以下は、各オプションの利点です。
自動インクリメント
- 省スペース
- 理論的には、新しい価値のより速い生成
- 高速なデシリアライゼーション
- 数字は覚えやすいため、デバッグ、サポートの際に操作が簡単です
GUID
- 複数のレプリカに新しいエントリが追加される複数のデータベースインスタンス間で複製する場合、GUIDは衝突を保証しません
- データベースに保存する前に、クライアントでレコード識別子を生成できます。
- 最初の段落の要約-同じテーブル内だけでなく、いくつかの決定にとって重要な場合がある一意の識別子を提供します
- レコードをパブリックAPIに渡すことでレコードを取得できる場合、キーを「推測」することはほぼ不可能です。
「理論的には、新しい意味のより速い生成」というフレーズは納得できないように聞こえます。 このような考慮事項は、実用的な例によって常に最もよくサポートされます。 ただし、テスト用のプログラムを作成する前に、これら2つのタイプのそれぞれで主キーを実装するためのオプションを検討します。
GUIDは、クライアントとデータベース自体の両方で生成できます-すでに2つのオプションがあります。 さらに、MS SQLには、一意の識別子を取得するための2つの関数、NEWIDとNEWSEQUENTIALIDがあります。 それらの違いは何か、実際にそれが重要になるかどうかを見てみましょう。
Guid.NewGuid()を介した同じ.NETでの一意の識別子の通常の生成は、規則性によって相互に関連しない多くの値を提供します。 この関数から取得した多くのGUIDが並べ替えられたリストに保持されている場合、追加される新しい値はそれぞれ、その任意の部分に「入る」ことができます。 MS SQLのNEWID()関数も同様に機能します-その値の多くは非常に混oticとしています。 同様に、NEWSEQUENTIALID()は同じ一意の識別子を提供します。この関数の新しい値のみが前のものよりも大きくなりますが、識別子は「グローバルに一意」のままです。
Entity Framework Code Firstを使用し、このような主キーを宣言する場合
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)] public Guid Id { get; set; }
デフォルト値NEWSEQUENTIALID()を持つプライマリクラスターキーを使用して、データベースにテーブルが作成されます。 これはパフォーマンス上の理由で行われます。 繰り返しますが、理論上、リストの中央に新しい値を挿入することは、最後に追加するよりもコストがかかります。 もちろん、データベースはメモリ内の配列ではないため、行のリストの中央に新しいレコードを挿入しても、後続のすべてのレコードが物理的にシフトされることはありません。 ただし、余分なオーバーヘッドは-ページ分割になります。 その結果、インデックスの強力な断片化も発生し、データサンプリングのパフォーマンスに影響する可能性があります。 データがクラスター化されたテーブルに挿入される方法の適切な説明は、このリンクのフォーラムの回答にあります。
