42bcfae8-2ecc-438f-9e0b-841575de7479
これらの番号はさまざまなテーブルのキーとして機能しますが、最初の値は、まず、Cookieが読み込まれたページのURL、検索クエリ、および場合によってはプロバイダーが提供する追加情報(IPアドレス、タイムスタンプ、顧客情報)です。などなど。 このデータはかなり異種であるため、セグメンテーションにとってURLが最も価値があります。 新しいセグメントを作成するとき、アナリストはアドレスのリストを示し、これらのページのいずれかにクッキーが表示されると、対応するセグメントに分類されます。 検索エンジン、Yandex.Wordstat、およびその他のツールとの骨の折れる作業の結果として、このようなアナリストの作業時間のほぼ90%が正しいURLセットを見つけるために費やされていることがわかりました。
このようにして1,000を超えるセグメントを取得したため、アルゴリズムの品質を監視し、新しいツールを使用するための便利なインターフェイスをアナリストに提供しながら、このプロセスを可能な限り自動化および簡素化する必要があることに気付きました。 カットの下で、これらの問題をどのように解決するかを説明します。
したがって、導入部から理解できるように、実際には、ユーザーをセグメント化する必要はありませんが、インターネットサイトのページです。分析エンジンは、受信したセグメントごとにユーザーを自動的に配信します。
DMPでセグメントがどのように表されるかについて、いくつかの言葉を述べる価値があります。 一連のセグメントの主な特徴は、その構造が階層的である、つまりツリーであることです。 次のレベルごとにユーザーの関心の肖像をより正確に記述することができるため、階層の深さに制限を課しません。 階層のいくつかのブランチの例を次に示します。
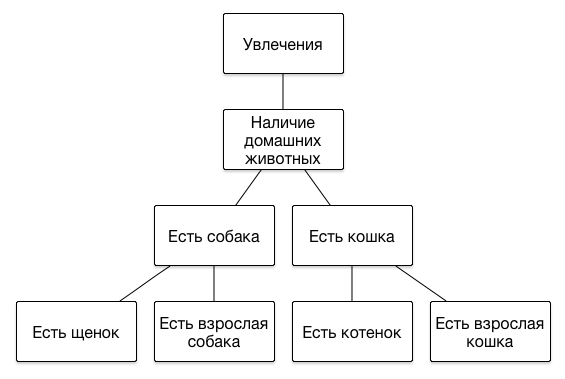
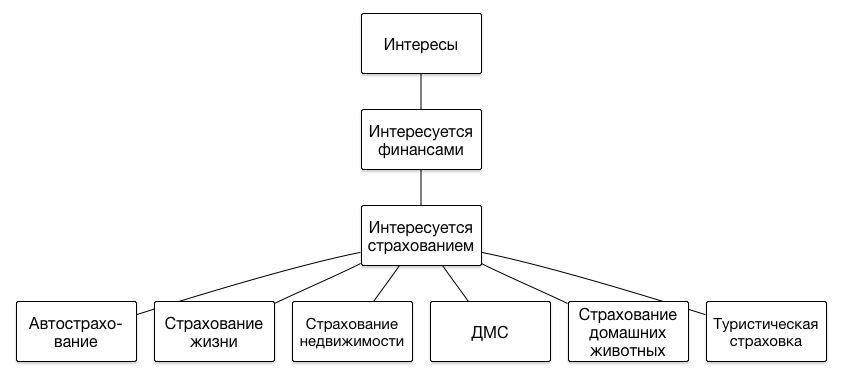
ユーザーが子犬に餌をやる方法や猫をトレーで飼う方法について話しているサイトにアクセスした場合、その動物を所有している可能性が高いため、適切な広告を表示するのが理にかなっています-獣医クリニックまたは新しい飼料ラインについて。 そして、その前にオンラインストアでプレミアムブランドの服を選んだ場合、彼は比較的高い収入を得ることができ、猫の心理学者や犬の美容師など、より高価なサービスを宣伝できます。
一般に、インターネットページ上のトピックのある種の手動分類を使用する場合、入力URLを受信し、それに適したトピックのリストを出力するサービスを作成する必要がありました。 「1対すべて」のスキームに従って、Webページの主題をマルチクラス分類問題として定義する問題を解決します。つまり、分類ノードごとに、独自の分類子がトレーニングされます。 分類子は、トピックツリーのルートから始まり、さらに現在の各レベルで適切であると識別されたブランチまでさらに再帰的に管理されます。
