
「ホット」で頻繁に議論されるコンバージョン最適化のトピックは、オンラインビジネスの経済効率の向上に関連する特定のテクノロジー/ソリューションのパフォーマンスに関する真実を見つける唯一の客観的な方法として、A / Bテストの無条件の普及につながりました。
この人気の背景には、実験結果の整理、実施、分析における文化のほぼ完全な欠如があります。 Retail Rocketでは 、電子商取引におけるパーソナライゼーションシステムの費用対効果を評価する上で優れた専門知識を獲得しています。 2年で、A / Bテストを実施するための理想的なプロセスが再構築されました。このプロセスをこの記事のフレームワークで共有したいと思います。
A / Bテストの原則に関する2つの言葉
理論的には、すべてが非常に単純です。
- 何らかの変更(たとえば、 メインページのパーソナライズ )によってオンラインストアのコンバージョンが増加すると仮定します。
- サイト「B」の代替バージョンを作成します。変更を加えた元のバージョン「A」のコピーから、サイトの効率が向上することが期待されます。
- サイトへのすべての訪問者は、2つの等しいグループにランダムに分割されます。1つのグループは元のバージョンを示し、2番目は代替バージョンを示します。
- 同時に、サイトの両方のバージョンのコンバージョンを測定します。
- 統計的に有意な勝利のオプションを決定します。
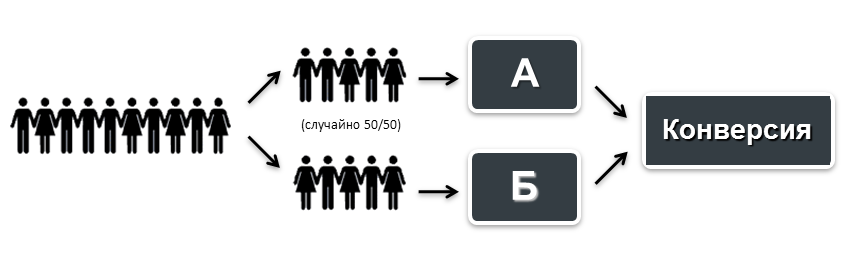
このアプローチの利点は、数値を使用して仮説を検証できることです。 疑似専門家の意見を主張したり、それに頼ったりする必要はありません。 テストを開始し、結果を測定し、次のテストに進みました。
数字の例
たとえば、サイトに変更を加え、A / Bテストを開始し、次のデータを受け取ったとします。
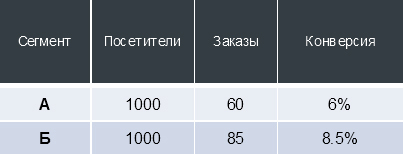
変換は静的な値ではなく、「試行」と「成功」の数に応じて(オンラインストアの場合-それぞれサイトへの訪問と発注)、変換は推定確率で特定の間隔で分散されます。
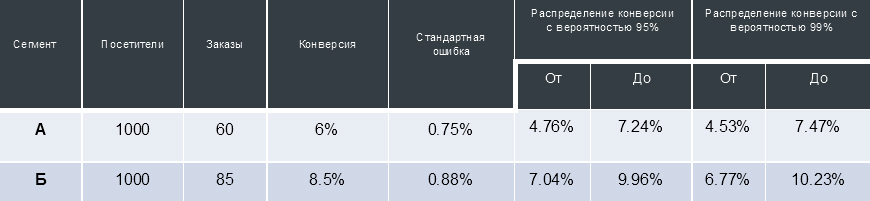
上記の表の場合、これは、一定の外部条件の下でサイト「A」のバージョンにさらに1000人のユーザーを連れてきた場合、99%の確率でこれらのユーザーは45から75の注文を出します(つまり、4.53%から7.47の比率で顧客に変換されます) %)。
それ自体では、この情報はあまり価値がありませんが、A / Bテストを実施する場合、2つの変換配布間隔を取得できます。 サイトの異なるバージョンと対話するユーザーの2つのセグメントから受信したコンバージョンのいわゆる「信頼区間」の共通部分を比較することで、サイトのテスト済みバージョンの1つが他のバージョンよりも統計的に有意に優れていると判断し、述べることができます。 グラフィカルには、次のように表すことができます。
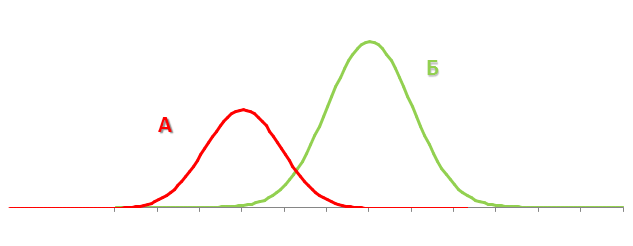
A / Bテストの99%が間違っているのはなぜですか?