したがって、GUIDには、パフォーマンスの観点から分析する必要がある4つのオプションがあります。クライアントでの生成とシーケンシャルで一貫性のないGUID、および同じペアですが、ベース側での生成です。 質問は残っていますが、クライアントで連続したGUIDを取得する方法は? 残念ながら、これらの目的のための.NETには標準関数はありませんが、P / Invokeを使用して実行できます。
internal static class SequentialGuidUtils { public static Guid CreateGuid() { Guid guid; int result = NativeMethods.UuidCreateSequential(out guid); if (result == 0) { var bytes = guid.ToByteArray(); var indexes = new int[] { 3, 2, 1, 0, 5, 4, 7, 6, 8, 9, 10, 11, 12, 13, 14, 15 }; return new Guid(indexes.Select(i => bytes[i]).ToArray()); } else throw new Exception("Error generating sequential GUID"); } } internal static class NativeMethods { [DllImport("rpcrt4.dll", SetLastError = true)] public static extern int UuidCreateSequential(out Guid guid); }
特別なバイト順列がなければ、GUIDを返すことができないことに注意してください。 識別子は正しくなりますが、SQLサーバーの観点からは一貫性がないため、理論的には「通常の」GUIDと比較してゲインを達成できません。 残念ながら、多くのソースで誤ったコードが提供されています。
リストに5番目のオプションである自動インクリメントの主キーを追加することは残っています。 クライアントで正常に生成できないため、他のオプションはありません。
オプションを決定しましたが、テストを記述する際に考慮すべきパラメーターがもう1つあります。それは、テーブル行の物理サイズです。 MS SQLのデータページサイズは8キロバイトです。 近いサイズまたはさらに大きいサイズのレコードは、桁違いに小さいレコードよりも重要なオプションごとにパフォーマンスの変動が大きくなる場合があります。 レコードのサイズを変更する機能を提供するには、各NVARCHARテストテーブルにフィールドを追加するだけで十分です。このフィールドには、必要な文字数が入力されます(NVARCHARフィールドの1文字は2バイトかかります)。
テスト中
このリンクには、上記の考慮事項を考慮して開発されたプログラムを含むプロジェクトが含まれています。
以下は、このスキームに従って実行されたテストの結果です。
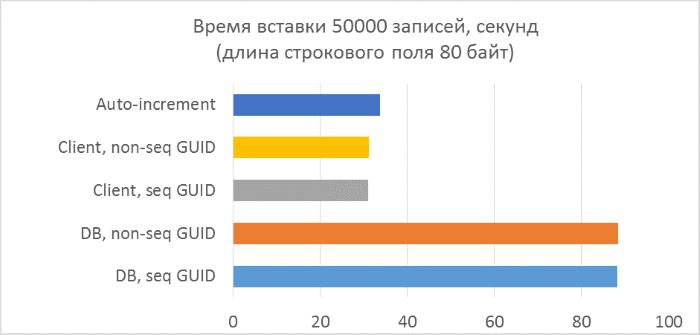
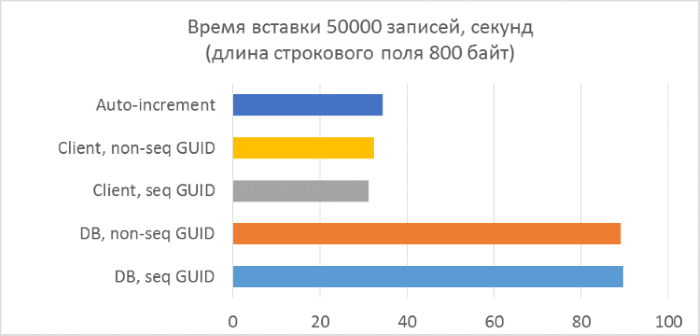
