
DL_MESOは、 メソスコピックレベルで凝縮物質をシミュレートするための科学パッケージです(化学者と物理学者は、正しく翻訳しなかった場合は許してくれます)。 このパッケージはダーズベリーの研究所で開発され、研究コミュニティと業界(Unilever、Syngenta、Infineum)の両方で広く使用されています。 このソフトウェアを使用して、シャンプー、肥料、燃料添加物の最適な処方が検索されます。 このプロセスは「コンピューター支援製剤」(CAF)と呼ばれます-私はそれを「化学式の開発におけるCAD」として翻訳しました。
CAFシミュレーションは非常にリソースを消費する計算なので、開発者はすぐに最も生産的な設計に興味を持ちました。 また、DL_MESOは、IntelとHartreeの間のIntel Parallel Computing Center(IPCC)の共同プロジェクトの1つとして選ばれました。
DL_MESO開発者は、AVX-512などの今後のテクノロジーにより、倍精度の数値でコードを8倍高速化できる可能性があるため(ベクトル化されていないコードと比較して)、ベクトル並列処理のハードウェア機能を利用したいと考えました。
この投稿では、Darsburyの科学者がベクトル化アドバイザーを使用してDL_MESOのラティスボルツマン方程式コードを分析した方法、見つかった具体的な問題、およびコードを修正して2.5倍オーバークロックした方法について説明します。
調査プロファイル
ベクトル化アドバイザーとは、 最初の記事をご覧ください 。 ここで、Lattice BoltzmanコンポーネントのSurveyプロファイルに直接進みます。 全体の実行時間の約半分は10の「ホット」サイクルに該当し、その中には明確なリーダーはいません。各リーダーは合計プログラム時間の12%以下しか費やしません。 この図は「フラットなプロファイル」に近いもので、通常プログラマーにとっては悪いことです。 実際、顕著な加速を達成するためには、各サイクルを個別に最適化する必要があります。
しかし、Darsbury開発者にとって幸いなことに、ベクトル化アドバイザーは次のようにループをすばやく特徴付けることができます。