分類器デバイス
分類子のフロントエンドは、メモリにオブジェクトを保持するFlaskアプリケーションです。 基本的に、データを準備し、 mongoDBに格納されているsklearn.ensemble.RandomForestClassifierクラスの訓練された分類子のオブジェクトをデシリアライズし、それらのpredict_proba()メソッドを実行し、既存の分類法に従って結果を処理します。 ちなみに、分類とクエリおよびテストの選択もmongoDBに保存されます。
アプリケーションは、次の形式のURIによるPOST要求を待機しています。
- localhost / text /
- localhost / url /
- localhost /トークン/
classifier = RecursiveClassifier() app = Flask(__name__) @app.route("/text/", methods=['POST']) def get_text_topics(): data = json.loads(request.get_data().decode()) text = data['text'] return Response(json.dumps(classifier.get_text_topics(text), indent=4), mimetype='application/json') @app.route("/url/", methods=['POST']) def get_url_topics(): data = json.loads(request.get_data().decode()) url = data['url'] html = html_get(url) text = clean_html(html) return Response(json.dumps(classifier.get_text_topics(text,url), indent=4), mimetype='application/json') @app.route("/tokens/", methods=['POST']) def get_tokens_topics(): data = json.loads(request.get_data().decode()) return Response(json.dumps(classifier.get_tokens_topics(data), indent=4), mimetype='application/json') if __name__ == "__main__": app.run(host="0.0.0.0", port=config.server_port)
