
本日、新しいIntelデータ分析ライブラリであるIntel Data Analytics Acceleration Libraryの最初の公式リリースがリリースされました 。 このライブラリは、Parallel Studio XEパッケージの一部として、および商用および無料の(コミュニティ)ライセンスを持つ独立した製品として利用できます。 それはどのような動物で、なぜ必要なのですか? 正しくしましょう。
Intel DAALはどこで必要ですか?
今日、データの処理、分析、表示の問題を研究するデータの科学全体(データサイエンス)があります。 統計的手法、データマイニング、機械学習、パターン認識の理論、人工知能(AI)アプリケーションなど、さまざまな分野が含まれます。

さらに、これらすべての研究分野には多くの共通部分がありますが、違いがあります。 そのため、統計はデータマイニングよりも理論に基づいており、仮説のテストに焦点を当てています。 機械学習はよりヒューリスティックであり、学習エージェントのパフォーマンスの向上に焦点を当てています。 また、データマイニングは理論とヒューリスティックの統合を表し、データクリーニング、トレーニング、統合、結果の視覚化など、データ分析の単一プロセスに焦点を当てています。 Intel DAALは、データサイエンスとその分野に関係するすべての人にとって興味深いものです。
データマイニングには標準がありますが、最も一般的なのは、データマイニングの業界共通プロセスCRISP-DM(データマイニングの業界標準プロセス)です。 この標準によれば、データ分析プロセスは反復的であり、ビジネスの理解、データの理解、データの準備、モデリング、評価、実装(展開)。
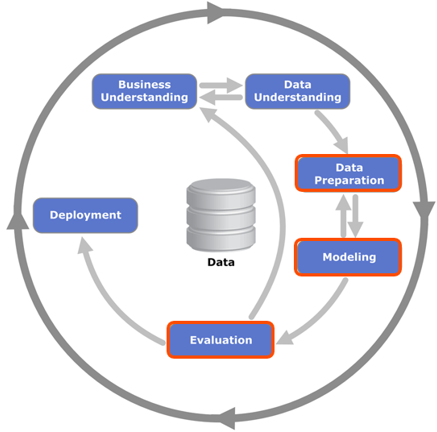
DAALライブラリは、この標準のフレームワーク内でのデータマイニング手法の提示について話す場合、主にデータの準備、モデリング、および結果の評価を目的としています。 同時に、Intel Math Kernel LibraryとIntel Integrated Performance Primitivesのアルゴリズムを使用して最適化されます。
問題と解決策
なぜDAALであり、なぜこのライブラリが開発者にアピールするのか
データ分析の分野では、現在、膨大な数の異なるテクノロジーとツールがあります。 この業界の成長率を考えると、これは非常に自然なことです。
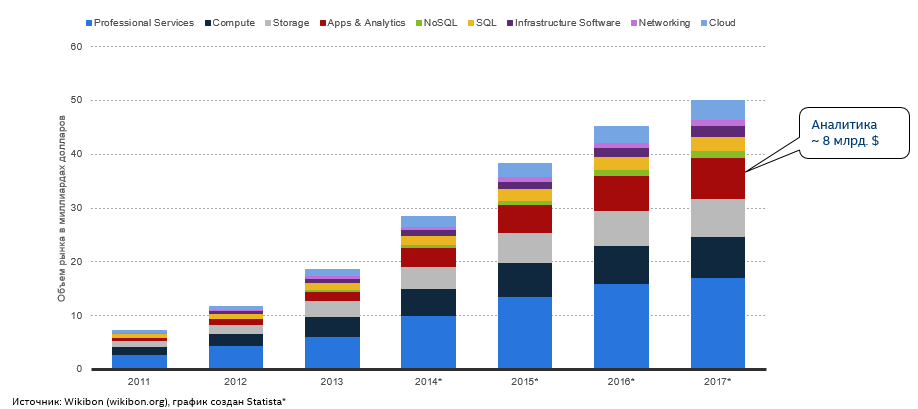
ウィキボンの興味深い統計:2017年までに、ビッグデータ市場のボリュームは約500億の米国大統領になり、そのうち8人はソフトウェアと分析です。
多数の異なるソースから受信したデータの保存は、SQLを使用したデータへのアクセスを備えた従来のリレーショナルDBMSと、非伝統的なNoSQL(SQLだけでなく)の両方によって実装されます。 さらに、データはすぐにメモリに保存できます。 このデータを処理するために、Hadoop、Spark、Cassandraなどの大きなフレームワークが使用されるようになりました。
現在のソリューションには、パフォーマンスに関する大きな問題が1つあります。 たとえば、オープンソースのSparkフレームワーク、またはむしろSpark MLLib機械学習ライブラリを検討してください。
Spark MLLibはScala言語を使用して記述されており、Java用のNetlibラッパーであるNetlib-Javaに依存する別のオープンソースBreeze線形代数パッケージを使用します。 その結果、Netlib BLASが使用されますが、その実装は通常一貫しており、最適化されていません。 明らかに、依存関係が多すぎる、「マルチレイヤー」、パフォーマンスが低いという問題があります。
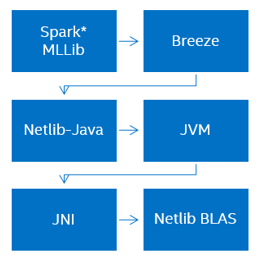
Intelのアイデアは、ハードウェア用に最適化しながら、類似の多層実装を除く、データ分析のすべての段階で機能する1つのライブラリを作成することです。

