 世界中で生成される情報量の急速な増加は、隅々で話されています。 通常、これは、ネットワークインフラストラクチャ、クライアントコンテンツ、検索技術、その他多くのものに関して記憶されています。 同じ状況が企業セグメントでも見られます。ほとんどの組織では、保存される情報の量が何度も増えています。 Forrester Researchのレポートによると、企業システムのデータの約85%は静的なコンテンツであり、変更されることはありません。 当局および規制当局のさまざまな要件により、組織はさまざまな情報を数年間保存する必要があります(たとえば、すべての顧客や完了した取引などに関する情報)。 その結果、企業はこの情報の保存、サーバー群への投資、ストレージ、ソフトウェアの取得などに多額の資金を費やさなければなりません。
世界中で生成される情報量の急速な増加は、隅々で話されています。 通常、これは、ネットワークインフラストラクチャ、クライアントコンテンツ、検索技術、その他多くのものに関して記憶されています。 同じ状況が企業セグメントでも見られます。ほとんどの組織では、保存される情報の量が何度も増えています。 Forrester Researchのレポートによると、企業システムのデータの約85%は静的なコンテンツであり、変更されることはありません。 当局および規制当局のさまざまな要件により、組織はさまざまな情報を数年間保存する必要があります(たとえば、すべての顧客や完了した取引などに関する情報)。 その結果、企業はこの情報の保存、サーバー群への投資、ストレージ、ソフトウェアの取得などに多額の資金を費やさなければなりません。
格納データ量の増加の別の結果は、多くの企業が蓄積された情報の利用可能なボリューム全体を分析および検索できるようにしたいという欲求でした。 ある瞬間から、そのようなタスクはビッグデータ処理タスクに変わります。 その結果、このような情報の配列を保存および操作するのにより適したソリューションを検索する必要があります。 したがって、多くの人々は、このような情報の配列を保存し、それらを操作するためのより収益性の高いソリューションを探しています。
興味深い例はノキアで、最近モバイル部門をマイクロソフトに売却しました。 契約の条件に従って、フィンランド人はユニットの情報アーカイブ全体を新しい所有者に転送する必要がありました。 大量のデータがあるため、ノキアはこれに創造的に取り組みました。コンパクトなアーカイブストレージシステムを購入し、必要な情報をすべてデータベースにアップロードして、システム全体をマイクロソフトに送信しました。
格納される情報量の増加について言えば、古いアプリケーションからのデータの蓄積に言及する必要があります。 情報システムの近代化、作業環境の変化、新しいソフトウェアパッケージの導入、データベース構造の再構築が行われています。 その結果、大量の情報が保存され、すでに使用されていない形式で保存されます。 ただし、多くの場合、このデータの可用性を確保する必要があるため、古いハードウェアとソフトウェアのメンテナンスに長年にわたって追加の資金が費やされています。
神話について
今日、多くの人はアーカイブシステムを時代遅れまたは無関係なテクノロジーと見なす傾向があります。 たとえば、バックアップはアーカイブを正常に置き換えると考えられています。 実際、これらはまったく交換可能な概念ではありません。 バックアップとは異なり、アーカイブは過度の重複なしに情報を保存するように設計されており、データの構造化とインデックス付けを可能にし、オプションの暗号化と異なるポリシーの適用で検索する機能を提供します。 さらに、静的データをアーカイブに転送すると、アプリケーションの負荷が軽減され、サーバークラスターとストレージのコストが削減されます。
また、アーカイブは会社の歴史を反映する一種の乱雑な情報の山であり、現在および将来のビジネス上の問題を解決するために不要であると広く信じられています。 ただし、上記では、企業の存続中に蓄積された企業の業績に関する一連のデータの分析などの傾向について既に言及しています。 Gartnerの予測によれば、2017年までに、組織の約75%が初期の情報源として独自のアーカイブを使用します。 現在、このような組織は約10%です。
アーカイブに関する次の偏見は、規制機関から不快な情報を隠したいという欲求に関連しています。 実際、アーカイブでは何かを見つけるのがはるかに簡単です。 ただし、この状況には裏返しがあります。規制当局が要求する情報を提供しなかった場合の罰金の額は、 数百万ドルに達する可能性があります。 そして、これはアーカイブを作成するための何倍もの費用です。
費用といえば。 アーカイブは高価な喜びであるという意見があります。 ただし、実際には、アーカイブシステムを使用すると大幅に節約できます。 これは、サポートのコストが削減され、主要な作業システムの生産性が向上した、安価なメディアの使用によるものです。 また、2014年には情報漏えい件数で記録的な1つとなり、盗まれたデータの量は2013年と比較して78%増加したことを思い出す必要があります。 評判と法的費用も、データ暗号化を備えたアーカイブシステムを使用するよりもはるかに高くなる可能性があります。