- SIMDコード生成を可能にするために最小限のコード変更(通常はOpenMP4.xを使用)を必要とするベクトル化されたループですが、ベクトル化されていないループ。 最初の4サイクル(CPU時間)はこのカテゴリに分類されます。
- 単純な操作でパフォーマンスを改善できるベクトル化されたループ。
- データレイアウト構造によってパフォーマンスが制限されるベクトル化されたループ。 このようなループの最適化には、より深刻なコード処理が必要です。 後で見るように、最初の2つのカテゴリの問題を解消した後、これらは最も負荷の高い2つのサイクルになります。
- すでにうまく機能しているベクトル化されたループ。
- その他のすべてのケース(ベクトル化できないループを含む)。
ベクトル化アドバイザーは、サイクルに関する情報を提供するだけではありません。 「推奨事項」および「コンパイラー診断の詳細」タブには、特定の問題と解決策に関する情報が表示されます。
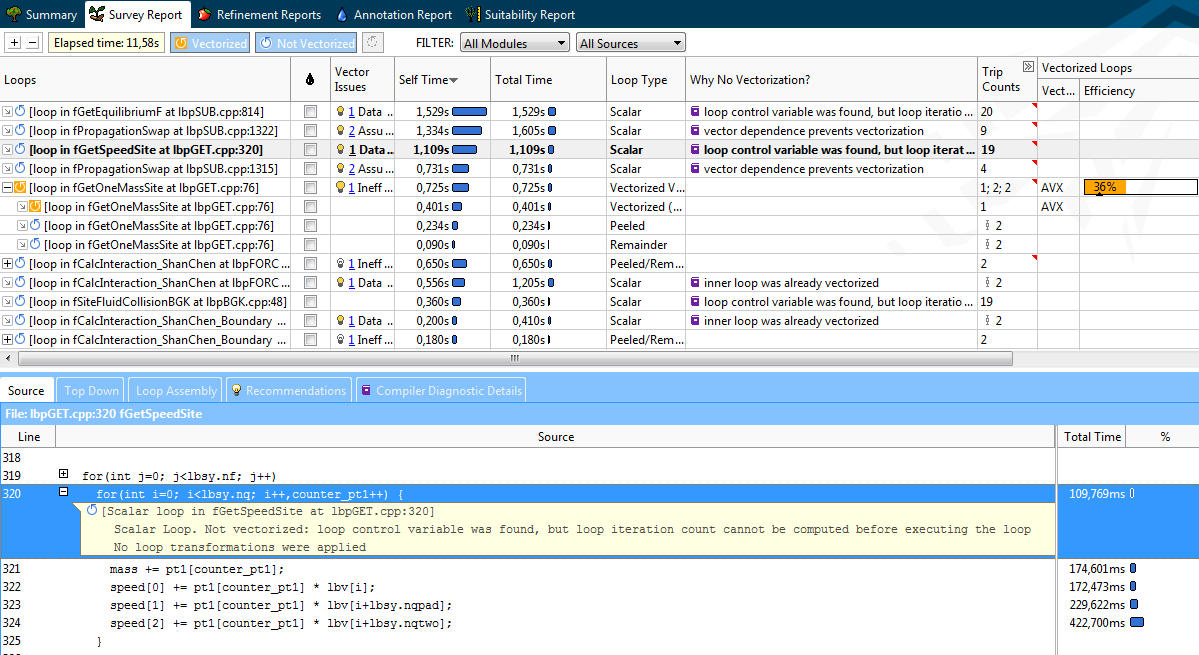
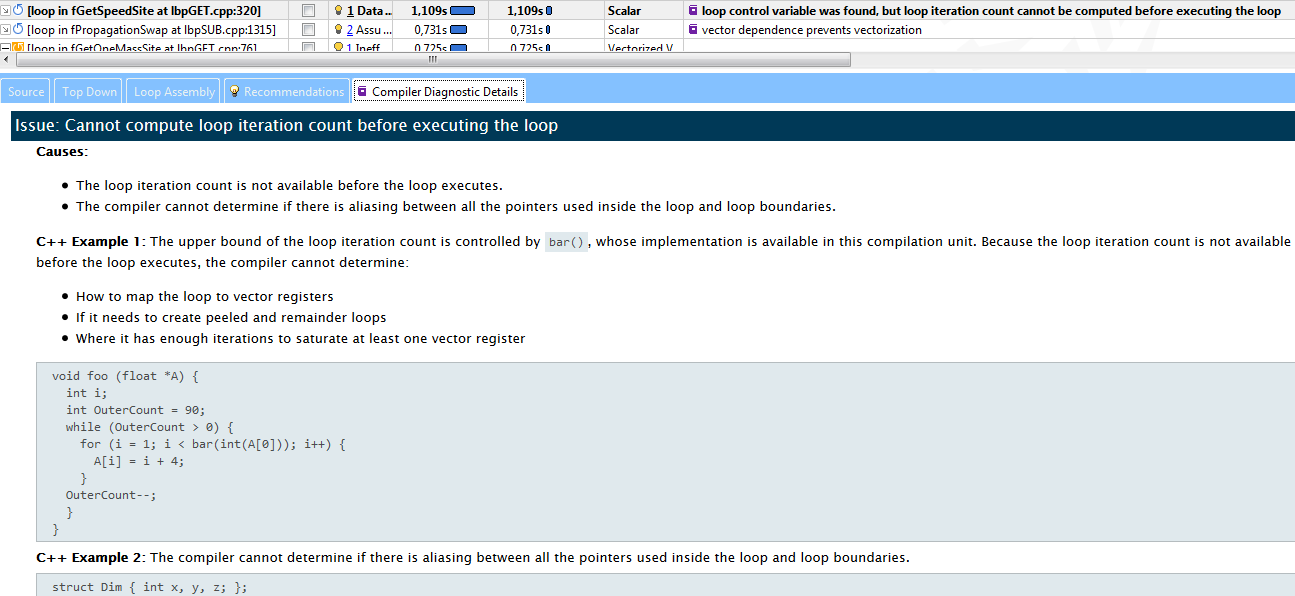
この場合、3番目のホットスポット(「ホット」サイクル、たとえば言語の純粋さの保護者は私を許してくれます)は、コンパイラーが持つ反復回数を推定できなかったため、fGetSpeedSiteでベクトル化できませんでした。 コンパイラの診断の詳細では、問題の本質を例とそれを解決するための提案とともに説明します-ディレクティブ「#pragma loop count」を追加します。 アドバイスに従って、このサイクルはすぐにベクトル化され、カテゴリ2からカテゴリ4に移行しました。
コードをベクトル化できる場合でも、必ずしもすぐに生産性が向上するわけではありません(カテゴリ2および3)。 したがって、すでにベクトル化されたサイクルの有効性を調査することが重要です。
単純な最適化:「平衡分布」コアのパディング
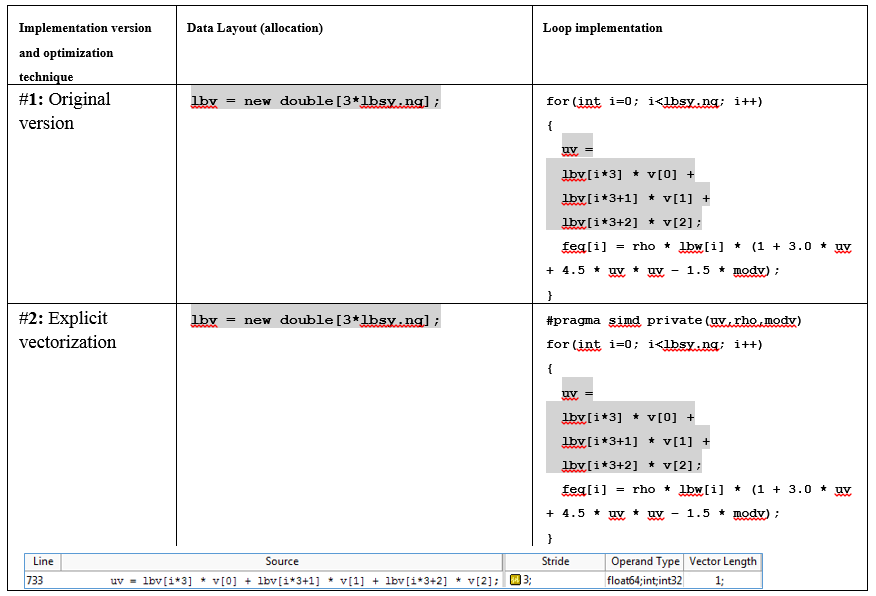
