- ある賢い人が別の人を夢中にさせることはできますか?
- (ほとんど)ゼロから機械学習に突入する方法は?
- 多腕の盗賊を過小評価しないのはなぜですか?
- a / bテストに特効薬はありますか?
最初の質問に対する答えは最も簡潔です-はい。 YaC / Mでこの bobukの パフォーマンスを聞いて 、私はアプローチの優雅さに感心し、同様のソリューションを実装する方法について考えました。 その後、Wargamingでプロダクトマネージャーとして働いていましたが、いわゆる ユーザー獲得サービス-ユーザーを引き付けるための技術的ソリューション。これには、ランディングページのA / Bテストシステムが含まれます。 穀物は肥沃な土壌に置かれました。
残念ながら、あらゆる種類の理由で、通常の作業モードではこのプロジェクトに対処できませんでした。 しかし、私が仕事で少し燃え尽きて、長い創造的な休暇をとることに決めたとき、その強迫観念は、自分でこのようなスマート着陸ローテーションのサービスを作りたいという欲求に変わりました。
それは何ですか?
サービスのコンセプトは非常にシンプルでした。プロトタイプ段階では、異なるランディングページで新しいユーザーごとにコンバージョンを予測し、最適なページに送信するルーターに限定することにしました。 後のためにすべてのホイッスルを先送りしました 最初に予測技術を完成させる必要がありました。

機械学習に関する私の知識のレベルは、「不在」と「貧弱」の間のどこかでした。 したがって、最小限の教育プログラムから始める必要がありました。
- “ 集合的な心のプログラミング ”;
- scikit-learnによる機械学習の習得
- scikit-learn Cookbook ;
- アンドリューNgによる古典的なCourseraコース 。
- scikit-learnドキュメント(おそらく最も貴重な情報源);
Pythonは、次のように実装に適していました。 一方で、それは汎用言語であり、一方で、そのエコシステムはデータを操作するための多くのライブラリーを生成しました(特に、scikit-learn、pandas、Lasagneが役に立ちました)。 WebラッパーにDjangoを使用しました。これは明らかに最適な選択ではありませんが、新しいフレームワークを開発するために追加の時間を必要としませんでした。 今後、Djangoのパフォーマンスに問題はなく、最大3000 RPMの比較的小さな負荷で20〜30ミリ秒処理されることに注意してください。

大量のトラフィックを持つクライアントを突然テストに接続するとどうなりますか。
ワークフローは次のようなものでした:
- ユーザーがルーターにアクセスします。
- サービスは、それに関する最大量の情報を収集します(プロトタイプ段階では、DMPなどの情報プロバイダーと統合するのは愚かなことなので、HTTPヘッダー、地理位置情報、画面解像度などの技術データから始めました)。
- 分類子は、可能性のある着陸オプションの変換を予測します。
- ルーターは、潜在的に優れたランディングページへの302リダイレクトを提供します。
分類子の分類
最適なランディングページを選択するには、まず適切な分類子を選択する必要があります。 各プロジェクト(1人のクライアントのランディングページのセット)については、分類子はおそらく異なるでしょう。
- ハイパーパラメーターを選択して、履歴データで特定の数の分類器をトレーニングします。
- 現在の瞬間に最適な分類器を選択します。
- この操作を定期的に繰り返します。
間違いなく利点は、ユーザーをランディングページに直接配信するシステムの部分に関係なく、バックグラウンドで分類子をトレーニングできることです。 たとえば、実験の開始時に、モデルをトレーニングするためのデータを同時に収集し、既存の変換を損なわないように、ユーザーはa / bテストモードで配布されました。
scikit-learnを使用した分類器のトレーニングは、かなり簡単です。 最初にscikit-learnのDictVectorizerを使用してデータをベクトル化し、サンプルをトレーニングとテストに分類し、分類器をトレーニングし、予測を行い、その精度を評価するだけで十分です。
これは、生データの外観です。
(削除されたキーと値のペアの一部)