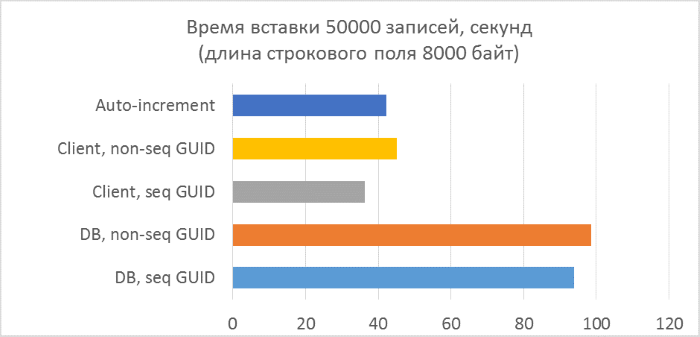
- テキストフィールドの長さがそれぞれ80、800、および8000バイトのテストは3シリーズのみです(NVARCHARの1文字は2バイトを使用するため、テストプログラムの文字数はそれぞれ半分になります)。
- 各シリーズには5つの開始があり、それぞれが10,000個のエントリを各テーブルに追加します。 各起動の結果によれば、すでにテーブルにある行の数に対する挿入時間の依存関係を追跡することが可能になります。
- 各シリーズが開始される前に、テーブルは完全にクリアされます。
そして、実行ごとに分類された結果:
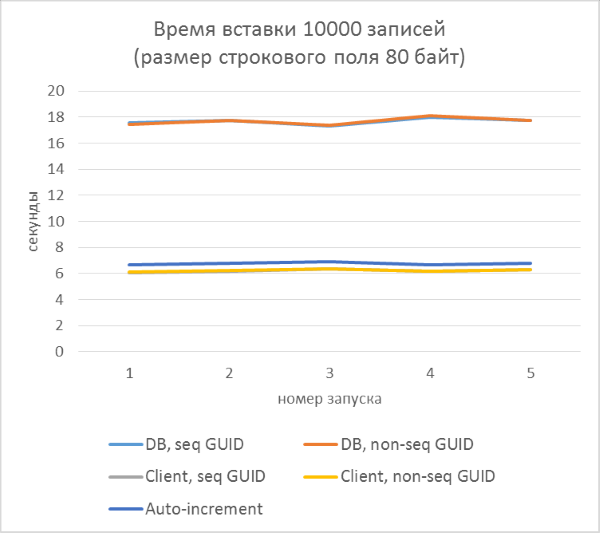
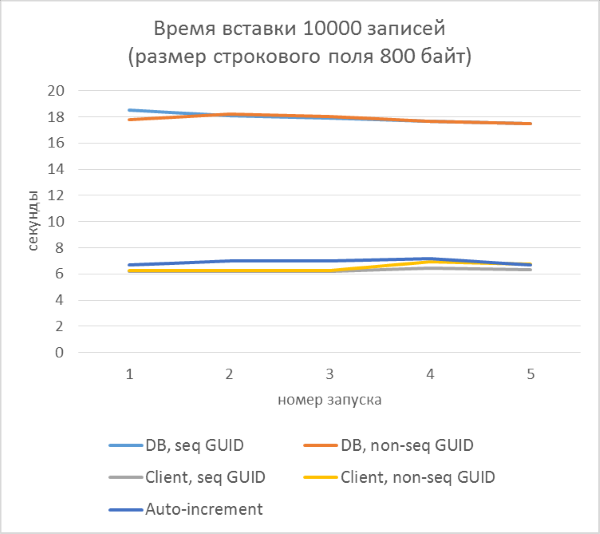
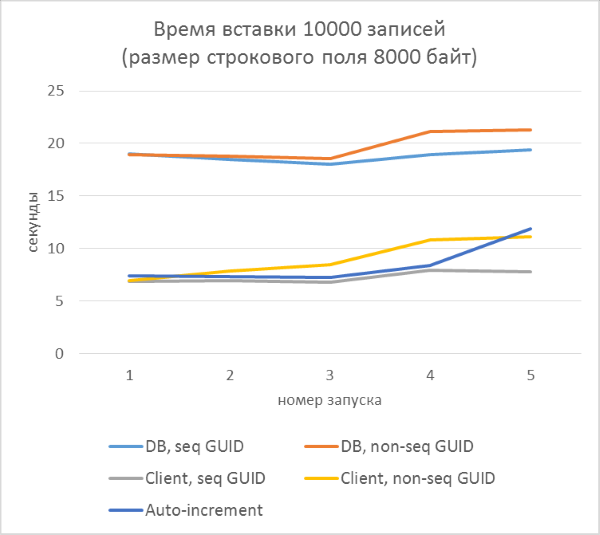
結果はすぐに以下を示します。
- データベース側のGUID生成の使用は、クライアント側の生成よりも大幅に遅くなります。 これは、新しく追加された識別子を読み取るコストのためです。 この問題の詳細については、記事の最後で説明します。
- 自動インクリメントキーを使用したレコードの挿入は、クライアントに割り当てられたGUIDを使用した場合よりも少し遅くなります。
- 連続したGUIDと一貫性のないGUIDの違いは、小さなレコードではほとんど見えません。 大規模なレコードでは、テーブル内の行数の増加に伴って違いが現れますが、大きくは見えません。
最後の点は検討する価値があります。 頻繁なページ分割を除き、一貫性のないGUIDを使用すると、速度低下の原因となるものは何ですか? 最も可能性が高いのは、ディスクから「ランダム」ページを頻繁に読み取るためです。 シリアルGUIDを使用する場合、追加はインデックスの最後までしか行われないため、目的のページは常にメモリ内にあります。 一貫性がないと、インデックスの任意の場所に多くの挿入が行われ、すべての場合に必要なページがメモリにあるわけではありません。 このようなランダムな読み取りがテスト結果にどの程度影響するかを確認するために、SQL Serverのメモリ容量を人為的に制限して、メモリにテーブルが完全に収まらないようにします。
大まかな計算では、50,000文字のレコード数を持つ4000文字(8000バイト)の文字列長のテストでは、テーブルのサイズは少なくとも400 MBになることが示されています。 許可されるSQL Serverメモリを256MBに制限し、このテストを繰り返します。
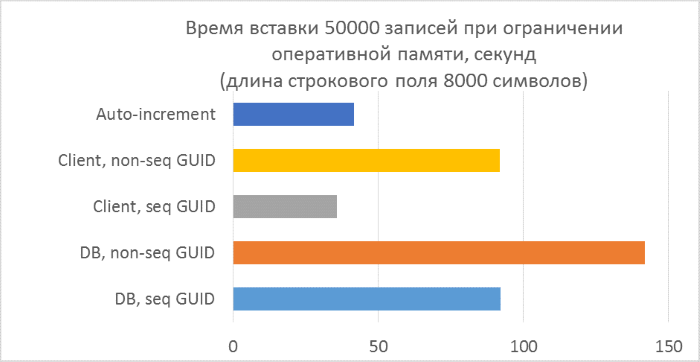
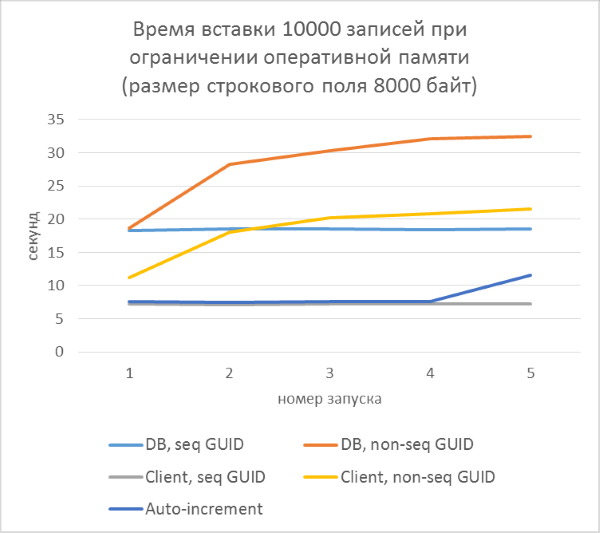
予想どおり、キーに一貫性のないGUIDが含まれるテーブルへの挿入は著しく遅くなり、テーブル内の行数が増えると遅くなります。 同時に、シーケンシャルGUIDおよび自動インクリメントの挿入パフォーマンスは安定しています。
結論
- 記事の冒頭で示されたいずれかの基準で、GUIDを主キーとして使用する必要がある場合、最適なパフォーマンスオプションは、クライアント上の各レコードに対して生成される順次GUIDです。
