メモリメトリックは、VTune Amplifierで長い間利用されてきました。 新しいタイプの分析であるメモリアクセスは、それらを1か所に集めただけでなく、いくつかの重大な改善も加えました。
他のタイプの分析では以前のものでした:
- すべてのレベルのキャッシュの欠落
- ローカルランダムアクセスメモリ内のトラフィックデータ(DRAM帯域幅)
- NUMAマシン上のローカルおよびリモートRAMへの呼び出しの数
Intel VTune Amplifier XE 2016で導入されたもの:
- データオブジェクトの追跡
- NUMAマシン上のリモートRAMへのトラフィックに関するデータ(QPI帯域幅)
- メモリへのアクセスまたはアプリケーションオブジェクトからのデータのロードのための命令の平均実行時間(平均レイテンシ)
そこで、メモリアクセスの分析を開始し、すぐにデータオブジェクトの追跡をオンにします。 この機能は現在、Linuxでのみ利用可能です。
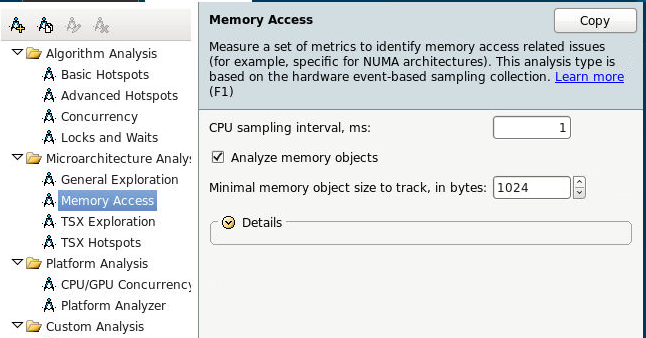
または、コマンドラインから:
amplxe-cl -c memory-access -knob analyze-mem-objects=true -knob mem-object-size-min-thres=1024 -- ./my_app
メモリサブシステムメトリック
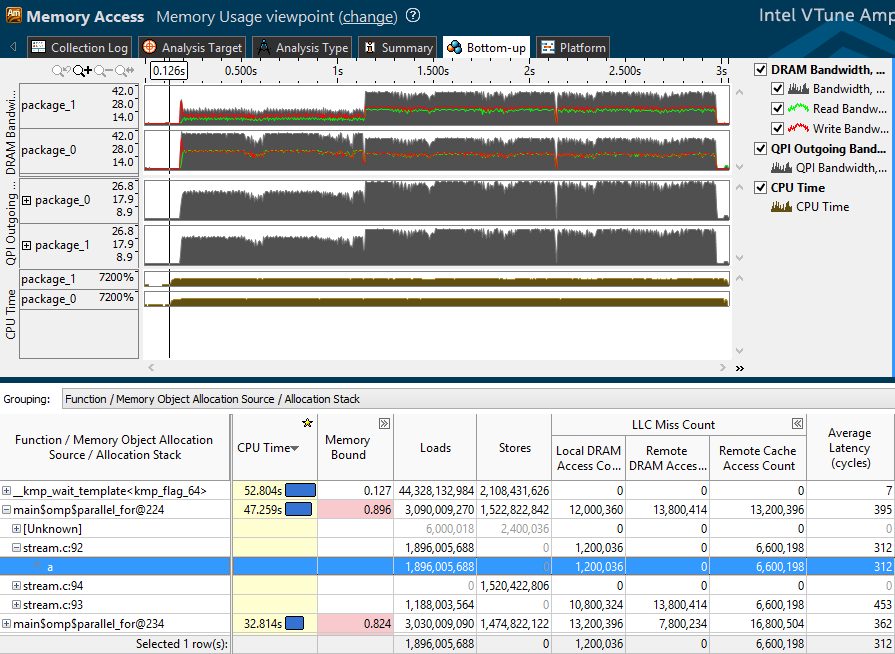
それでは、ストリームベンチマークのプロファイリング後に取得したプロファイルを見てみましょう。 アプリケーションによって生成されたトラフィックは、ボトムアップウィンドウの上半分に反映されます。
- DRAM帯域幅-各ソケット(パッケージ)のローカルRAMへの読み取り(緑色)、書き込み(赤色)、および一般的なトラフィック。
- QPI発信帯域幅-あるソケットから別のソケットへの発信トラフィック。
以下の表は、主要なハードウェアメトリックとメモリアクセスカウンターを示しています。
- 平均遅延-メモリアクセス命令の実行またはアプリケーションオブジェクトからのデータのロードに費やされたプロセッササイクルの平均数。 この統計値は、短い測定では不正確になる場合があります。 ただし、値が大きい場合は、他のメトリックに注意する必要があります。
- LLCミスカウント-トップレベルキャッシュ(通常はL3)のミスの数-ローカルRAM、リモートRAM、およびリモートキャッシュへのアクセスに分割されます。 ダウンロードされたデータは、別のプロセッサのキャッシュにある可能性があります。
- ロードとストア-実行されたデータ読み取りおよび書き込み命令の数
- メモリバウンド-メモリ操作のパフォーマンスメトリック
メモリバウンドには、リモートおよびローカルRAMに対するヒット数の比率、およびトップレベルキャッシュ(LLC)のミスと同じカテゴリのメトリックが含まれます。