int fGetEquilibriumF(double *feq, double *v, double rho) { double modv = v[0]*v[0] + v[1]*v[1] + v[2]*v[2]; double uv; for(int i=0; i<lbsy.nq; i++) { uv = lbv[i*3] * v[0] + lbv[i*3+1] * v[1] + lbv[i*3+2] * v[2]; feq[i] = rho * lbw[i] * (1 + 3.0 * uv + 4.5 * uv * uv - 1.5 * modv); } return 0; }
lbv配列は、すべての次元にわたる空間格子の速度を格納します。 lbsy.nq変数には速度の数が含まれています。 このモデルは、3次元の19スピードグリル(D3Q19スキーム)を表しています。 つまり lbsy.nqの値は19です。結果の平衡はfeq [i]配列に保存されます。
最初の分析では、サイクルはベクトル化ではなくスカラーでした。 ループの前に「#pragma omp simd」を追加するだけで、ベクトル化され、合計CPU時間に占める割合が13%から9%に低下しました。 しかし、これらの変更があっても、まだ改善の余地があります。
Advisor XEの新しい結果は、コンパイラが1つではなく2つのサイクルを生成することを示しました。
- 256ビットAVXレジスタの4〜4個のdouble型のベクトル長(ベクトル長-VL)を持つサイクルのベクトル化されたボディ。
- スカラーの残りは、このサイクルの時間の30%を消費します。
このスカラーの残りは不必要なオーバーヘッドです。 その存在は、並列効果に有害です。 このような大きな「重み」の余りは、反復回数がVL(ベクトル長)で正確に除算されないという事実によって引き起こされます。 コンパイラは、反復0〜15のベクトル命令を生成し、残りの反復16〜18はスカラー剰余で実行されます。 3回の反復で、ゆっくりと順次実行される場合でも、サイクル時間の30%を占めます。 理想的には、すべての反復はベクトルコードで実行され、残りはまったく実行されません。
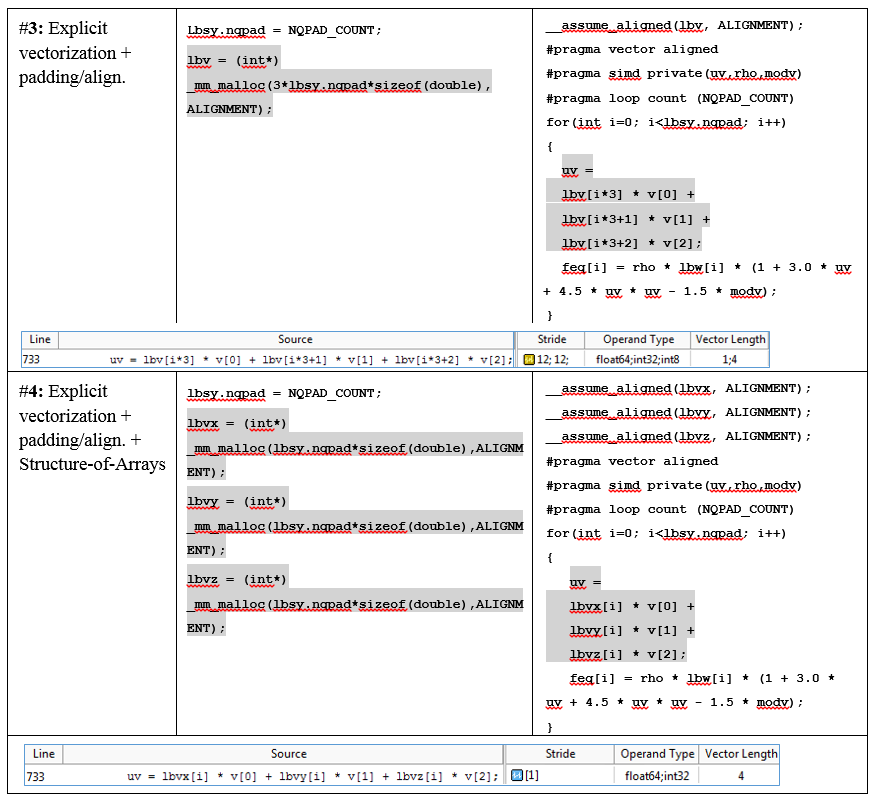
