
こんにちは、Habr。
javascriptの世界は信じられないほどの速度で開発されています:新しい言語標準、新しいフレームワーク、ブラウザ、サーバー、デスクトップアプリケーションなどの両方... そして、まさにそのソースに深く潜ります。
そしてその瞬間、私の目線の下で、ChromeコンソールまたはNode.jsのJS開発者の目の前に何らかの形で現れる「ネイティブコード」という目に見えない行がありました。
[].sort.toString(); "function sort() { [native code] }"
興味深いことに、V8では碑文[ネイティブコード]の背後にどのような並べ替えの実装が隠されています-catの下にようこそ。
勉強するには、githubのv8-git-mirrorリポジトリを使用します。 以下、バージョン4.6.9のコードを参照します。これは、執筆時点で関連していました。
V8リポジトリはすばらしいので、単純な検索コマンドで検索を開始することにしました。
find ./src -iname "*array*" ./src/array-iterator.js ./src/array.js ./src/arraybuffer.js ./src/harmony-array-includes.js ./src/harmony-array.js ...
これらのファイルの名前はおなじみのようです。 まさにarray.jsが必要なようです 。 その内容は何ですか?
一般に、これは通常のjsコードです。ただし、UPPERCASEで記述され、 macros.pyファイルで定義されるさまざまなマクロと定義、および%で始まるC ++コードの腸のどこかで既に定義されている関数の呼び出しは例外です$。 しかし、怖がらないでください。jsではないものにはすべて、名前に基づいた明確な目的があります。たとえば、%_CallFunctionは明らかに関数を呼び出します。 ソートコードの検索を続けましょう。
並べ替え方法がArray.prototypeに追加された最後から始めましょう。
// Set up non-enumerable functions of the Array.prototype object and // set their names. // ... utils.InstallFunctions(GlobalArray.prototype, DONT_ENUM, [ // ... "sort", getFunction("sort", ArraySort), "filter", getFunction("filter", ArrayFilter, 1), "forEach", getFunction("forEach", ArrayForEach, 1), // ... ]);
ええ、ArraySort関数が必要です。 同じファイルで定義されています:
function ArraySort(comparefn) { CHECK_OBJECT_COERCIBLE(this, "Array.prototype.sort"); var array = $toObject(this); var length = TO_UINT32(array.length); return %_CallFunction(array, length, comparefn, InnerArraySort); }
これは、( 仕様に従って)オブジェクトに変換できるかどうかをチェックし、変換できない場合は、TypeError例外がスローされます。 次に、これがオブジェクトに変換され、長さがuint32に変換され、 InnerArraySortが呼び出されます。 これらの281行では、V8でソートが実装されています。
多くの人が疑うように、このクイックソートは、平均的な複雑さがO(nlog n)である最も一般的な不安定な内部ソートアルゴリズムの1つです。 クイックソートはV8ではすぐに表示されませんでしたが、パフォーマンスを改善するために、2008年9月25日にピラミッドソート( heapsort )を置き換えました。
どこでも、ソートの選択はクイックソートに焦点を合わせています。 たとえば、SpiderMonkey(Firefox jsエンジン)では、 マージソートが使用されます- ソースコード
実装のニュアンスをさらに調べるには、クイックソートアルゴリズムのステップが何であるか(簡略化)を思い出してください。
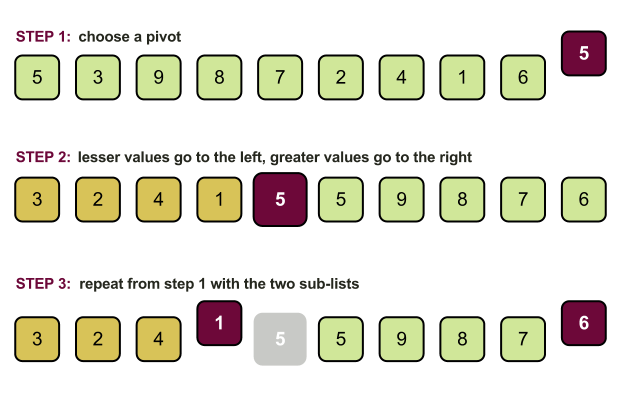
- 配列からサポート要素(ピボット)を選択します。
- 配列を再編成し、次の形式にします。ピボットより小さい要素、ピボット、ピボットより大きい要素。
- 配列の左右の部分について再帰的に繰り返します。
時間が経つにつれて、V8内でのソートの実装は、多くの異なる最適化を獲得しました。 まず、最適化は、サポート要素の選択方法、末尾再帰、および小さな配列を処理するためのアルゴリズムに関連付けられています。 それらを出現順に見てみましょう。
最初の改良点は、小さな配列に対する挿入ソートの追加でした。 ソースコードは次のとおりです 。
var InsertionSort = function InsertionSort(a, from, to) { for (var i = from + 1; i < to; i++) { var element = a[i]; for (var j = i - 1; j >= from; j--) { var tmp = a[j]; var order = %_CallFunction(UNDEFINED, tmp, element, comparefn); if (order > 0) { a[j + 1] = tmp; } else { break; } } a[j + 1] = element; } };
長い間、開発者はどのアレイを「小さい」と見なすかについて合意できませんでした。 過去7年間の多くのコミットにより、障壁が減少し(すべて22の要素から始まりました)、現時点では10の要素の長さで収束しました。
ここで、サポート要素の選択方法についても説明します。サポート要素には、多くの変更が加えられています。