そのため、大多数の人は既に実験を行うという上記の概念に精通しており、業界のイベントでそれについて話し、記事を書きます。 Retail Rocketでは、10〜20のA / Bテストが同時に行われています。過去3年間で、多くの場合に気付かれないほどのニュアンスに遭遇しました。
これは大きなリスクです。A/ Bテストがエラーで実行された場合、ビジネスは間違った決定を下し、隠れた損失を受け取ることが保証されます。 さらに、以前にA / Bテストを実行した場合、ほとんどの場合、それらは誤って実行されました。
なんで? お客様のオンラインストアにRetail Rocketを導入する際に、実験結果の多くのテスト後分析を実施するプロセスで遭遇した最も一般的な間違いを分析します。
テストでのオーディエンスシェア
おそらく最も一般的な間違いは、テストを開始したときに、サイトのすべてのユーザーがそれに関与していることを確認できないことです。 かなり一般的な例(Googleアナリティクスのスクリーンショット):
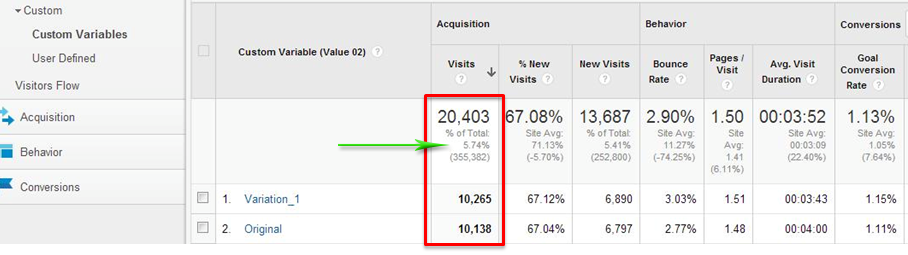
スクリーンショットは、合計で6%未満の視聴者がテストに参加したことを示しています。 サイトのオーディエンス全体がテストセグメントのいずれかに属していることが不可欠です。そうでない場合、ビジネス全体に対する変更の影響を評価することは不可能です。
テストされたバリエーション間の聴衆の均一な分布
サイトのオーディエンス全体をテストセグメントに配布するだけでは不十分です。 これをすべてのスライスで均等に行うことも重要です。 顧客の1人の例を考えてみましょう。

サイトのオーディエンスがテストセグメント間で不均等に分割されている状況に直面しています。 この場合、テスト用のツール設定で50/50のトラフィック区分が設定されました。 このような写真は、トラフィック分散ツールが期待どおりに機能していないことを明確に示しています。
さらに、最後の列に注意してください。2番目のセグメントがより繰り返され、したがってより忠実な視聴者になることは明らかです。 そのような人々はより多くの注文を行い、テスト結果をゆがめます。 そして、これは誤ったテストツールの別の兆候です。
テストを開始してから数日後にこのようなエラーを解消するには、使用可能なすべてのスライス(少なくとも都市、ブラウザ、プラットフォームごと)でトラフィック区分の均一性を常に確認してください。
従業員のオンラインストアのフィルタリング
次の一般的な問題は、オンラインショップの従業員に関連しています。従業員は、テストセグメントの1つに入って、電話で注文しました。 したがって、従業員はテストの1つのセグメントで追加の売り上げを形成しますが、発信者はすべてです。 もちろん、このような異常な動作は最終結果をゆがめます。
コールセンターのオペレーターは、Googleアナリティクスのネットワークに関するレポートを使用して特定できます。

