「仮想化」の典型的な問題は、サービスの所有者、顧客、またはユーザーが、仮想マシンが「減速」していると不満を言うことです。 仮想化には、1セットのハードウェアリソースに基づいて多数のVMを統合する必要があるため、オーバーサブスクリプション(オーバープロビジョニング-サーバーが同時に最大リソースを要求しないと仮定した場合、たとえば、40 GBの物理メモリで4台の10台のサーバーではなくGBのRAM、およびDynamic Memoryを使用した15)、さらに、何を最初に取得するかを決定する必要があるたびに、ソフトウェアコンポーネントとその設定のエラーによりサーバーの速度が低下する可能性があります。 特に、「車が遅くなる」などの問題の説明が大量にある場合、よくあるように、診断情報は提供されません。 猫の下でこの機会に小さなガイド。
もちろん、それはすべて特定のインフラストラクチャの特定の実装に依存しますが、実際には、ほとんどの場合、VMサブシステムの次の一連の分析が理にかなっています。
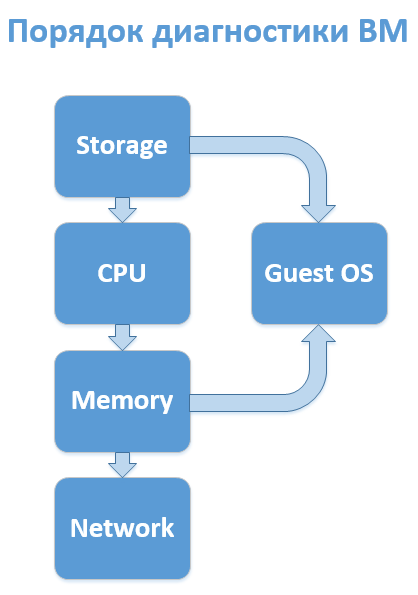
- ディスク。
- プロセッサー
- RAM
- ネットワーク
実際には、4番目のステージに到達することはほとんどなく、3番目の(または最初の後で)ゲストOSの並列診断を実行(または要求)することは理にかなっていますが、ディスクはすぐにチェックする必要があります-パフォーマンスの不満の最も重要な部分それら。 もちろん、オールフラッシュアレイがない限り。
そして、各項目についてもう少し詳しく説明します。
1.ディスク(ストレージサブシステム)
ここで重要な指標はレイテンシです。 応答時間の遅延。 多数の中間要素で構成され、多数の要因に依存します。 これには、ハイパーバイザーの応答時間、信号がケーブルおよび中間デバイス(スイッチ、アダプター、コントローラー)を通過するのにかかる時間、負荷が通常を超えた場合にこれらすべてのデバイスのキューで費やされる時間、および機器の損傷などのその他の微妙な違いが含まれます。 ただし、まれに必要な高度な診断の微妙な違いを残して、単純な一般的な指標、つまりVMからディスクまでの遅延時間を選び出すことができます。
診断ツール:
パフォーマンスタブ
(vSphere Clientの[パフォーマンス]タブとパフォーマンスカウンター)。
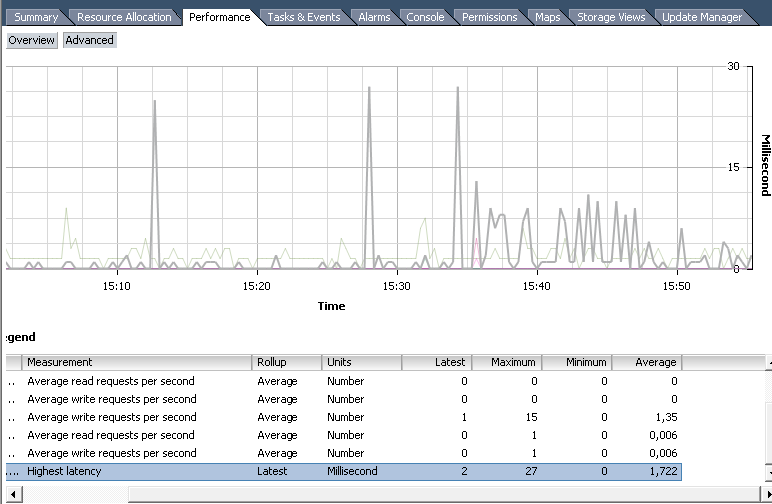
Diskグループの最も一般的に使用されるカウンター:
最高のレイテンシー -標準は10〜15ミリ秒です。 定期的に高くなる場合は、何かを変更する必要がありますが、一時的なピークは怖くありません。
1秒あたりの平均書き込み要求 。
1秒あたりの平均読み取り要求 。
仮想ディスクグループの最も一般的に使用されるカウンター:
読み取り/書き込み遅延 ;
未処理の読み取り/書き込みリクエストの平均数 -同時IOリクエストの数(それらの数がデータストアまたはサーバーごとに合計で30を超えて保持される場合、これは追加の遅延につながります);
ESXTop
コンソールユーティリティESX / ESXi。 単一のESXiに関する診断情報全体を提供します。 基本的な使用情報は、ユーティリティの起動後にhを押すと取得できます。

ディスクサブシステムの診断に関しては、仮想ディスクのコンテキスト(vキーを押す)とHBAアダプターのコンテキスト(dキーを押す)が役立ちます。 後者の場合、次のインジケータに注意する必要があります。