[{'1_lang': 'pl-PL', 'browser_full': 'IE8', 'country': 'Poland', 'day': '5', 'hour': '9', 'is_bot': False, 'is_mobile': False, 'is_pc': True, 'is_tablet': False, 'is_touch_capable': False, 'month': '6', 'os': 'Windows 7', 'timezone': '+0200', 'utm_campaign': '11766_', 'utm_medium': '543', 'used_landing' : '1' }, {'1_lang': 'en-US', 'REFERER_HOST': 'somedomain.com', 'browser': 'Firefox', 'browser_full': 'Firefox38', 'city': 'Raleigh', 'country': 'United States', 'day': '5', 'hour': '3', 'is_bot': False, 'is_mobile': False, 'is_pc': True, 'is_tablet': False, 'is_touch_capable': False, 'month': '6', 'os': 'Windows 8.1', 'timezone': '-0400', 'utm_campaign': 'pff_r.search.yahoo.com', 'utm_medium': '1822', 'used_landing' : '2' }, ..., {'1_lang': 'ru-RU', 'HTTP_REFERER': 'somedomain.ru', 'browser': 'IE', 'browser_full': 'IE11', 'screen': '1280x960x24', 'country': 'Ukraine', 'day': '5', 'hour': '7', 'is_bot': False, 'is_mobile': False, 'is_pc': True, 'is_tablet': False, 'is_touch_capable': False, 'month': '6', 'os': 'Windows 7', 'timezone': 'N/A', 'utm_campaign': '62099', 'utm_medium': '1077', 'used_landing' : '1' }]
(削除されたキーと値のペアの一部)
そして、このようなもの-numpy配列に変換されます:
[[ 0. 0. 0. ..., 0. 0. 1.] [ 0. 0. 0. ..., 0. 0. 1.] [ 0. 0. 0. ..., 0. 1. 0.] ..., [ 0. 0. 0. ..., 0. 1. 0.] [ 0. 0. 0. ..., 0. 0. 1.] [ 0. 0. 0. ..., 0. 0. 1.]]
ところで、多くの分類方法では、numpy配列ではなく、疎行列の形式でデータを残すほうが合理的です。 これにより、メモリ消費が削減されます。
このデータから予測する必要がある結果は、ゼロ(変換は行われませんでした)と単位(乾杯、ユーザーが登録しました!)のリストです。
from sklearn.feature_extraction import DictVectorizer from sklearn.cross_validation import train_test_split import json clicks = Click.objects.filter(project=42) # deserializing data stored as json X = DictVectorizer().fit_transform([json.loads(x.data) for x in clicks]) Y = [1 if click.conversion_time else 0 for click in clicks] # getting train and test subsets for model fitting and scoring X1, X2, Y1, Y2 = train_test_split(X, Y, test_size=0.3)
最も単純なロジスティック回帰を作成してみましょう。
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(class_weight='auto') clf.fit(X1, Y1) predicted = clf.predict(X2)
