインハッシュテーブルで構成されます。通常、t> = 5です。メインテーブルの各要素は次のとおりです。
1.サイズ32のサブテーブルツリーのルートノード
Index Node: int bitmap (32 bits) Node*[] table (max length of 32)
2.キーと値のペアのいずれか
Key Value Node: K key V value
ハッシュ関数の選択は、データセットによって異なります。 衝突の最小数を与えるハッシュ関数を選択することをお勧めします(衝突については[2]を参照)。
要素検索
1.キーの32ビットハッシュを生成します。
2.生成されたハッシュから、上位ビットを取得し(注:上位ビットを初めて取得し、残りは各5ビット)、それらをテーブルのインデックスとして使用します。 次の3つのオプションがあります。
a)そのようなインデックスを持つセルには何もありません-テーブルにはそのようなキーはありません;
b)セルに1つのキー/値のペアがあります。 キーが一致する場合-要素が見つかりましたが、一致しません-見つかりませんでした。
c)32ビットのビットマップとポインターを含むテーブルがセルに保存されます。 この場合、ハッシュの次の5ビットを取得し、ビットマップのインデックスとして再び使用します。 ビットがコックされていない場合、そのようなキーはありません。コックされている場合、最初から現在までのすべてのコックされたビットを考慮します(AMTのように)。 したがって、テーブル内の必要なポインターの数を取得しました。 ポインタに従って、アルゴリズムを繰り返します。
多くの場合、このアルゴリズムの数回の反復のみが必要です(ただし、これはツリーの完全性に依存します)。 キーは一度だけ比較されます-状況にあるときb。 キーの不足は早すぎる時期に検出されます。
アイテムを挿入
3つの状況のいずれかが発生するまで、挿入アルゴリズムからの手順を繰り返します。
a)そのようなインデックスを持つセルには何もありません。
b)32ビットのビットマップとポインターを含むテーブルがセルに保存されます。
どちらの場合も、アルゴリズムは単純です。メインテーブルで挿入が発生した場合、キー/値のペアを挿入するだけです。 サブテーブルで挿入が発生した場合、対応するビットをコックし、ポインターの新しいテーブルを割り当て、古いテーブルからポインターをコピーし、ペアに新しいポインターをコピーして、古いテーブルを削除します。
その結果、対応するセルの新しいポインターだけでなく、すべての古いポインターのポインターのテーブルで、対応するセルのビットをコックしました。
c)衝突が発生した-つまり、2つのハッシュの一部が一致した。 解決策は簡単です。新しいサブテーブルを作成し、既存のキーからハッシュを計算し、次の5ビットを使用して目的のセルを見つけます。 このセルに少しコックし、ポインターのテーブルに既存のキー/値のペアへのポインターを挿入し、挿入したペアに戻り、次の5ビットを取得して、目的のセルを探します。 衝突がなくなるまで、新しいサブテーブルを作成してこの手順を繰り返します。
このような各ステップで、衝突の可能性は32倍(ポインターテーブルとビットマップのサイズ)減少します。
完全な衝突が発生する場合があります-2つの異なるキーのハッシュの32ビットはすべて同じです。 次に、次のハッシュ関数を使用して、2つの競合するキーでハッシュします。 その結果、キーで要素を探すとき、プライマリハッシュのすべてのビットを調べ、シートではなくサブテーブルに到達したことを確認し、2番目の関数を使用して新しいキーハッシュを計算します。