ループにデータパディング手法を適用できます。 反復回数を20に増やします。これはVLの倍数になります(4)。 Advisor XEは、[推奨事項]タブでこれを明示的にアドバイスします。
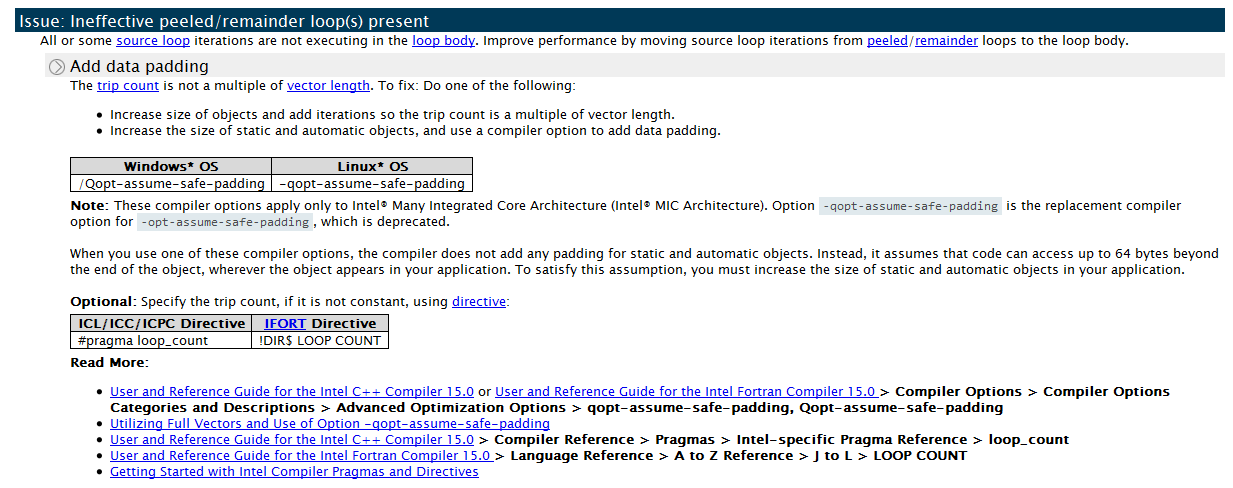
データを「ノックアウト」するには、セグメンテーション違反が発生しないように、配列feq []、lbv []、およびlbw []のサイズを大きくする必要があります。 記事の最後にある表は、コードの変更を示しています。 lbsy.nqpad値は、元の反復回数とパディング値(NQPAD_COUNT)の合計です。
さらに、DL_MESO開発者は、ループの前に「#pragma loop count」ディレクティブを追加しました。 反復回数がVLの倍数であることを明示的に確認すると、コンパイラーはベクトルコードを生成し、残りは実行されません。
DL_MESOコードには、同じ方法で改善できる多くの同じ構造があります。 同じソースファイル内の他の3つのサイクルを修正し、それぞれのサイクルを15%加速しました。
オーバーヘッドのバランスと最適化のトレードオフ
最初の2サイクルに使用されるパディング手法には、代償が伴います。
- パフォーマンスの観点から、スカラー剰余のオーバーヘッドを除去しますが、ベクトル部分に追加の計算を導入します。
- コードサポートの観点から、入力データのサイズとロードのタイプに応じて、データ構造の割り当てを再定義し、コンパイラディレクティブに潜在的に導入された値を変更しました。
私たちの場合、パフォーマンスに対するプラスの効果が短所を上回り、コードの複雑さは許容範囲でした。
データレイアウトの最適化:配列構造
ベクトル化、データパディング、およびデータアライメントにより、ホットスポットNo. 1のパフォーマンスが25〜30%向上し、Advisor XEによるベクトル化の効率は56%に向上しました。