予測の品質を推定します。 評価基準の選択は、おそらくプロジェクトの最も難しい部分です。 直感的には、何も発明する必要はなく、正しい予測のシェアを推定するのに十分であるように見えますが、これは間違ったアプローチです。 最も単純な反論:ランディングページの平均コンバージョンが1%である場合、どのユーザーにもコンバージョンが発生しないと予測される最も愚かな分類子は、99%の精度を示します。
バイナリ分類問題の場合、 f1-scoreやMatthews係数などのメトリックがよく使用されます。 しかし、私の場合、重要なのはバイナリ変換の正確さではなく(変換が行われるかどうか)、予測される確率がどれだけ近いかです。 そのような場合、 ROC AUCスコアまたはlog_lossを使用できます。 Kaggleで同様のタスク( AvazuやAvitoコンテストなど)を学習すると、これらのメトリックがよく使用されることがわかります。
In [21]: roc_auc_score(Y2, clf.predict(X2)) Out[21]: 0.76443388650963591
うーん、品質はまあまあです。 そして、なぜモデルのハイパーパラメーターをソートしてみませんか? このため、scikit-learnには既製のツールがあります-grid_searchモジュールと、網羅的検索用のGridSearchCVクラスと、多くのランダム選択用のRandomizedSearchCVクラス(可能なオプションの数が多すぎる場合に便利です)。
from sklearn.metrics import roc_auc_score, make_scorer from sklearn.grid_search import RandomizedSearchCV clfs = ((DecisionTreeClassifier(), {'max_features': ['auto', 'sqrt', 'log2', None], 'max_depth': range(3, 15), 'criterion': ['gini', 'entropy'], 'splitter': ['best', 'random'], 'min_samples_leaf': range(1, 10), 'class_weight': ['auto'], 'min_samples_split': range(1, 10), }), (LogisticRegression(), {'penalty': ['l1', 'l2'], 'C': [x / 10.0 for x in range(1, 50)], 'fit_intercept': [True, False], 'class_weight': ['auto'], }), (SGDClassifier(), {'loss': ['modified_huber', 'log'], 'alpha': [1.0 / 10 ** x for x in range(1, 6)], 'penalty': ['l2', 'l1', 'elasticnet'], 'n_iter': range(4, 12), 'learning_rate': ['constant', 'optimal', 'invscaling'], 'class_weight': ['auto'], 'eta0': [0.01], })) for clf, param in clfs: logger.debug('Parameters search started for {0}'.format(clf.__class__.__name__)) grid = RandomizedSearchCV(estimator=clf, param_distributions=param, scoring=make_scorer(roc_auc_score), n_iter=200, n_jobs=2, iid=True, refit=True, cv=2, verbose=0, pre_dispatch='2*n_jobs', error_score=0) grid.fit(X, Y) logger.info('Best estimator is {} with score {} using params {}'.format(clf.__class__.__name__, grid.best_score_, grid.best_params_))
このコードは、他のコードと同様に、わかりやすくするために最大限に単純化されています。たとえば、RandomizedSearchCVの列挙用の数値パラメーターとしてリストではなく、scipy.stats分布を渡すことをお勧めします。
