この記事では、アルゴリズムによるテキスト生成方法と、それらを使用した経験について説明します。
大量に簡単に作成できるテキストのようなゴミではなく、意味のある有用なテキストを生成することが重要であることをすぐに明確にします。 多くの場合、このタスクを自動的に解決することはできないという意見が表明されていますが、実際にはこの考えはすでに時代遅れです。
タスクとして、レビューに基づく製品説明の自動生成を検討してください。 つまり さまざまなサイトから受け取った製品の複数のユーザーレビューを使用して、レビューからの情報を要約した小さな一意のテキストを自動的に作成します。 このタスクは、たとえば製品の特性に基づいてテキストを生成するよりも複雑です。これは、まずレビューから情報を抽出してから、それに基づいて新しいテキストを作成する必要があるためです。
電話レビューを使用するとします。 どのような情報を抽出できますか? 表面的なレベルでは、 テキスト分類子を使用してレビューがポジティブかネガティブかを判断し、電話の言及された側面のリストを抽出できます。 たとえば、最も便利な方法は、「便利」、「画面」、「バッテリー」、「音量」などの単語の出現の辞書を分析することです。側面とその評価を強調するより正確な方法は、 情報を抽出する訓練されたシステムに基づくことができますテキスト
したがって、{便利:+、ボリューム-、画面+ ...}の形式のデータを取得できます。 それほど多くの情報はありませんが、初心者には役立ちます。 次に、テキストを作成する必要があります。 これがどのように行われるかを見てみましょう。
テンプレート 最初に頭に浮かぶのは、テンプレートを使用することです。 つまり 「この電話は非常に便利です」、「ボリュームは良い」などの事前のオファーを準備します。その後、標識のリストを調べて適切なオファーを挿入します。 この例では、次のようになります。
この電話はとても便利です。 ボリュームが悪い。 画面はかなり良いです。
テキストは比較的意味があり、多少読みやすくなっていますが、オプションの種類が少ないため、すぐに一意でなくなります。 これは検索エンジンにとっては悪いことであり、読者は時間の経過とともに悩まされるでしょう。
正式な文法。 この一連のルールを想像してください。
$便利←$電話$ conv
$電話←$この$電話番号
$ conv←$ mod $ conv-ex
$ mod←とても
$ mod←十分
$ mod←
$ phone-ex←電話
$ phone-ex←デバイス
$ this←これ
$この←
$ conv-ex←便利な$使用
$ conv-ex←便利
$ use←使用する
$使用←
一番上のルールから始めて、右側の文字の値を代入します: $便利=> $ phone $ conv => $ this $ phone-ex $ mod $ conv-ex =>このデバイスは非常に便利です
次の置換の規則をランダムに選択すると、異なる文が得られます。 たとえば、同じルールセットを生成できます。 電話は非常に便利で 、 このデバイスは非常に使いやすいです。
この一連のルールは、文のさまざまなオプションを記述し、大幅に大きな変動性を提供します。 特定の勤勉さで、さまざまな非常に読みやすいテキストを生成できるルールを作成できます。
例として、このようにして生成された電話の説明をreviewdot.ruから提供します。
295件のレビューを調査しました。 そのような量が分析を得るのに十分であると信じる理由があります。 大多数の人々はこの携帯電話にかなり興味を持っていますが、あまり良くない意見もあります。
利点:レビューを残すユーザーは、原則として、利点と十分な使いやすさを指定します。 これに加えて、レビューがバッテリー、ボリューム、サウンド、カメラ、キーボード、ケース、プラスチック、強度、スクリーンの品質に一般的に満足していることが判明したユーザー。
弱点:信頼性は一般に弱点と呼ばれます。
この方法の欠点は、語彙が限られていることと、かなり面倒です(ルールの作成には時間と労力がかかります)。
英語の場合、多くの既製の言語生成パッケージがあり、ルールベースの提案計画システムと独自の生成も含まれています。 たとえば、 SimpleNLG 、そして単純なものから非常に高度なものまで、 さまざまなものがあります。 ロシア語の状況はやや悪いですが、これまで見てきたように、正式な文法で簡単な言語ジェネレーターを書くことは比較的難しくなく、非常に多くのことができます。
