
当社が作業の最初の段階として開発した文書認識モジュールの一部は、着信画像またはビデオストリーム内のオブジェクトの位置を特定する必要があります。 今日の記事は、この問題を解決するために行ったアプローチの1つに当てられています。
問題の声明
まず、目的に使用できる情報を決定します。
アプリケーションでは、疑わしいタイプのドキュメントはかなり厳密に定義されています。 誰もパスポートを銀行カードの申請として真剣に認識しようとしていない、またはその逆はないと想定します。つまり、少なくとも目的のオブジェクトの割合を知っているということです。 また、大多数のモバイルデバイスには固定焦点距離のカメラが搭載されています。
見つかったものはまだ認識されていないため、ドキュメントの画像から遠くを探すのは理にかなっています。 入り口の斜めの隅に小さな文書がある写真を取得しないために、いくつかの制限を使用し、視覚化を伴います。これにより、ユーザーは撮影段階で適切なフレームレイアウトを取得できます。
具体的には、次の条件を満たす必要があります。
1-認識されたドキュメントは完全にフレーム内になければなりません。
2-文書はフレームのかなりの部分を占める必要があります。
これらの条件はさまざまな方法で実現できます。 ドキュメントがフレーム領域の少なくともX%を占めることを直接必要とする場合、ドキュメントがフレーム領域の80%を占めるのか、75%だけを占めるのかを目で判断するのは非常に難しいため、ユーザーの歯の適度な量を聞くことができます。
しかし、はるかに明白なオプションがあります。 そのため、ドキュメントの境界の各頂点に有効な長方形ゾーンを指定し、各ゾーンでドキュメントの片側が完全に横たわるようにカメラを向けることができます。
ユーザーの場合、これは次のようになります。

このメソッドは、ユーザーの可視性に加えて、ドキュメントの位置に追加の有用な制限を課します:ゾーンのサイズに基づいて、座標軸に対する側面の最大可能な傾斜角度を計算でき、その結果、90度からの四角形の角度の可能な偏差の範囲を計算できます。 まあ、または逆に、そのようなゾーンサイズを設定して、これらのパラメーターの偏差がいくつかのしきい値を超えないようにすることができます。
この場所から、ScyllaとCharybdisの間のあらゆる画像処理アルゴリズムの操作-速度と精度/作業の質を観察できます。
境界線の強調表示
まず、入力イメージをより小さなサイズに縮小して、費やす時間を削減します。 特定のユーザーケース用に選択された最適なものとして、ほとんどの部分で320ピクセルへのキャストを使用します。
ドキュメントを検索するには、側面の4つのゾーンに対応する画像領域のみが必要です。 それぞれで、ドキュメントの端である可能性のある境界線を探します。
上部領域の例として、さらに操作を検討します-残りの部分については、動作は90度(*)の回転まで類似しています。
- まず、ガウスフィルターで高周波ノイズを抑制することにより、画像の勾配を計算します。 ドキュメントの場所の制限により、直交異方性の境界、つまり 主に座標軸の1つに沿って方向付けられます(上部領域の場合、OX軸に沿って)。 このような境界を検索するには、OY軸に沿った導関数で十分です。 問題は、カラー画像がベクトル画像であり、その派生物もベクトルですが、1次元の場合、境界の重大度を評価するために、たとえばDi Zenzoによれば、より複雑に計算される完全な勾配とは対照的に、このベクトルの標準を取ることができます[ 1]。
不要な算術演算を避けるために、 規範、すなわち 各チャネルで派生モジュールを取得します
規範、すなわち 各チャネルで派生モジュールを取得します
そして、これらの値の最大値を選択します

その結果、グレースケールの微分画像になります。
- 結果のイメージをフィルター処理します。最初に、非最大値の古典的な抑制(Canny [2]を参照)を使用して初期境界マップを取得し、テクスチャによって生成された外れ値を抑制します。 これを行うには、境界の各ピクセルG(x、y)の値にそのような係数kを掛けます。