KAVG (カーネルレイテンシ平均)-ハイパーバイザーの応答時間(通常-最大1ミリ秒);
DAVG (デバイスレイテンシ平均)-HBAからディスクへの応答時間(通常-10-15ms);
GAVG (ゲストレイテンシ平均)-ゲストシステムの応答時間= KAVGとDAVGの合計
ところで、同じ研究分野では、VMにスナップショットがあるかどうかをすぐに確認する価値があります。 そしてほんの少し。 これらは、パフォーマンスの低下だけでなく、バックアップ、クローニング、および移行の障害の問題になる可能性があります。
2.プロセッサ
ここで、ディスクレイテンシに重要性が似ているインジケータはCPU Readyです。 また、Used、Wait、およびCo-Stopに注意する価値があります。 PerfomanceタブまたはESXtopを使用して監視することもできます。
CPU準備完了(%RDY)-VMが何らかの計算を実行する準備ができているが、現在物理プロセッサが他のプロセス(システムまたは他のVM)によって占有されており、仮想マシンのvCPUがスタンバイモードになっている時間の割合 ノルムは最大10%の値です。 この指標の成長が40%を超えると、ゲストOSの障害とフリーズの可能性が高くなります。 ダウンタイムの原因は次のとおりです。
- 多数のVMによるプロセッサリソースの集中的な消費、およびvCPUの合計数が論理コアの数を大幅に超えています(オーバーサブスクリプション)。
- オーバーサイズのVMの存在(たとえば、マシンに16コアがあり、それぞれが1-20%の電力で実行されている場合、多数の負荷が低いvCPUを持つ仮想マシン)。 ここでの問題は、多数のvCPUがある場合、ハイパーバイザースケジューラーが作業を同期する必要があるため、特定の操作に必要なvCPUの数に対応する論理コアのフル数が解放されるまで、一部のコアまたはマシン全体の定期的な「フリーズ」が発生することです。 このメカニズムはCo-Stopと呼ばれ、この場合、対応するカウンターが増加します。 これは、仮想マシンに「予約済み」の仮想プロセッサを詰め込むことに対する主な議論です(2番目の議論はNUMAですが、既に記事の範囲外です)。 20%の8コアよりも80%でロードされた2コアのほうが優れています。 ほとんどの場合。
- 仮想マシンのCPU使用率がリソースプールまたはマシン自体のレベルで制限されている場合。 特定のしきい値に達すると、マシンはプロセッサリソースを受け取らず、CPU Readyを蓄積します。 この場合、Max-Limitedカウンターの値(%ML)が増加します。
待機 (%WAIT)-VMが何らかの種類のVMkernelアクティビティの終了を待機する時間の%。 ほとんどの場合、これはディスクIOアクティビティです。 このカウンタのレートが高い場合、データストアからの応答が不十分であることを示している可能性があります。 また、この問題は、現在欠落しているISOがマウントされているUSBまたはCOMポートまたは仮想CD / DVDドライブの誤った操作が原因である可能性があります。