 スクリーンショットは私たちの経験からの例です。訪問者は「Presnyaの電子ショッピングセンター」というネットワークから14回ウェブサイトにアクセスし、35回注文しました。これは、何らかの理由でウェブサイトのバスケットを介して注文した店員の明確な行動です。ストア管理パネルからではありません。
スクリーンショットは私たちの経験からの例です。訪問者は「Presnyaの電子ショッピングセンター」というネットワークから14回ウェブサイトにアクセスし、35回注文しました。これは、何らかの理由でウェブサイトのバスケットを介して注文した店員の明確な行動です。ストア管理パネルからではありません。
いずれの場合でも、いつでもGoogleアナリティクスから注文をアップロードして、「オペレーターが発行した」または「オペレーターが発行した」プロパティを割り当てることができます。 次に、スクリーンショットのようにピボットテーブルを作成します。これは、頻繁に発生する別の状況を反映しています。RRセグメントとRRセグメント以外のセグメント(それぞれ「Retail Rocketがあるサイト」と「なし」)なしよりも少ないお金。 しかし、コールセンターのオペレーターからの注文を除外すると、Retail Rocketの収益は10%増加します。
結果の最終評価では、どの指標に注意する必要がありますか?
昨年、A / Bテストが実施されました。その結果は次のとおりです。
- 「Retail Rocketのあるサイト」セグメントでのコンバージョンに+ 8%。
- 平均チェックは実質的に変化しませんでした(+ 0.4%-エラーレベル)。
- 「Retail Rocketを使用したWebサイト」セグメントの収益成長率+ 9%。
結果を報告した後、クライアントから次の手紙を受け取りました。
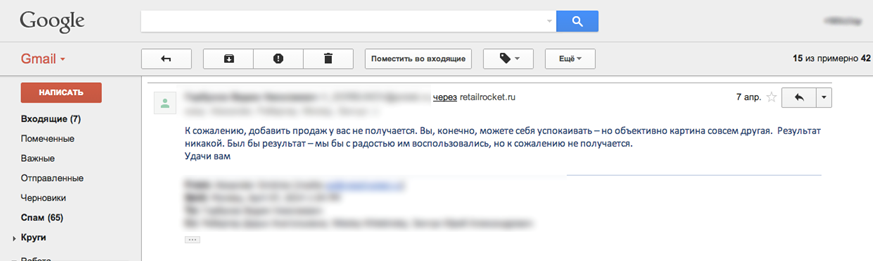
オンラインストアのマネージャーは、平均チェックが変更されていなければ、サービスからの影響はないと主張しました。 同時に、推奨システムによる総収益の増加という事実は完全に無視されます。
それで、どの指標に焦点を合わせるべきですか? もちろん、ビジネスにとって最も重要なことはお金です。 A / Bテストのフレームワークでトラフィックが訪問者のセグメント間で均等に分割された場合、比較に必要な指標は各セグメントの収益です。
人生では、トラフィックをランダムに分割するための単一のツールが完全に等しいセグメントを与えるわけではなく、割合の割合に常に違いがあるため、セッション数で収益を正規化し、「訪問あたりの収益」メトリックを使用する必要があります。
KPIの世界では認識されています。A/ Bテストを実施する際に焦点を当てることをお勧めします。
サイトでの注文からの収益と「完了した」収益(実際に支払われた注文からの収益)はまったく異なるものであることを覚えておくことが重要です。
以下は、 小売ロケットシステムを別の推奨システムと比較したA / Bテストの例です。

非小売ロケットセグメントはあらゆる点で勝ちます。 ただし、テスト後分析の次の段階では、コールセンターの注文とキャンセルされた注文は除外されました。 結果:

結果のテスト後の分析-A / Bテストを実施する際には必須です!
