2014年7月にリリースされたDatabase In-Memoryオプションは、Oracle Database製品ファミリーの革新についてオラクルで最も期待され、最も話題になっています。 過去数か月にわたって、オラクルの従業員はロシアのオラクルコミュニティに新しいオプションの機能を定期的に紹介してきました。
2014年モスクワでのOracle Dayでは、Igor Melnikov(Oracle)によるDatabase In-Memoryに関する理論的プレゼンテーションを実際のデモで補完する名誉がありました。 このデモンストレーションを完全に表示することはできませんでした。デモンストレーションベースに接続されたラップトップにプロジェクタを接続するのはそれほど簡単ではありませんでした。 そこで、私はHabrahabrトリビューンを使用し、それでもDatabase In-Memoryデモの本質をコミュニティに提供することにしました。
そのため、PERSONSとCREDITSの2つのテーブルがあり、フィールドの数が大きく異なります。 PERSONSテーブルの構造全体が示されています。 4つのフィールドのみがあります(COUNTRY_ID-国へのリンク、SALARY-分析用のフィールド):
| ID | NOT NULL | NUMBER |
| COUNTRY_ID | NUMBER | |
| NAME | VARCHAR 2(50) | |
| 給与 | NUMBER |
CREDITSテーブルには23のフィールドがあるため、その構造の重要な部分のみを示します(国-国へのリンク、CREDIT_LIMIT-分析用のフィールド):
| ID | NOT NULL | NUMBER |
| NAME | VARCHAR 2(50) | |
| 国 | NUMBER | |
| CREDIT_LIMIT | NUMBER |
国ディレクトリはインターネットから取得され、PERSONSおよびCREDITSテーブルはランダムに入力され、そのレコードはヨーロッパの国のみを参照します。合計で、21248349エントリがPERSONSおよびCREDITSテーブルで取得されました。
デモでの分析クエリの役割は、次の形式のクエリによって果たされます。
SQL> select sum(salary) from persons where country_id in (select id from countries where name like 'R%');
具体的には、このクエリは、文字Rを持つ国に関連付けられているPERSONSテーブル内のすべてのレコードのSALARY合計を考慮します。ヨーロッパでは、これらはロシアとルーマニアです。 さらに、クエリに参加する両方のフィールドは、PERSONSテーブルとCREDITSテーブルの両方でインメモリにスタックされます。
SQL> select table_name,COLUMN_NAME,INMEMORY_COMPRESSION from v$im_column_level where table_name in ('PERSONS','CREDITS');
| 人員 | COUNTRY_ID | クエリハイ |
| 人員 | 給与 | クエリハイ |
| クレジット | 国 | クエリハイ |
| クレジット | CREDIT_LIMIT | クエリハイ |
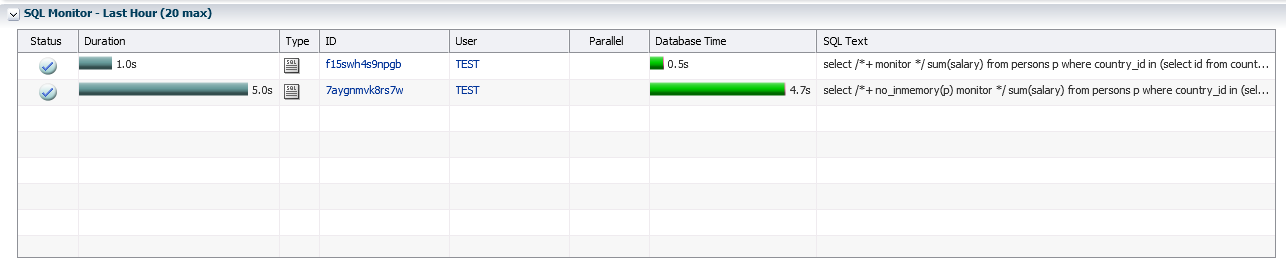
Database In-Memoryを使用した場合のPERSONSテーブルからの分析クエリの結果は5倍高速です(SQL * PlusからのタイミングとEnterprise ManagerからのSQLモニターを以下に示します)。
SQL> select /*+ no_inmemory(p) monitor */ sum(salary) from persons p where country_id in (select id from countries where name like 'R%'); Elapsed: 00:00:04.68 SQL> select /*+ monitor */ sum(salary) from persons p where country_id in (select id from countries where name like 'R%'); Elapsed: 00:00:00.48
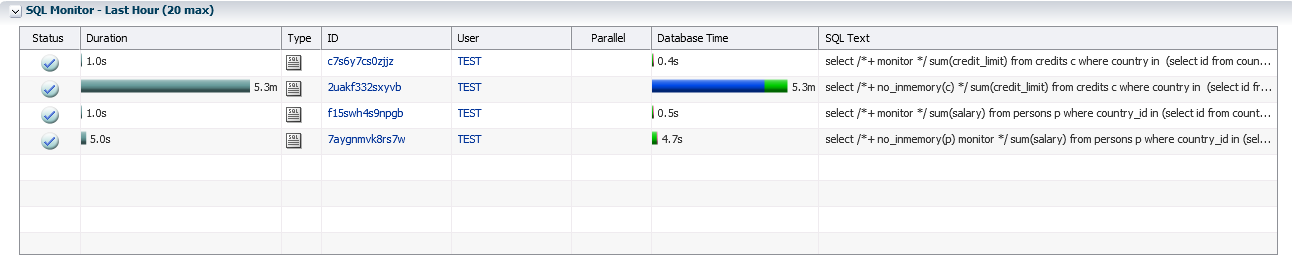
Database In-Memoryを使用しているときにCREDITSテーブルからこのような分析クエリを実行した結果は、7回よりも高速です。
SQL> select /*+ no_inmemory(c) */ sum(credit_limit) from credits c where country in (select id from countries where name like 'R%'); Elapsed: 00:05:16.35 SQL> select /*+ monitor */ sum(credit_limit) from credits c where country in (select id from countries where name like 'R%'); Elapsed: 00:00:00.43
PERSONSテーブルにはいくつかのフィールドがあり、Database In-Memoryを使用せずに意図的にメモリに配置されます。 最初の実験では、Oracle Databaseのパフォーマンスを、メモリー内の行(従来のバッファ・キャッシュ)および列(インメモリー)データ記憶域と比較します。 この実験のストレージカラムメソッドは、インメモリに実装された多くのメカニズムにより5倍のゲインを実現します。
CREDITSテーブルには多くのフィールドがあり、メモリに収まらないか、Oracle自体がキャッシュの「ウォッシュアウト」を恐れてメモリに格納することを拒否します。 2番目の実験では、メモリからの読み取りとディスクからの読み取りを比較します。これは、SQLモニターで明確に表示されます(青は入力/出力を示します)。 メモリからの読み取りは実際には数百倍高速であり、この実験で得られたゲインは700倍と非常に期待されています。
これからどの結論が導かれますか? Database In-Memoryは、クエリアクセラレーションを数百または数千回示すことができる美しい科学を実際に実装しています。 しかし、これらは特別なクエリである必要があります-たとえば、分析に必要なフィールドがほんの数個しかメモリに配置されていないような大きなテーブルでは。
また、PERSONSタイプのテーブルからのインメモリクエリをテストする場合、結果が異なる可能性があります。 ある意味では、この投稿は「Database In-Memoryオプションの操作を実演する方法と実演しない方法」という指示と見なすことができます。
建設的なコメントを歓迎します。