ここで、htは領域の高さで、 0の場合、y 1は上下の現在の境界に最も近い境界ピクセルのy座標、または値が欠落している場合は偽の値です。
- 境界ピクセルを接続されたコンポーネントに収集します-個々のピクセルよりも多くのクリッピングパラメーターがあります。 実装では、サイズまたは平均輝度がしきい値未満のコンポーネントは破棄されます。
*各領域の境界線(および直線)の検索は、他の領域とは無関係に行われます。つまり、完全に並列化されています。
直接検索
次のステップは、高速ハフ変換を使用して行を抽出することです[3](*)。 ハフ変換は、境界マップをバッテリーマトリックスに変換します。各マトリックスのセル(i、j)はパラメトリックに定義されたラインに対応し、そのようなアキュムレーターの局所的最大値は境界マップの最上位ラインに対応します。
多くの場合、1つのより良い直接回線では十分ではありません-制限は、誤ってテーブル/キーボード/ドキュメントよりも長くコントラストのあるもののフレームに落ちることを防ぎません。 ただし、バッテリー内のいくつかの最高値を単純に取得するというトリッキーな計画は失敗する運命にあります。各直線は実際にはバッテリー内の最大近傍を形成し(下図を参照)、最初のいくつかの最大値はほぼ同じ直線に対応する可能性が最も高くなります。
私たちの目標は、1つの直線の位置を非常に正確に見つけることではなく、多少異なる文字を入力することであるため、これは私たちには適していません。
したがって、アルゴリズムの戦闘バージョンでは、このような反復手順が実行されます。
- 境界マップ上のハフ変換
- より良い直接応答の追加
- 行数が必要な数より少ない場合は、境界マップで見つかった行を上書きして、手順1に戻ります。
得られた各行に重みを与えます-ハフ電池の対応するセルからの値です。
*高速ハフ変換とは、変換の近似ではなく、正確で高速な実装を意味します。

a)国境地図 | 
b)BPHバッテリー |
| BPHの例。 (どの行がバッテリーの各ピークに対応するかを理解しましたか?) | |
組み合わせスキーム
前の手順の後、4セットの行があります-ドキュメントの各側に1行です。 これらの行から、組み合わせ検索により、考えられるすべての四角形を構成し、その中で最も妥当なものを探します。 最初の推定値として各四角形から、組み立てられるラインの重みの合計を取得します。 以降のすべての手順は、四角形の出現特性を考慮したこの推定値の調整に当てられます。
隣接する領域の線が交差点で途切れず、それを超えて続く場合、これは目的のオブジェクトの角ではなく、他の何かである可能性が非常に高くなります。 もちろん、ドキュメントの境界線が真っ直ぐな背景に沿って位置し、さらに実際の角度であっても、画像処理中にいくつかのピクセルがはみ出る場合がありますが、一般的にこれは悪い兆候です。 角を曲がったこのような「クリープ」には罰金が科せられます。

ここで、piはi番目の角度のペナルティです。これは、角度を形成する直線に沿った交差点の後ろの境界マップ上の最初のnピクセルの強度の合計です。
 ->
-> 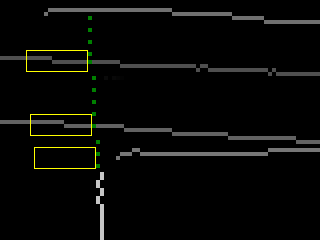
左上隅の例。 黄色は、水平線のペナルティエリアを示します。
さらに、既知の焦点距離を使用して、各四角形について、投影画像がこの四角形である平行四辺形[4](相似形のみ)を再構築します。 得られた平行四辺形の縦横比を目的の文書の既知の縦横比と比較し、その角度が文書が持つはずの正しい角度と比較してみましょう。 これらのパラメーターの予想からの逸脱について、罰金も導入します。
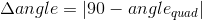
次に
 :
:

ここで、A、B、α、βは最適化された係数、
T a 、T r-しきい値。
以上です。 最も高い重みを持つ四辺形は、画像内のドキュメントの位置として取得されます。
結果
品質評価のテストサンプルは、それぞれ異なる背景にある文書の6,000枚の写真と、6,000枚の通常の四角形で構成されています。 画像の初期解像度は640x480から800x600までさまざまです。 テストデバイスはiPhone 4Sです(写真はそのデバイスから撮影され、説明されているアルゴリズム以外で指定された解像度に縮小されています)。
ドキュメントを見つける精度を評価するために、次のエラー関数が使用されました。
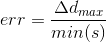
ここで、Δdmaxは、真の四角形と見つかった四角形の対応する角度間の距離の最大値です。
min(s)は、真の四辺形の最小辺の長さです。
経験的に、側面の面積が対応するサイズの30%を占める、検出されたドキュメントで十分に良好な文字認識を行うには、err値は0.06未満であることがわかった。
アルゴリズムの全体的な品質は次のように計算されました
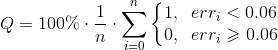
このような評価によれば、6000枚の画像のテストサンプルでは、ドキュメントの四角形は98.5%の品質です。
iPhone 4Sでのアルゴリズムの平均実行時間は0.043秒(23.2FPS)です。
スケーリング-0.014秒、
エッジ検索-0.023秒、
直接検索-0.005秒、
カットオフ付きブルートフォース-0.001秒。
文学
[1] S.ディゼンゾ。 マルチ画像のグラデーションに関する注意。
[2] J.キャニー。 エッジ検出への計算アプローチ。
[3] DPニコラエフ等。 ハフ変換:コンピュータービジョン分野で過小評価されているツール。
[4] Z.チャン。 ホワイトボードのスキャンと画像の強化。