ニューラルネットワーク 。 最新の開発は、テキスト生成ニューラルネットワークです。 それに関する記事は、Dialogue 2015カンファレンスの資料で最近公開されました( 英語の記事はこちらから入手できます )。 このシステムは、例を使用して新しいテキストを生成することを学習します。
その動作の原理は、 チャットボットに関する記事ですでに説明したものと似ています。 違いは、文の現在の単語とこの文に含まれるアスペクトのセットに関する情報を同時に受信するニューロンの追加層があることです。 したがって、アスペクトのリストはベクトルによってエンコードされます。各次元は1つのアスペクトに対応し、この次元の値(1または0)は、この文のこのアスペクトの有無をエンコードします。 ニューラルネットワークのタスクは、現在の単語とアスペクトのベクトルを知って、次の単語を予測することです。 以下は、署名をロシア語に翻訳した、記事の図です。
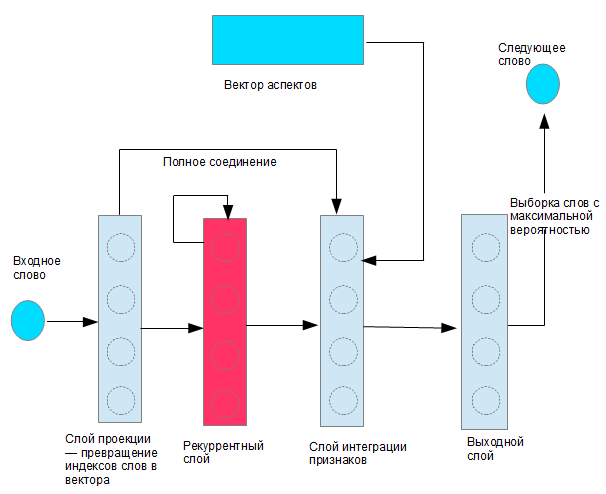
トレーニング済みのニューラルネットワークは、アスペクトの入力リストを受け取ると、新しいオファーを生成できます。 以下は、結果として生じるテキストの例です。
便利なプレーヤー、バッテリー。 快適な音、金属ケース。 小さい価格で使いやすい。 スクリーン、2 SIMカード、2バッテリー。
大きな重量、大画面、魅力的で優れたカメラ。 デザインは座って+優れたスーパーカメラで、ほとんどすべてのゲームが大きくなります(RAMを要求する人もいます)。
バッテリー、美しいスピード。 デザイン、サウンド、機能、多くの異なる日で十分です。 彼は美しい、ボリュームバック、プロセッサ、応答性センサーです。 美しい画面、色再現。 設計、バッテリー、ブレーキをかけない、実用的。
高品質で使いやすいインターフェイスを構築します。 ゴージャスなamoledディスプレイ、ボタン、カメラ、およびすべてのゲーム。 デザイン、高速インターネット、ネットをうまくキャッチします。 明るいサイズで、心地よく重いので、手にフィットします。 美しい画面、速度、インターネット、Java。 豊富なバッテリー、高速機能、信頼性。 強い、親愛なるパーセント、優れたサウンド、速いパーセント
フラッシュドライブ、Javaアプリケーション、レンガではないカードリーダー、非常に小型で、スピーカーにはバグがありません。 ケースは高品質、特に大きなボタン、優れた機器です。
主なマイナスは、いくつかの不格好なテキスト、文法的および意味的なエラーです。 さらに、多様性、より自然な感覚、ルールを手動で開発する必要はありません。 アプリケーションとして、多くのテキストを生成し、曲がった場所を手動で修正できます-特に実際のレビューの分析に基づいてテキストを書く予定の場合は、ゼロから手動で書くよりもはるかに高速です。
そしてもちろん、このモデルはレビューの対象分野に限定されるものではありません-原則としてどのテキストでも訓練することができます。
結論として、私はピエール・ブルの素晴らしい物語「完璧なロボット」、1953年の小さな断片を引用したいと思います:
「名詞「ラム」が選択されると、ロボットはこの単語を文法的に適切な形容詞と組み合わせることができます。言い換えると、「液体ラム」、「フォグラム」、「ホワイトラム」などのフレーズから正しいものを選択します。 「放射羊」や「白い羊」などの文法上の性別と数字。
「液体ラム」は意味のないフレーズです。「中断された教授精神の矛盾。
-終わりましょう! 期限内のすべて... ...次の段階で特定の複雑さを予見することはありません:構文の規則に従った完全なフレーズの形成。 これらのルールは正確に定義されているため、マシンは人間の脳と同じように、さらにはより良い方法でそれらを受け入れることができます。 そのため、「尖った空を飛ぶ液体のラム」や「白いラムが草を食べる」など、一定数の文法的に正しいフレーズの形成を達成します...
「それがあなたを捕まえた場所です!」 -矛盾の精神が喜びました。 -あなたが言うように、あなたのフレーズのほとんどは、文法的に正しいのですが、意味がありません!
彼らはフォームの面で完璧になります...」
「レンガではなく、非常に小型のカードリーダー」のようなフレーズは、常に「尖った空を飛ぶ液体のラム」を思い起こさせますが、一般的に、半世紀後にテキストを自動的に作成するタスクはファンタジーの領域から実用的な分野に移ったと言えます。