たとえば、URLを取得すると、アプリケーションはその本文をダウンロードし、そこから直接ページテキストを引き出し、ルートから子への分類法の再帰的なトラバースを開始します。 再帰は、現在のステップで、ページがこのノードに属する確率が構成で指定されたしきい値を超えるツリーノードに対してのみ発生します。
データの準備には、テキストの1回限りのトークン化、単語頻度特性の計算、および特徴選択段階で選択されたトークンの重みに基づく各分類子の特徴変換が含まれます(詳細は後述)。 この場合、「 ワードバッグ 」モデルが使用されます。つまり、テキスト内の単語の相対位置は無視されます。
分類器トレーニング
学習プロセスはバックエンドを実行します。 分類法または一部のノードへのクエリのリストを変更すると、新しいページのテキストがダウンロードされてトークン化され、変更されたものと同じレベルのすべてのトピックの学習アルゴリズムが起動されます。 レベル全体のトレーニングサンプルは同じであるため、分類子のすべての「兄弟」は変更されたものと一緒に再トレーニングされます。これは、すべての兄弟ノードとそのすべての子からの要求によって見つかったTOP-50 Bing検索結果のサイトのテキストです。 各トピックの肯定的な例は、自分のニーズと子供のニーズに一致するサイトであり、他のすべてのページは否定的な例です。 結果はpandas.DataFrameオブジェクトに保存されます。
結果として得られるラベル付きトークンのセットは、トレーニングサンプル(70%)、機能選択用サンプル(15%)、およびテストサンプル(15%)にランダムに割り当てられ、mongoDBに保存されます。
機能選択
最も有益なトークンは、学習プロセスでdgメトリックを使用して選択されます。これが実装方法です。
def dg(arr): avg = scipy.average(arr) summ = 0.0 for s in arr: summ += (s - avg) ** 2 summ /= len(arr) return math.sqrt(summ) / avg
そして、これはトークンのセットのためにどのように呼び出されるかです:
token_cnt = Counter() topic_cnt = Counter() topic_token_cnt = defaultdict(lambda: Counter()) for row in dataset.index: topic = dataset['topic'][row] topic_cnt[topic] += 1 for token in set(dataset['tokens'][row]): token_cnt[token] += 1 topic_token_cnt[topic][token] += 1 topics = list(topic_cnt.keys()) token_distr = {} for token in token_cnt: distr = [] for topic in topics: distr.append(topic_token_cnt[topic][token] / topic_cnt[topic]) token_distr[token] = distr token_dg = {} for token in token_distr: token_dg[token] = dg(token_distr[token]) * math.log(token_cnt[token])