一般に、これは競合を解決する唯一の方法ではありません;異なる実装には他のものがあります。 彼の作品の著者は、衝突直後に同じハッシュ関数を使用して、キーとアルゴリズムのこのステップにあるツリーのレベル(0-ルートテーブルなど)を与えることを提案しています。 挿入操作の時間を上から制限することがアプリケーションにとって重要な場合(理論的には、再ハッシュ関数への複数の呼び出し後にハッシュが一致するようなキーを2つ取ることができます。つまり、挿入操作は非常に長い時間続きます)キー自体を使用できます。
メモリ割り当て
1〜32要素のプールが必要です(さまざまなサイズのテーブル用)。 メモリブロックを選択し、対応するテーブルに分割します。 その過程で、断片化は徐々に増加します。 記憶を取り戻すには、デフラグを実行する必要があります。 断片化されたメモリの量に制限をパーセントで設定し、要素が挿入されたときにそれを確認し、制限を超えた場合は最適化することができます。 デフラグ操作は、O(1)操作として実装できます。
ルートテーブルのサイズを変更する
ある時点で、ツリーが大きく成長するので、ルートテーブルのサイズを大きくすると、速度が著しく向上します。 各サブテーブルには32個の要素があるため、最も論理的な変更は2 ^ tから2 ^(t + 5)になります。 サイズが大きくなると、最初のレベルのすべてのサブテーブルがルートテーブルに分類されます。 さらに、再ハッシュは、ルートテーブルにツリーの葉がある場合にのみ必要です(要素の新しい位置を決定するためにハッシュを再計算する必要があります)。 それ以外の場合は、要素をサブテーブルからルートテーブルにコピーするだけです。
すべてのサブテーブルをすぐにルートテーブルにコピーするのではなく、徐々にコピーすることができます。 この場合、転送インデックスが保存されます。 インデックスの下のすべての要素が新しいテーブルにコピーされ、インデックスは徐々に古いテーブルを移動します。 検索中に、ハッシュの最初のtビットがキャリーインデックスと比較されます。ハッシュが大きい場合、検索は古いテーブルに送信され、そうでない場合は新しいテーブルに送信されます。 挿入アルゴリズムでは、キャリーインデックスも考慮する必要があります。
ルートテーブルを増やす価値があるのはいつですか? 新しいテーブルのサイズがツリー全体の1 / fを占めるとき。 パラメーターfは、特定の状況に基づいて選択する必要があります。
必要なメモリの量
メモリの量は、転送インデックスによって異なります。 著者は、この依存関係を示す表を引用しています([1]から引用)
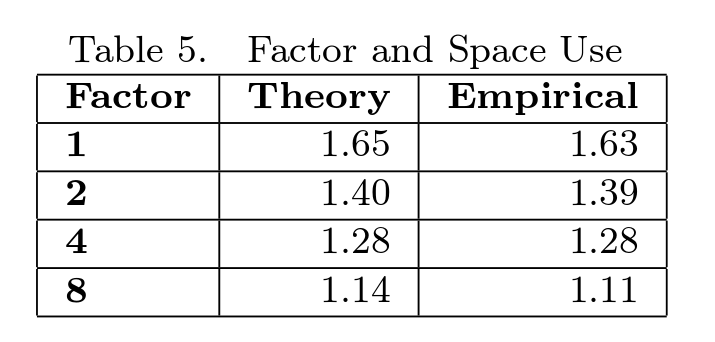
つまり、転送インデックスがN / 4の場合(Nはツリーに挿入されたキーと値のペアの数)、占有メモリは1.28 * Nに比例します。
アイテムを削除
削除中に発生する可能性がある2つの状況があります。
a)サブテーブル内の要素の数が2より大きい要素を削除します。次に、他のすべての要素をより小さいサブテーブルに移動し、現在のサブテーブルを空にする必要があります。
b)要素の数が2に等しいサブテーブルの要素を削除します。この状況では、残りの要素は1レベル上のサブテーブルに単純に転送され、現在の要素は空としてマークされます。
ソースコード
著者からCへの実装リンクを失いました((だれでも見つけられる-コメントに書いてください。
github.com/yasm/yasm/blob/master/libyasm/hamt.cはCでの実装例です。他の言語での実装例へのリンクは[3]にあります。
参照資料
[1] アルゴリズムの著者からの記事
[2] ウィキペディアのハッシュ衝突に関する記事
[3] HAMTウィキペディアの記事
[4] SOに関する良い質問
[5] HAMTの短い入門コース
コメント、不正確なコメント、スペルミス、および句読点の紛失をPMに送信します。