- 何らかの理由でクライアントでGUIDを作成することが受け入れられない場合は、NEWSEQUENTIALID()を介してベース側で識別子の生成を使用できます。 Entity Frameworkは、ベース側で生成されたGUIDキーに対してデフォルトでこれを行います。 ただし、クライアント側で識別子を作成する場合と比較して、挿入パフォーマンスが著しく低下することに注意してください。 テーブルへの挿入数が少ないプロジェクトの場合、この違いは重要ではありません。 それでも、ほとんどの場合、このオーバーヘッドは、挿入されたレコードの識別子をすぐに取得する必要がないシナリオで回避できますが、そのようなソリューションは普遍的ではありません。
- プロジェクトですでに一貫性のないGUIDが使用されている場合、テーブルへの挿入数が多く、データベースのサイズが使用可能なRAMのサイズよりもはるかに大きい場合は、修正を検討する必要があります。
- 他のDBMSの場合、パフォーマンスの違いは完全に異なる場合があるため、結果はMicrosoft SQL Serverに関してのみ考慮することができます。 記事の冒頭で指定した基本的な基準は、特定のDBMSに関係なく当てはまります。
UPD:ベース側でGUIDキーを生成するオプションが遅い理由
Entity Frameworkが自動インクリメントキーを使用してテーブルに挿入すると、SQLコマンドは次のようになります。
INSERT [dbo].[AutoIncrementIntKeyEntities]([Name], [Count]) VALUES (@0, @1) SELECT [Id] FROM [dbo].[AutoIncrementIntKeyEntities] WHERE @@ROWCOUNT > 0 AND [Id] = scope_identity()
サーバー側のGUIDの場合、より複雑なバージョンを取得します。
DECLARE @generated_keys table([Id] uniqueidentifier) INSERT [dbo].[GuidKeyDbNonSequentialEntities]([Name], [Count]) OUTPUT inserted.[Id] INTO @generated_keys VALUES (@name, @count) SELECT t.[Id] FROM @generated_keys AS g JOIN [dbo].[GuidKeyDbNonSequentialEntities] AS t ON g.[Id] = t.[Id] WHERE @@ROWCOUNT > 0
したがって、クライアントが新しく追加された行のキーを取得できるように、挿入中にキー値が入力されるテーブル変数が作成され、受信した値をクライアントに返すためにこのテーブル変数から選択が行われます。
簡単なテストでは、このような一連のコマンドは、同じテーブルでのINSERTよりも平均でほぼ3倍遅いことがわかります。 自動インクリメントの場合、追加のテーブル変数は使用されないため、オーバーヘッドは小さくなります。