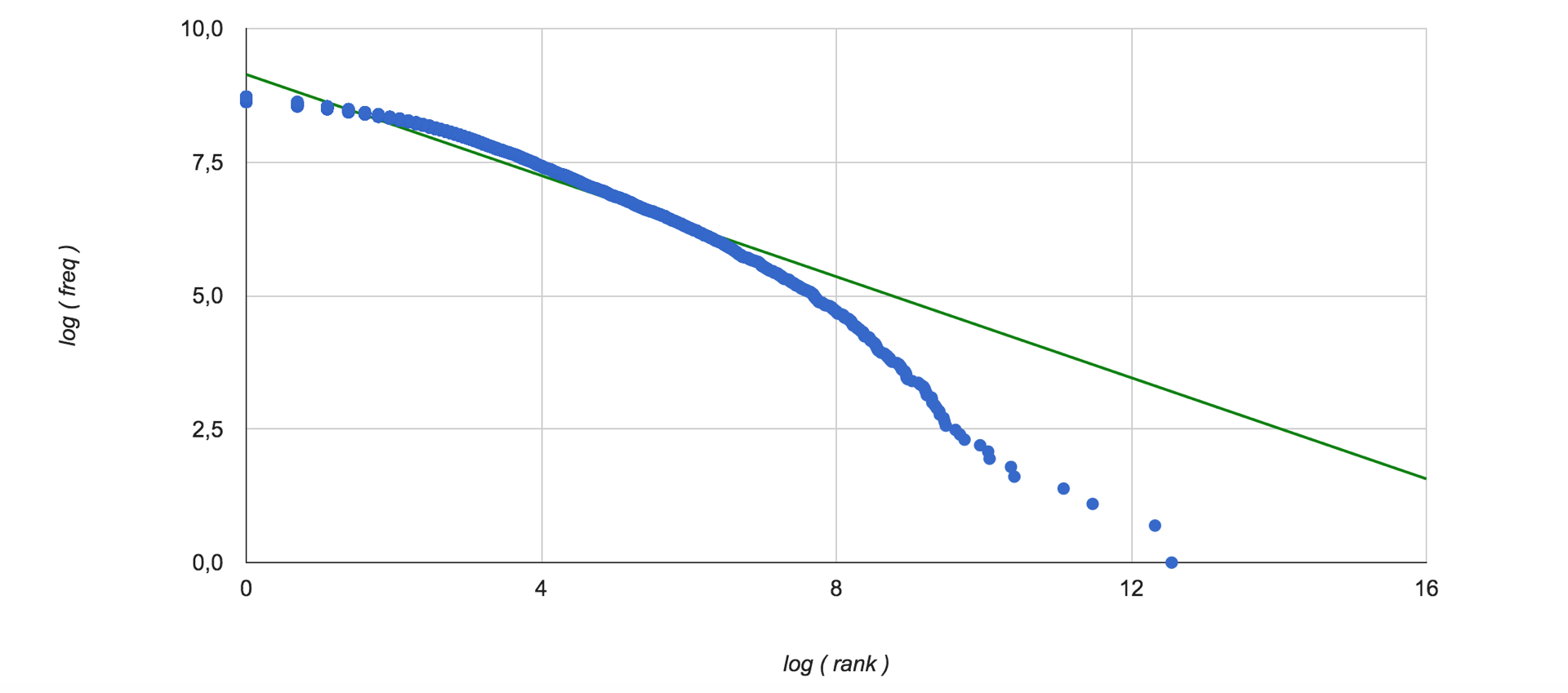
したがって、トレーニングサンプルのすべてのテキストに関する単語の重要性が評価されます。 コレクション内の単語の出現頻度特性が使用されるため、 Zipf分布を調べるのは興味深いです。 ここにあります(データの線形補間は緑色で表示されます):
さらに、学習プロセス中を含む分類されたテキストのベクトル化のために、このようにして得られた重みに特定のテキスト内の単語の頻度が乗算され、所定の分類レベルで各主題のこの量の最高値を持つ5つの単語が選択されます。 これらのベクトルは連結され、長さ5 * mのベクトルになります。ここで、mはレベルのノード数です。 これで、データを分類する準備ができました。
分類子の品質評価
分類器全体の作業を評価するために1つの数値を取得できるようにしたかったのです。 分類法の個々のノードの正確性、完全性、およびFメジャーを簡単に計算できることは明らかですが、100を超えるクラスが含まれている場合、ほとんど使用できません。 分類子は階層的であるため、下位ノードの個々の分類子の作業品質は前の分類子の品質に依存します。これはアルゴリズムの重要な機能です。 精度とリコールは、次の式を使用して計算されます。

(TPは真の陽性結果の数、FNは偽偽の数など)
Fメジャーは、完全性と精度の間の調和平均であり、パラメータßを使用して、これらの量が結果に入る比率を設定できます。
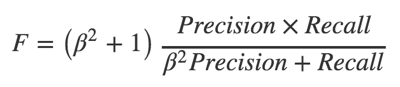
ß> 1の場合、メトリックは完全性に偏る傾向があり、0 <ß<1の場合、精度の側面に偏ります。 現在のレベルで各トピックのテストサンプルの肯定的な例の割合に従ってこのパラメーターを選択します。分類器がさらにスキップするベクトルが多いほど、次の間違いを犯す可能性が高くなるなどです。
次のステップは、ツリーの各独立ブランチ、つまり、最初のレベルからの親のすべての子ノードの平均Fメジャーを計算することです。 各ノードについて、トレーニングサンプルの構成を考慮してFメジャーが計算されるため、追加の重みなしでブランチ内のすべての分類子の平均Fメジャーを計算するだけで十分です。
分類子全体の単一のメトリックは、ブランチメトリックの加重平均として計算されます。重みは、サンプル内のポジティブブランチの例の割合です。 ここでは、単純な平均を省くことができません。 異なるブランチのノードと検索クエリの数は大きく異なる可能性があります。 このようにして計算された、分類器全体のFメジャーの値は〜0.8を誇っています。