なぜなら 56%はまだ100%とはほど遠いため、開発者は生産性の向上を妨げる要因を調査することにしました。 「ベクターの問題/推奨事項」をもう一度見て、彼らは新しい問題を発見しました-「可能性のある非効率的なメモリアクセスパターンが存在する」。 対応する推奨事項は、「メモリアクセスパターン」(MAP)分析を実行することです。 同じアドバイスが特性列にもありました:

MAP分析を開始するには、開発者は必要なサイクルにマークを付け、[ワークフロー]パネルの[MAP開始]ボタンをクリックします。

MAPの結果としてのストライドの分布は、ユニットストライド(シーケンシャルアクセス)と非ユニット「一定」ストライド-一定のステップでのメモリアクセスの存在を示しています。

ソースコードのMAPデータは、lbv配列にアクセスするときに、ストライド3(元のスカラーバージョンの場合)およびストライド12(パディングのあるベクトル化バージョンの場合)のヒットの存在を示します(最後の表を参照)。
ステップ3の魅力は、速度lbvの配列の要素に発生します。 新しい反復ごとに、配列の3つの要素がシフトされます。 3がどこから来るかは、lbv [i * 3 + X]という式から明らかです。これは、メモリアクセスの原因です。
このような一貫性のないアクセスは、タイプmovの1つの命令のベクトルレジスタにすべての要素をロードできないため、ベクトル化にはあまり適していません(「パック」バージョンは別の方法で呼び出されます)。 しかし、「構造の配列」から「配列の構造」への変換を適用することにより、一定のステップでの処理をシーケンシャルアクセスに変換できることがよくあります。 MAP分析後、推奨ウィンドウはこれを正確に通知し(AoS-> SoA)、非効率的なメモリアクセスの問題を解決することに注意してください-上記のスクリーンショットを参照してください。
開発者は、この変換をlbv配列に適用しました。 これを行うために、もともとX、Y、Zの速度を含んでいたlbv配列は、lbvx、lbvy、lbvzの3つの配列に分割されました。
DL_MESO開発者は、配列の構造の変換はパディングと比較して手間がかかると言いましたが、結果は努力する価値がありました-fGetEquilibriumのサイクルは2倍速くなり、lbvアレイで動作するいくつかのサイクルで同様の改善が起こりました。