最後に、アーカイブの作成に対する別の議論は、ECMプラットフォームが同じ機能を提供するという意見です。 しかし、いくつかの違いがあります。 まず、アーカイブは、構造化データと非構造化データを同時に使用できるように設計されています。 何十億ものレコードやドキュメントを保存するために最適化されています。 第二に、前述のように、アーカイブへのデータの保存は、安価なメディアへの転送、およびバックアップのサイズの削減と作業システムのリソースの解放により安価です。
最新のサンプルのアーカイブ
最新のアーカイブシステムでは、次の5つの主要な問題を解決できます。
- 将来の使用のためにデータを保存します。
- 保存されたデータへの継続的なユーザーアクセスを保証します。
- アクセスの機密性を確保します。
- 静的データをアーカイブに転送することにより、稼働中のシステムの負荷を軽減します。
- ストレージポリシーの使用。
アーカイブのもう1つの重要な特性は、単一のデータベースに構造化および非構造化情報を保存することです。 当然、データベースは、水平方向にスケーラブルな別のストレージシステムに展開する必要があります。これにより、データボリュームが増加してもアーカイブを簡単に拡張できます。
同様のソリューションとして、 EMC InfoArchiveを使用できます。 これは包括的な製品であり、「アーカイブと暗号化のためのSHD +ソフトウェアプラットフォーム」の組み合わせです。 InfoArchiveは、異種システムから継承されたデータを異なる形式で保存する必要がある場合や、データレイクを分析するタスクにも役立ちます。 「データレイク」とは、階層構造のないソース形式の非常に大量の生データを持つリポジトリを意味します。
特定の条件(構造化および非構造化データの量、会社がサポートするレガシーシステムの可用性と構成、分析ツールの使用、クラウドサービスの作成など)に応じて、 InfoArchiveはEMC Isilon 、 DataDomain 、 AtmosまたはCenteraに基づいて構築できます。 選択したストレージシステムで、xDBに基づいて、オープンXML標準やOAIS (オープンアーカイブ情報システム)などの多数の国際標準を使用して、EMC Documentum Dynamic Delivery Services (DDS)データベースが展開されます。
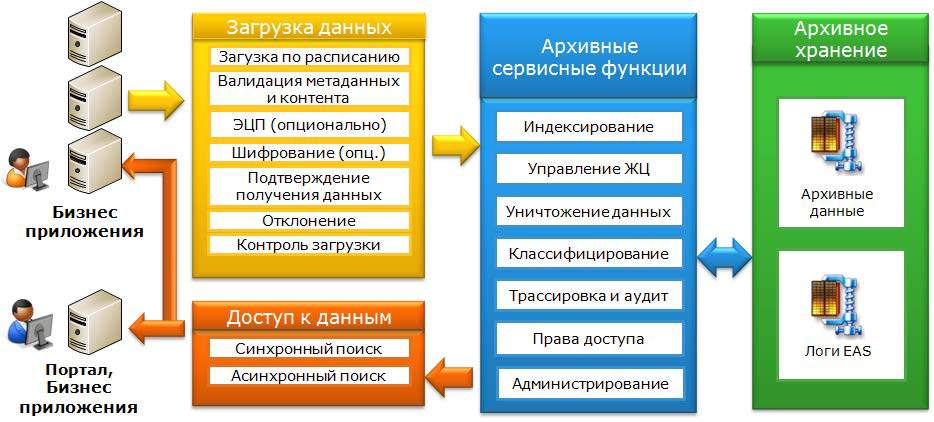
InfoArchiveの機能は、顧客がOAIS標準への準拠を必要としない場合、OAIS標準に従って、SIP情報パケットの形式で、または単純なXML構造の形式で、すべてのデータをシステムに転送する必要があることです。 また、InfoArchiveに保存されているすべての情報は、元のアプリケーションで後で使用/回復するためにJDBCを介してアクセスできます。

リレーショナルデータベースのデータは、リンクテーブルの形式で表示されます。 ユーザーが何らかの情報を要求すると、アプリケーションはテーブルに従ってクエリを送信し、受信した回答を集計してユーザーに提供します。


XMLファイルは、構造化情報と非構造化情報のメタデータの保存、整理、および転送に使用されます。 これにより、異なるアプリケーションのデータを組み合わせたアーカイブを作成できます。 InfoArchiveは、保存されているすべてのデータを検索し、ストレージポリシーを使用し、オンザフライで暗号化を提供し、特定のデータとそのセットへのアクセスを管理する機能を実装します。 アーカイブのサイズに関係なく、使用されるDBMSは1つだけです。
システムのパフォーマンスは、ストレージの数と構成、およびプラットフォーム自体の構成に依存します。 たとえば、一部のクライアントでは、構造化データの取得におけるInfoArchiveのパフォーマンスは200万レコード/時間(最大60 Gb /時間)に達します。 システムは1時間あたり最大15,000の検索クエリを処理でき、1つのドキュメントの検索には平均 0.5秒、レコード-2.5秒かかります。
データを保護するには、EMC RSA KeyManagerを使用したアクセスポリシーと暗号化が使用されます。 InfoArchiveは、他の暗号化システムと統合することもできます。
おわりに
今日、アーカイブシステムは主に、データ量の増加の問題が最も深刻な企業に実装されており、規制当局の要求に応じて保存および利用可能にする必要があります。 まず第一に、それは金融セクター、電気通信産業、公益事業、公共セクターです。 そして、当社の慣行が示すように、中規模企業はアーカイブへの関心を積極的に示しており、積極的に市場での地位を強化しようとしています。 情報時代の到来の視覚的証拠。