分類子をテストするとき、フィードバックを回避するために、トークンのリストから関連する検索クエリの単語を削除することに注意することが重要です。
テスト結果を視覚化するために、 Google OrgChartが使用されます。まず、分類法のツリー構造を視覚的に表現します。また、各ノードでメトリック値を指定し、シート内に直接カラーインジケーターを掛けることもできます。 ブランチの1つは次のようになります。
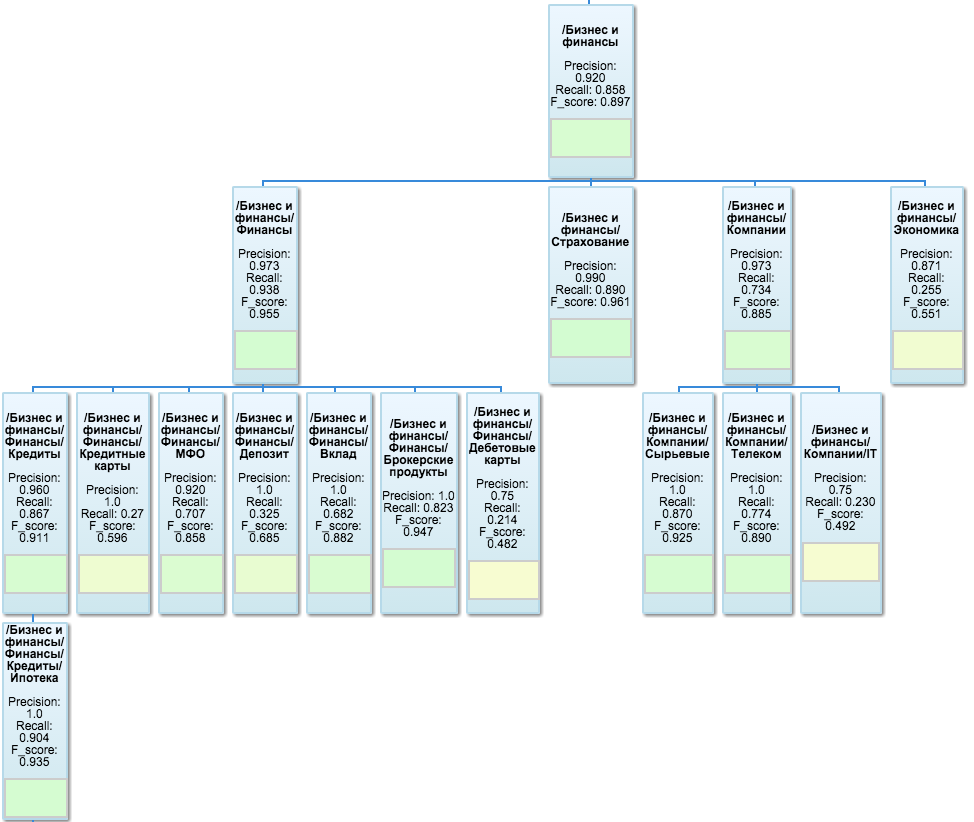
テスターは別のFlaskアプリケーションとして実装され、要求に応じて、計算されたメトリック値をmongoDBからダウンロードし、最後の計算以降に分類子で起こりうる変更のために不足しているものをさらに計算し、組織図を描画します。 便利な追加機能として、そこから簡単なインターフェイスも使用できます。これにより、URLのリストまたはプレーンテキストをテキストフィールドに挿入して、分類結果を確認できます。
DMP統合
同様のサービスがあるので、積極的に使用する必要があります。 毎日、最後の日から最も訪問された数百万のサイトがDMPから選択され、分類器を通過します。 これらのサイトは、ヒットしたセグメントのIDでマークされ、先月にこれらのページにアクセスしたユーザーはこれらのセグメントに分類されます。 現在、1ページの分類には約0.2〜0.3秒かかります(マイナスレイテンシホスティング)。
このアプローチでは、1日に数千のURLを自動的にセグメントに割り当てることができますが、アナリストは通常、100ページ以下しか追加しません。 これで、アナリストの仕事は検索クエリに適したトピックの選択のみに削減され、DMPは残りの作業を彼に任せ、これがどの程度うまく行われたかを示します。
今後の計画
まず第一に、分類器の実用的なプロトタイプを実装するタスクに直面しました。この段階では、推定器やその他の設定に最適なパラメーターを選択することに特に煩わされませんでした。 ただし、このような非常に単純な数学的モデルが非常にまともな作業品質を示すとは期待していませんでした。 もちろん、発音されたアルゴリズムのすべての定数を柔軟に調整できます。最適な設定の選択については、別の記事で説明します。 次の作業の計画:
- 非同期でアクセスできるように、分類子を非ブロッキングTornadoサーバーに転送します。
- dgメトリックに加えて、 tf-idfのさまざまなバリエーションを検討します。
- ページおよびメタタグのタイトルに含まれる単語を考慮に入れます。
- 推定器の多数の設定を調整し、ランダムフォレストをSVMアンサンブルに置き換えて、分類用に選択する単語の数を増やします。
話が面白かったと思います。 コメントでは、あなたの質問に答え、分類器を改善するための提案を喜んで議論します。