データスライス
さまざまなデータスライスの操作は、テスト後の分析において非常に重要なコンポーネントです。
これは、ロシア最大のオンラインストアの1つでの別のRetail Rocketテストケースです。

一見したところ、収益の伸び+ 16.7%という素晴らしい結果が得られました。 ただし、レポートに追加のデータスライス「デバイスタイプ」を追加すると、次の図を見ることができます。
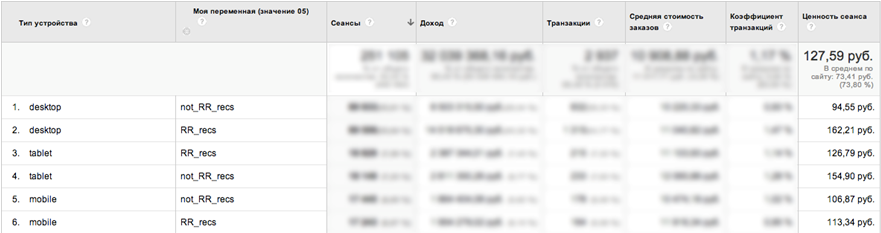
- ほぼ72%のデスクトップトラフィック収益の増加!
- Retail Rocketセグメントのタブレットで、ドローダウン。
テスト後に判明したように、Retail Rocketの推奨ブロックはタブレットに正しく表示されませんでした。
事後分析のフレームワークでは、少なくとも都市、ブラウザ、ユーザープラットフォームのコンテキストでレポートを作成し、そのような問題を見逃さないようにして結果を最大化することが非常に重要です。
統計的信頼性
次に取り組むべきトピックは、統計的妥当性です。 サイトへの変更の導入に関する決定は、優位性の統計的信頼性を達成した後にのみ可能です。
変換の統計的信頼性を計算するために、 htraffic.ru / calc /などの多くのオンラインツールがあります。

しかし、サイトの経済効率を決定する指標はコンバージョンだけではありません。 現在のほとんどのA / Bテストの問題は、変換の統計的信頼性のみがチェックされることであり、これは不十分です。
平均チェック
オンラインストアの収益は、コンバージョン(購入者の割合)と平均小切手(購入サイズ)から成り立っています。 平均チェックの変化の統計的信頼性を計算することはより困難ですが、これがないと、間違った結論が避けられません。
スクリーンショットは、小売ロケットA / Bテストの別の例を示しています。このテストでは、100万ルーブル以上の注文がセグメントの1つに分類されました。
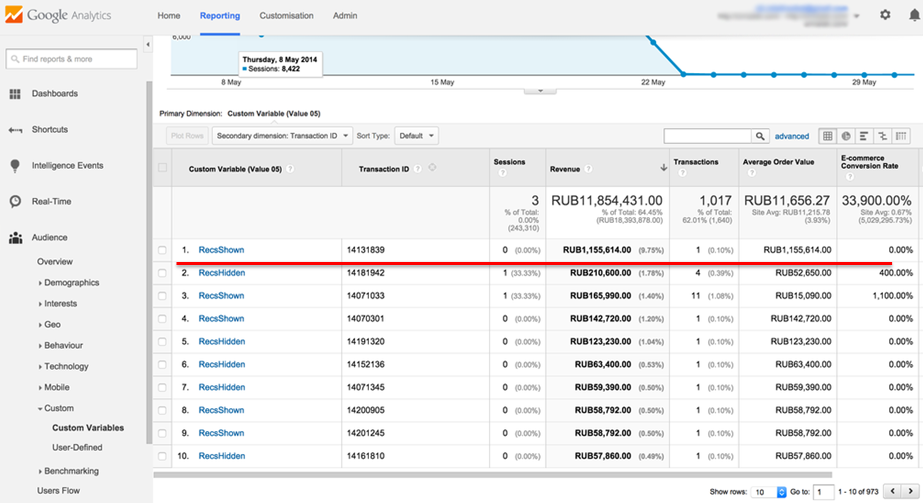
この注文は、テスト期間の総収益のほぼ10%です。 この場合、変換の統計的信頼性が達成されると、収益結果は信頼できると見なされますか? もちろん違います。
このような巨大な注文は結果を大きく歪めます。平均請求額に関してポストテスト分析には2つのアプローチがあります。
- 複雑な 「 ベイジアン統計 」。これについては、今後の記事で説明します。 Retail Rocketでは、これを使用して、推奨アルゴリズムを最適化するための内部テストの平均チェックの信頼性を評価します。