データ構造の変換とループの最適化の結果(パディング、アライメント)、およびパフォーマンスメトリックとAdvisor XEメモリアクセスパターン:
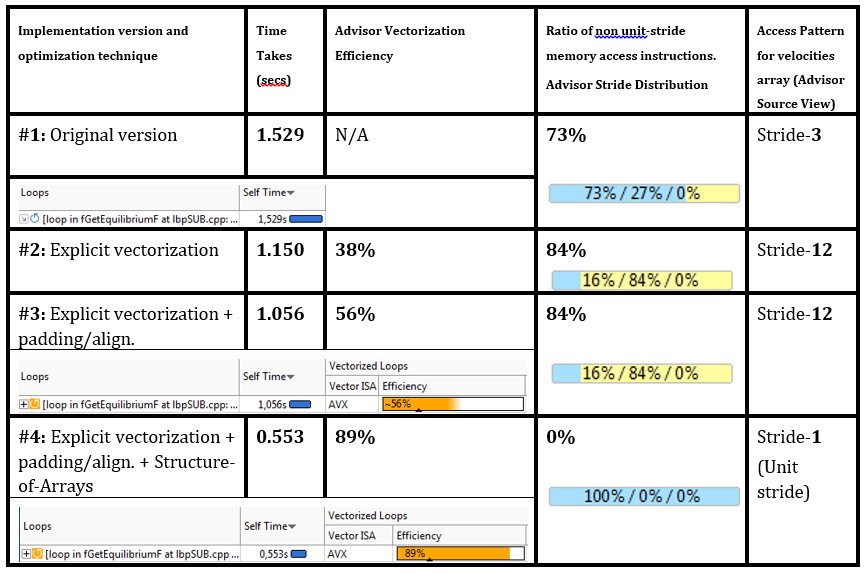
問題のサイクルのソースコードの進化-ベクトル化ディレクティブ、アライメント、パディング、AoS-> SoA変換、およびAdvisor XEからのMAP結果:
まとめ
Vectorization AdvisorのDL_MESO分析を使用して、コードにいくつかのディレクティブを追加すると、3つの最もホットなサイクルの時間を10〜19%短縮できました。 すべての最適化は、アドバイザの推奨事項に基づいています。 ベクトル化を「有効化」し、「パディング」を使用してループパフォーマンスを改善する作業が行われました。 同様の手法をさらに数サイクルに適用すると、アプリケーション全体が18%加速されました。
データを「構造の配列」から「配列構造」に変換することにより、次の大きな改善が得られました。 繰り返しますが、Advisor XEの推奨に基づいています。
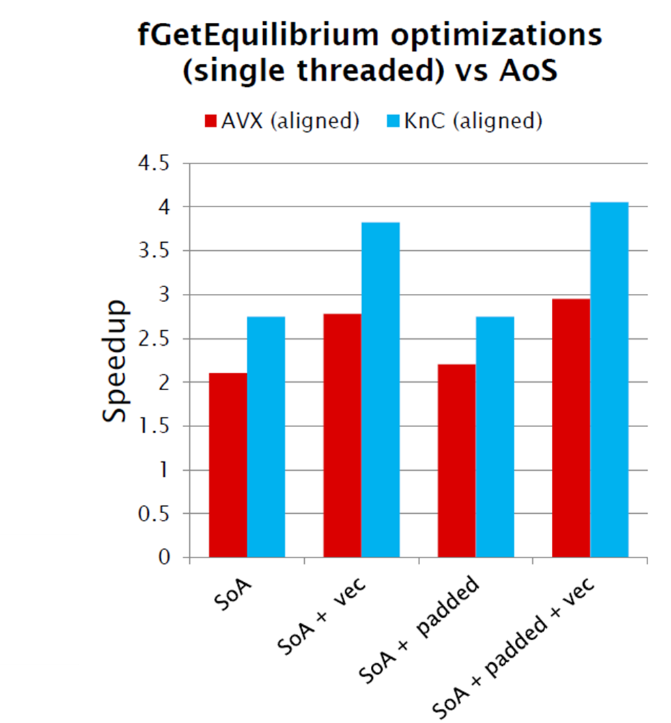
さらに、Xeonプロセッサを搭載したサーバーで作業とテストが最初に実行されました(Advisorはコプロセッサではまだ動作しません)。 Xeon Phiコプロセッサーで実行されているコードに対して同じことが行われたとき、私たちはほぼ同じ利益を得ました-追加の労力なしでコプロセッサーを最適化しました。
以下は、通常のサーバー(AVXのラベル)とXeon Phiカード(KnCのラベル)で得られたアクセラレーションを示しています。 Xeon CPUでは2.5倍、Xeon Phiでは4.1倍加速しました。
DL_MESO開発者を引用すると、「私はすでにこのツールで販売されています。現在必要なのはXeon Phiのバージョンです!」(Dukeslab研究所の計算科学者Luke Mason)。
この投稿は、Zakhar Matveev(Intel Corporation)による記事の翻訳です。