原則として、そこで停止することも、遺伝的アルゴリズムをこの幸福に結びつけることもできませんでした。 しかし、予測の質はすでに多かれ少なかれ十分になっているようです:
In [27]: roc_auc_score(Y2, clf.predict(X2)) Out[27]: 0.95225886338947252
残念ながら、モデルがすでに良好であるか、まだ調整が必要な場合、明確な基準はありません。 チューニングの可能性は無限です。フィーチャの多項式の組み合わせを追加したり、既存のフィーチャに基づいてフィーチャを設計したりできます(たとえば、リファラーサイトのトピックを決定できます)。 それでも、すべての種類の操作で具体的な効果が得られなくなったら、次の段階に進む時間です。さもなければ、分類子をさらに0.00001%改善するのに多くの時間を費やすことができます。
ハイパーパラメーターが定義された後、分類器はサンプル全体で訓練され、迅速なアクセスのためにキャッシュに入れられます。
サンドボックスから本番まで
そのため、分類子が機能しています。 生産の時間です! その直前に、何が良くて何が悪いかを決める必要があります-数学と機械学習の観点からではなく、ビジネスのために。
なぜなら プロジェクト全体がコンバージョンの増加に関するものであるため、A / Bテストを再度手配する必要があります。 より正確には、メタテスト:
- トラフィックの一部は、着陸間でランダムに分配されます。
- 部品については、A / Bテストは多腕バンディットの最も単純なモデルに従って機能します。
- 最後に、残りのトラフィックは分類子を使用して配信されます。
展開、テストクライアントとの打ち上げの議論、小さなバグのデバッグ-そして、結果を楽しみにしています。
個人的には、A / Bテストのプロセスで最も不快なのは中間結果です。 定期的に、最初のオプションが押し進められるという状況が発生しますが、統計的有意性はまだありませんが、良い結果が得られたようです。 しばらくすると、データはさらに多くなり、すべてがそれほどバラ色ではないことが理解されます。
今回もほぼ同じでした。 分類子の助けを借りた「スマート」ルーティングは最初に前進し、その後、結果は多腕バンディットとほぼ同等でした。 着陸の選択の両方のモデルは、ほぼ等しく効果的であることが判明し、ランダムを残しました(驚くことではありません)。 6つの実験のうち1つだけが、A / Bテストよりもこのようなルーティングの統計的に有意な利点を示しました。
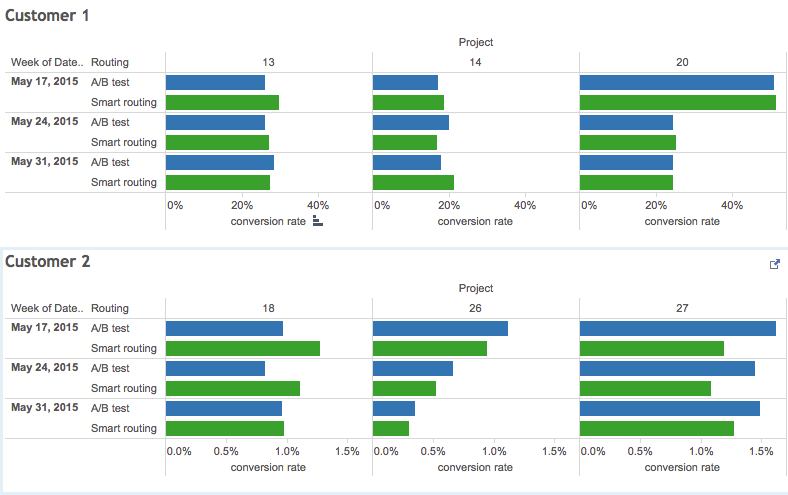
これとは別に、分類子の品質(ROC AUC / log_loss)と変換の間に相関関係が見られなかったことに注意してください。これにより、状況を改善する試みが非常に複雑になりました。
火星に生命はありますか?
より関連性のある質問は、この技術が具体的な利益をもたらすことができ、統計エラーの寸前で変動しないかどうかです。 この仮説を確認または反論することはできませんが、機械学習を用いたこのようなアプローチは、ユーザーを引き付けるチェーン全体で作業する際に役立つと思われます。
おそらく、さまざまなランディングページを作成する場合(類似したページでシステムをテストしました)、より多くのデータソース(広告ネットワークマクロ、CRMクライアント、さらにはDMP)を統合します。効果を与える。 しかし、思慮深い作業をせずに、誰でも青から既存のページを+ N%変換できるように特効薬を作ることは、かなり非現実的です。
一部のscikit-learn分類器(特に決定木に基づく)には、興味深い属性feature_importances_があり、これは最終予測の特定の属性の重みを示します。 私のテスト分類子は、選択したランディングページに2%を超える重みを割り当てることはめったになく、5%のしきい値を超えたことはありません。 同時に、国、リファラー、ブラウザなどのパラメーターは20〜25%を奪う可能性があります。 私はそれをこのように解釈する傾向があります:良い着陸の重要性はいくぶん誇張されており、広告キャンペーンでのターゲティングとの連携がより良いかもしれません。
とはいえ、読者の中に私のプロジェクトで私の開発を試してみたい読者がいるなら、書いてください。私はもう少し共同実験を行ってうれしいです。 このテストでは、トランザクションページ用のいくつかのオプションと十分な数のユーザー(1万人から)が必要です。
論理的な結論に到達するために、そのようなプロジェクトの関連性についてコミュニティの意見を知りたいので、これに関する創造的な休暇を終了し、通常の仕事に戻るつもりです。