最初の実装では、参照要素( source )のインデックスのランダムな選択を使用しました。
var pivot_index = $floor($random() * (to - from)) + from;
次に、 3つの中央値 (最初、最後、および中央の要素)が選択されました。
しかし、最終的に、3つの中央値の単純な選択は、大きな配列( 1000を超える要素 )の中央値の平均要素を決定する非常に珍しい方法によって補完されました 。 元の配列から要素(200をわずかに超えるステップ)が選択され、新しい配列に書き込まれます。 次に、この配列がソートされ、その中央の要素が中央値を検索する中央の要素になります。 この関数はGetThirdIndexと呼ばれます :
var GetThirdIndex = function(a, from, to) { var t_array = []; // Use both 'from' and 'to' to determine the pivot candidates. var increment = 200 + ((to - from) & 15); for (var i = from + 1, j = 0; i < to - 1; i += increment, j++) { t_array[j] = [i, a[i]]; } %_CallFunction(t_array, function(a, b) { return %_CallFunction(UNDEFINED, a[1], b[1], comparefn); }, ArraySort); var third_index = t_array[t_array.length >> 1][0]; return third_index; }
そして最後に、再帰について。 2つの再帰呼び出し(配列の左と右の部分)を使用した基本アルゴリズムの問題は、サポート要素が失敗した場合、再帰の深さが配列のサイズに比例することです。 これは、実行速度を大幅に低下させるだけでなく、最悪の場合のメモリからのO(n)推定値にもなります。 V8の並べ替えの実装では、この問題も解消されました 。並べ替えは小さなサブアレイに対してのみ再帰的に呼び出され、大きなループの並べ替えはメインループで継続されます。 この最適化により、O(log n)メモリ消費の推定値が保証されます。 通常、このような末尾再帰の最適化はコンパイラによって実行できますが、JSの場合は手動で実行する必要がありました。
このようなクイックソートは、現在V8で使用されています。 しかし、jsエンジンでのソートに関するストーリーは、例で示す方が簡単な点がなければ不完全です。
有名なものから始めましょう。 関数をコンパレータに渡さないとどうなりますか:
var arr = [1, 2, 11]; arr.sort(); [1, 11, 2]
この場合、デフォルトのコンパレータが使用されます 。これは辞書式順序でソートされます。
comparefn = function (x, y) { if (x === y) return 0; if (%_IsSmi(x) && %_IsSmi(y)) { return %SmiLexicographicCompare(x, y); } x = $toString(x); y = $toString(y); if (x == y) return 0; else return x < y ? -1 : 1; };
次の謎の例:
var arr = [2, undefined, 1]; arr.sort(function () { return 0; });
答え

[2, 1, undefined]
ワット? しかし、論理があります。 これは、並べ替える前に、 SafeRemoveArrayHoles関数によって配列が再編成されるためです 。つまり、すべての重要な要素が配列の先頭で未定義に置き換わり 、すべての未定義が最後に蓄積されます。
そして最後に、おそらく最も楽しい。 Array.prototype.sortは、配列と配列のようなオブジェクトをソートするだけではありません。 プロトタイプからの値でさえ、ソートに参加できます。 欠落しているすべてのプロパティ(ゼロからlengthプロパティの値まで)は、プロトタイプからオブジェクト自体にコピーされ( CopyFromPrototype関数)、その後ソートされます。
function Arr() { this[1] = 1; } Arr.prototype[0] = 2; Arr.prototype.length = 2 var arr = new Arr(); Array.prototype.sort.call(arr, function (a, b) { return a - b; }); Arr {0: 1, 1: 2}
このソートの説明を完了することができます。 これで、碑文[ネイティブコード]の背後に実際に隠されているすべてがわかり、多くの有用な結論を引き出すことができます。
- V8は、あなたや私のように、普通の人々によって書かれ、改善されています。 同じコードが書き直され、7年間補足されました。すべての最適化がすぐに適用されたわけではなく、おそらくこの実装は何らかの形で加速または書き直されます:)
- サポート要素を見つける方法がどのように改善されても、この手順は入力データに依存します。 サポート要素の「失敗」の選択と、その後のパフォーマンスの低下の可能性があります。 一般に、入力データを詳しく調べる価値があります。たとえば、 カウントによる並べ替えなど、使用する方が収益性が高い場合があります 。
- クイックソートは不安定です( 例 : Waxer )。 しかし、安定性が必要な場合は、別の方法で行うことができます。 元のインデックスで配列の要素を補完し、これを考慮に入れるようにコンパレータをわずかに変更できます。 または、jsで安定したソートを実装するには、たとえばTimsortを使用します。 しかし、これはすでにこの記事の範囲外です。
あなたが私と同じようにこの研究を読むことに興味を持っていたことを願っています。 ソースを学ぶことで頑張ってください!