使用済み (%USED)-マシンが実際に動作した時間の%。 ゼロに近い場合、マシンはそのまま立っているか、プロセッサによって再構築されました。 (vCPUごとに)約100である場合、それはサイズが小さかった、または何かが周期的に入っていた(まだ同時に応答しない場合)か、または四半期レポートがバーストしていることを意味します。 「VMにより多くのプロセッサを高速で動作させるにはどうすればよいですか?」というトピックについて考える場合、この指標を検討する必要があります。 4つのコアがあり、誰も50%以上関与していない場合、8つのコアはおそらくそれを加速しません。 速度が低下することもあります(CPU Readyを参照)。
診断ツールは同じです。
パフォーマンスタブ
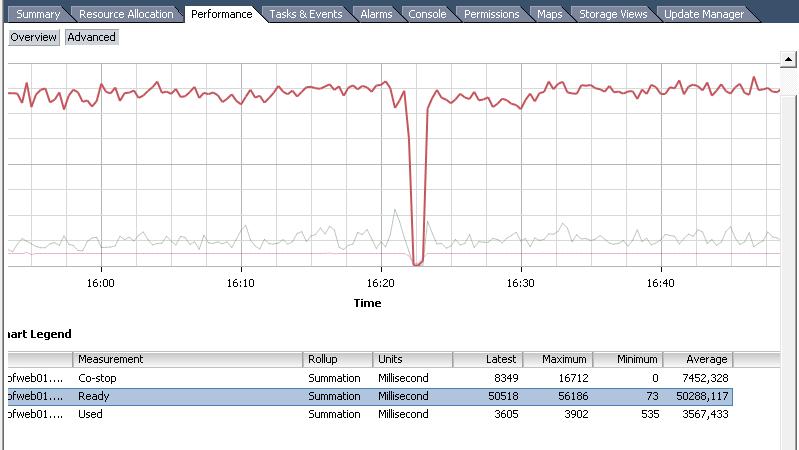
便利なことに、データはマシン全体だけでなく、各コアでも見ることができます。 さらに、期間の統計が利用可能です。 ただし、情報はパーセンテージではなくミリ秒で提供されます。 データはリアルタイムではなく一定の間隔で収集されるため、プロセッサが1つの状態または別の状態にあったmcの正確な数が表示されます。 値を間隔の長さで除算し、100%を掛けることで、パーセンテージに変換できます。
例:図では、間隔が20秒(リアルタイム)の図、つまり20000ミリ秒です。 つまり、平均CPU Readyは50288/20000 * 100%= 251.44%になります。 マシンには1つではなく4つのコアがあるため、結果を4で割ると、ほぼ63%になります。 車は非常に苦しんでいます。 そして、すべてが、それぞれのシェアが低いリソースプールのネストの第3レベルにあるためです。
もう一度、変換式: <CPUReady値> / <ミリ秒単位の統計間隔> / <vCPU番号> * 100% 。 1つのコアの場合、1000ミリ秒あたり5%になります。
ESXTop

ここでは、値はすぐに%で示されます。 すべてのコアの合計ですぐに示されるので、100を超える数値を怖がらないでください。マシンのvCPUの数で割ります。
3. RAM
ここでの基本的な診断は簡単です-はいまたはいいえ。 バルーニングの事実がある場合、ホストには十分なメモリがなく、スワップファイルがアクティブに使用されるため、ゲストOSプロセスが低下します。 ハイパーバイザーレベルでスワップファクトがある場合は、早急に対策を講じる必要があります-スワップに陥ったマシンは、100%のケースでa睡状態に陥ります(少なくとも私の場合は)。 上記の事実により、次のようなカウンターを判別できます。
バルーン (MCTLSZ)-ゲストOSからバルーンドライバーによってプルされたメモリの量。
スワップ(SWCUR)-.vswp(つまり、ハードディスク上)に配置されたメモリの量。
4.ネットワーク
ネットワークレベルで問題が発生するため、別の仮想マシンに関する苦情があった場合、私の実務では、VDIが非圧縮ビデオストリームを駆動し、すべてを100 Mb / sで詰まらせた安価なWebカメラを使用した場合を1つだけ覚えています。
このようなカウンタを監視する価値があります。
ドロップされたパケットの送信 (%DRPTX)- 送信されたドロップされたパケットの数(またはesxtopの場合は割合)。
受信ドロップパケット (%DRPRX)-破棄された受信パケットの数(割合)。
定期的に発生するゼロ以外の値は、ネットワークデバイスの不正な動作または不正な構成を示します。
通話の半分以上(おそらく最大90%)をカバーする基本的な診断、または診断とテストの独自のニーズについては、これで十分です。