このソリューションを使用すると、パフォーマンスが大幅に向上します。 主成分分析(PCA)メソッドの例を使用して、Intel DAALの実装と同じSpark MLlibを比較すると、結果の加速は、データテーブルのサイズに応じて4〜7倍になります。

主なコンポーネント
Intel DAALは、C ++とJava、およびWindows、Linux、OS Xをサポートしています。Hadoop、Spark、R、Matlabなどのプラットフォームで使用できますが、これらのいずれにも関連付けられていません。 さらに、ファイルおよびメモリ内のCSV、MySQL、HDFS、Apache Spark *のResilient Distributed Dataset(RDD)オブジェクトなど、ローカルおよび分散データソースのサポートがあります。
このライブラリは、データ管理、アルゴリズム、サービスの3つの主要コンポーネントで構成されています。
データ管理
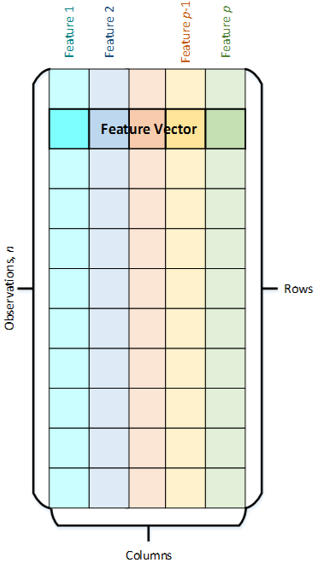
これには、データを取得するためのクラスとユーティリティ、一次処理と正規化、および数値形式への変換が含まれます。 DAALアルゴリズムは、データテーブルという特別な形式のデータを処理します。 したがって、ライブラリを使用する際の最初のステップは、データをこれらのテーブルに変換することです。
彼らはどんな人ですか? 各オブジェクトは、一連の属性(機能)-オブジェクトを特徴付けるプロパティによって特徴付けられます。 たとえば、目の色、年齢、水温など。 属性のセットは、サイズpの特徴ベクトルを形成します。 これらのベクトルは、サイズnの一連の観測(観測)を順番に形成します。 DAALでは、データはテーブルの形式で保存され、行は観測であり、列はプロパティです。
アルゴリズム
アルゴリズムは、データ分析とモデリングを実装するクラスで構成されます。 これらには、分解、クラスタリング、分類、回帰アルゴリズム、および連想ルールが含まれます。
アルゴリズムは、次のモードで実行できます。
- バッチ処理
アルゴリズムは、データセット全体を一度に処理し、結果を生成します。 すべてのライブラリアルゴリズムがこのモードをサポートしています。
- オンライン処理
より複雑なケースとして、すべてのデータが全体としてすぐに利用できない場合や、たとえばメモリに保存されない場合があります。 この場合、メモリで徐々にロードされるブロックでデータを処理するモードを使用できます。 すべてのライブラリアルゴリズムにオンライン実装があるわけではありません。
- 分散処理
データは複数のコンピューティングノードに分散されます。 中間結果は各ノードで計算され、最終的にメインノードで結合されます。 オンライン処理と同様に、すべてのライブラリアルゴリズムが分散実装されているわけではありませんが、Intelのエンジニアはそれに取り組んでいます。
サービス
サービスには、アルゴリズムとデータ管理で使用されるクラスとツールが含まれます。 これには、メモリの割り当て、エラーの処理、コレクションの実装、および一般的なポインターのためのさまざまなクラスが含まれます。
合計
Intel DAALライブラリにはさまざまな機能があり、1回の投稿でそれらについて話すことはできません。 なぜそれが必要なのか、どのような目的で市場に登場するのかを示し、その主要コンポーネントを調べました。 この問題に興味のある人の質問やコメントを聞き、この興味深い図書館についての会話を続けたいと思います。 DAALアルゴリズムについて話し、それを使用したコード例を示す予定です。
現在、Intel DAALは、Intelアーキテクチャ向けに最適化されたデータ分析のための唯一のライブラリです。