メモリバウンドメトリックは、イベント(LLCミスなど)の数とサイクルでの推定値を含む数式です。 メトリック値はいくつかの参照値と比較され、所定のしきい値を超えるとピンク色で強調表示されます。 出力では、ユーザーは注意すべき点についてのヒントを受け取ります-多数のキャッシュミスは、データオブジェクトの場所の非効率性を示している可能性があります。
データオブジェクト
メモリでの作業の問題は、以前は自分で計算する必要があったデータオブジェクトと密接に関連しています。 これで、メモリオブジェクトを使用してグループ化を選択し、ヒット、キャッシュミスなどの大半を占める特定のオブジェクトを確認できます。

同時に、オブジェクトの上にある関数をダブルクリックすると、目的のメモリ操作を実行したコード行が表示されます。

また、Memory Object Allocation Sourceでグループ化し、オブジェクト自体をダブルクリックすると、その作成場所を決定できます。
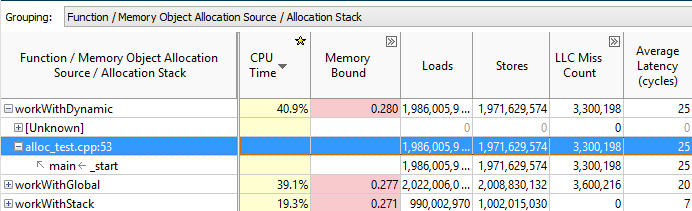
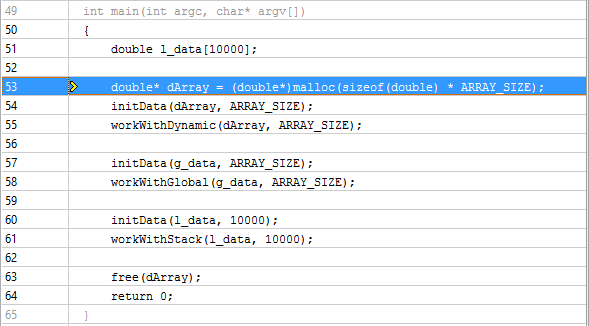
VTune Amplifierは、動的に作成されたCおよびC ++言語オブジェクトと、静的なC、C ++およびFortranオブジェクトを認識します。
NUMAの問題
NUMAマシンでは、リモートにアクセスするよりもローカルRAMにアクセスする方が高速です。 別のソケットのRAMは、ローカルRAMへのアクセスバスよりも遅いQPIバスを介してアクセスする必要があります。 RAMまたは別のソケットのキャッシュへの多数のアクセスが、平均レイテンシの高い値と相まって、アプリケーションデータの非効率的なローカライズを示している場合があります。 たとえば、グローバルデータオブジェクトがメインストリームで作成され、別のソケットで動作している可能性のある他のフローがアクティブにアクセスしている場合、データへのリモートアクセスによるプロセッサのダウンタイムが発生する可能性があります。 同様の問題は、さまざまなNUMA対応ライブラリを使用して、ストリーム内のホットデータのローカライズ、ストリームの固定の助けを借りて解決できます。
VTuneアンプでNUMAの問題を見つけることは、今では十分簡単です。 はじめに、リモートという言葉ですべてのメトリックを調べます。たとえば、リモート/ローカルDRAM比-リモートヒットの相対数です。

QPIトラフィックが高い機能とオブジェクトをフィルタリングできます。 Bandwidth Utilization HistogramのSummaryタブで、スライダーを動かして、低、中、高とみなす値を決定します。

ボトムアップでは、帯域幅ドメイン別にグループ化し、QPIの負荷が高いときに使用されたオブジェクト(または実行されたコード)を確認します。

従来、帯域幅分析の場合、トラフィックのスパイクはタイムライン上ではっきりと見えます。 そのようなセクションを選択し、フィルターします(右クリック、選択によるフィルターイン)。 次の表の関数のリストには、選択した時間間隔で実行されたコードのみが反映されます。

以下は、別のベンチマークであるIntel Memory Latency Checkerのプロファイル結果です。

選択したフラグメントには、ソケット1のローカルRAMからの大量の読み取りトラフィックと低い書き込みトラフィックがあります。つまり、 ソケット1はアクティブに何かを読み取っています。 また、ソケット1には大量の発信QPIトラフィックがあります。 彼は積極的に何かをソケット0に送信しています(他に誰もいません。2つしかありません。4つ以上のソケットがある場合は、UNIT、特定のQPIリンクによって方向を決定することもできます)。 同時に、ソケット0で高いプロセッサアクティビティがあります。 これはすべて、ソケット0がソケット1のRAMにあるデータにアクティブにアクセスすることを示唆しています。これは、テーブル内のリモートアクセス数に関するデータによってサポートされています。 次に、テーブルを関数のレベルに分解し、識別されたアクセスパターンを担当するコード内の特定の場所を見つけることができます。
まとめ
新しいタイプのメモリアクセス分析により、アプリケーションコードの実行がマシンのメモリの物理トポロジとどのように比較されるかを確認できます。 関係するメモリレベル(キャッシュ、DRAM、リモートDRAM)、メモリトラフィックの分散方法。 そして、最も重要なことは、長いメモリアクセス中に実行されたコードと、これらのアクセスが発生したデータオブジェクトです。
はい、そして誰も聞いたことがない場合-Intel Parallel Studioは、さまざまな非営利的なニーズのために無料でダウンロードできます-詳細はこちらです。