- シンプル。 降順でソートされたリストの上下(通常3〜5%)のオーダーのパーセンタイルを切り捨てます。
試験時間
そして最後に、テストをいつ実行し、どのくらい続くかを常に注意してください。 性別の主な休日の数日前と休日/週末にテストを実行しないようにしてください。 季節性も給与レベルで観察されます。原則として、これは高価な商品、特に電子機器の販売を刺激します。
さらに、店舗での平均チェックと購入前に決定を下すのにかかる時間との間には、実証済みの関係があります。 簡単に言えば、商品が高価であればあるほど、選択する時間が長くなります。 スクリーンショットは、ユーザーの7%が購入前に1〜2週間考えている店の例を示しています。
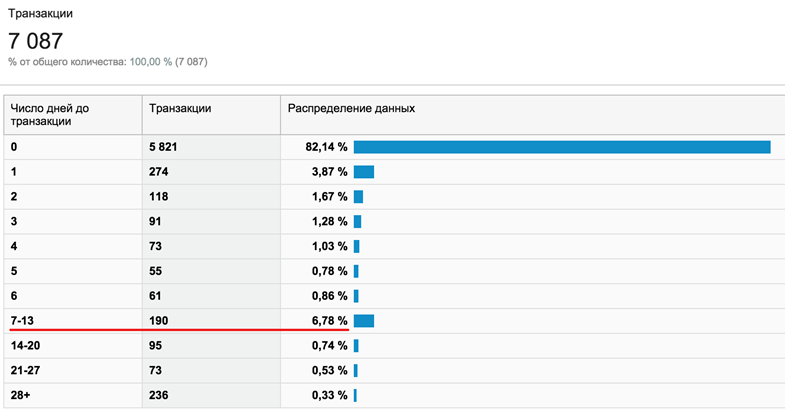
そのような店舗で1週間以内にA / Bテストを実施した場合、約10%の視聴者がそれに該当せず、ビジネスに対するサイトの変更の影響を明確に見積もることができません。
出力の代わりに。 完璧なA / Bテストを実施するには?
したがって、上記のすべての問題を排除し、正しいA / Bテストを実行するには、3つのステップを実行する必要があります。
1. 50/50トラフィックを分割する
難しい:トラフィックバランサーを使用します。
シンプル: Retail RocketチームがサポートするオープンソースのRetail Rocket Segmentatorライブラリを使用します。 数年間のテストでは、OptimizelyやVisual Website Optimizerなどのツールで上記の問題を解決できませんでした。
最初のステップの目標:
- 利用可能なすべてのセクション(ブラウザ、都市、トラフィックソースなど)で視聴者を均等に分散します。
- 聴衆の100%がテストに参加する必要があります。
2. A / Aテストを実行します
サイトで何も変更せずに、異なるユーザーセグメント識別子(Googleアナリティクスの場合-カスタム変数/カスタムディメンション)をGoogleアナリティクス(または好みの別のWeb分析システム)に転送します。
2番目のステップの目標:勝者を獲得しない、つまり 同じバージョンのサイトを持つ2つのセグメントでは、主要な指標に違いはありません。
3.テスト後の分析
- 会社の従業員を除外します。
- 極端な値を切り捨てます。
- コンバージョン値の値を確認し、注文の実行とキャンセルに関するデータを使用します。 上記のすべてのケースを考慮してください。
最後のステップの目標:正しい決定を下す。
コメントでA / Bテストケースを共有してください!