すべてではなく特定の商品名が必要な場合はどうなりますか? または、モバイルアプリケーションのコマンドを解釈する必要がありますか? 住所を通り、家、市の名前に分けますか? サポートサービスへの顧客の訴えから重要な事実を強調してみてください。「あなたの会社のサービスの質にserviceしています。 少し前にラップトップを注文しましたが、 マネージャーは正しく話せず 、 商品が終わったと言いました 。 今日は、テキストから情報を抽出する幅広い問題を解決できる新しいサービスについてお話します。 このサービスを公開しました。
この記事の例が機能するために必要なもの :この記事では、主にC#の.NET Frameworkのソリューションについて説明します。 .NET Frameworkまたはモノラル用の任意の言語も適しています。 他の言語からWeb-APIを使用することもできますが、既製のライブラリはまだないため、リクエストコードを手動で記述する必要があります。 これは難しいことではありませんが、ここでは主要なアイデアを失わないためにこれを行う方法について詳しく説明しません。 また、インターネットアクセスと開いているポート8080も必要です。無料のキーを取得するには、登録する必要もあります。 基本的にすべてのようです。
この記事の構成方法:最初に、APIの操作を示す例について説明します。 以下はコードです。 次に、システムが内部からどのように機能するかについて少し理論を説明し、最終的には現在のバージョンの制限について、そしてどのような場合にこのシステムが役立つか、そうでない場合について伝えます。
タスクを分析します 。例として、テキストから商品の名前を抽出するタスクを取ります。 つまり 「 キヤノンI-SENSIS i6500レーザープリンターをオフィス用品店で購入します。」 インターネット上の商品や価格に関する情報、またはページのコンテンツに基づいて商品リスト広告を表示するシステムを分析するために、商品の言及を見つけることが必要な場合があります。 まあ、他のさまざまな目的のために。
このタスクは単純で、解決するための費用はかかりません。 たとえば、一部の製品グループ、特に英語の名前の場合、テキストから製品の名前を強調する正規表現を書くことができます。 しかし、このような方法では、たとえば、「Buy HTC One」(電話モデル)と「Samsung Apple Nokia Phone」(メーカーの単なるリスト)を区別することはできません。 「Atlant 500冷蔵庫が販売されている」など、ロシア語で呼ばれる商品が必要な場合、正規表現はまったく役に立ちません。名前の始まりは完全にはわかりません。
したがって、いくつかの例に基づいて、製品の名前を他のテキストと区別するようにコンピューターに教えようとします。 このアプローチの主な利点は、自分でアルゴリズムを作成する必要がないことですが、マイナスはトレーニング用の例を手動で作成する必要があることです。
例はどのように見えるべきですか? このようなオファーがあるとしましょう:「ストアでSamsung Galaxy S4を購入する」「電話」。 これを個別の単語に分割し、列の形式で表示します。 次に、製品名の反対側に、「製品」という単語を書きます。
| 購入する | |
| サムスン | 製品 |
| 銀河 | 製品 |
| S4 | 製品 |
| で | |
| 私たちの | |
| 店 | |
| <停止> | |
| また | |
| ... |
したがって、単語を製品の名前の一部であるかどうかを判断するというタスクを策定しました。 例を使ってトレーニングした後、左列の形式でテキストをモデルの入力に送信し、出力で右列を取得するだけです。 すべてが十分にシンプルに思えます。
実際には、主な問題は、トレーニング用の十分な数の例を手動でマークアウトすることです。 例が多いほど、モデルの動作は良くなります。 論理的な質問は、「非常に多くの」例がいくつあるかということです。 それはすべてタスクに依存します-タスクが複雑になるほど、より多くのデータが必要になります。 一般に、通常、400〜4000の目的の要素の出現例が必要です。 費やした時間に関しては、私たちの経験では、実例の注釈を作成するための3日間の作業は、場合によっては実行可能なプロトタイプを作成するのに十分ですが、より複雑な状況ではこの時間が大幅に増加します。
この記事のために、 ここで既にラベル付けされたトレーニングセットを用意しました 。 この場合のトレーニングセットはWebページのヘッダーから作成されるため、結果のモデルはヘッダーで適切に機能します。 後で、他のテキストの認識品質を改善する方法を説明しますが、ここでは主なアイデアに焦点を当てましょう。
データセット全体を2つの部分に分割する必要があります-トレーニング-この部分でモデルをトレーニングし、テスト-この部分でアルゴリズムの結果を確認します(トレーニングセットには既に2つのファイルがあります)。 両方のファイルが含まれており、メモ帳または別のテキストエディターでそれらを開いて構造を表示できます。
次に、を登録する必要があります 。これにより、無料のAPIキーを取得し、 関数のライブラリをダウンロードできます (一部のブラウザでは、アーカイブにdllライブラリが含まれているため、確認を求められる場合があります)。 C#の場合、コンソールアプリケーションを作成し、プロジェクトMeanotek.NeuText.Cloud.dllに接続する必要があります。
今、私たちはプログラムを書いています。 最初に、新しいモデルを作成し、名前を付けます。 名前はすべてのモデル間で一意である必要があります。これにより、モデルはその後識別され、ラテン文字と数字のみが含まれるからです。
using Meanotek.NeuText.Cloud; Model MyModel = new Model(" api ","ProductTitles"); MyModel.CreateModel();
次に、データをロードし、モデルをタスクキューに配置します。
System.Console.WriteLine(" "); MyModel.UploadTrainData("products_train.txt"); System.Console.WriteLine(" "); MyModel.UploadTestData ("products_dev.txt"); System.Console.WriteLine(" "); MyModel.TrainModel();
TrainModel()は、トレーニングが終了するまでプログラムを一時停止します。 通常、これは必要ありません(10〜20分かかるため)。プログラムはこの時点で他のことを行い、学習プロセスのステータスを確認するだけです。 プログラムを停止しないようにするには、 TrainModelAsync()メソッドを使用できます。 TrainModel()の操作中にプログラムが閉じられた場合、またはネットワーク接続エラーが発生した場合、プログラム自体はモデルをキューに入れ、この時点で待機するだけなので、サーバー上にモデルが作成されます。 次回プログラムを起動するときに、 Model.GetStatus()関数によってモデルの状態を確認できます。
トレーニングが完了したら、テスト選択テストの結果を表示できます。
Console.WriteLine(MyModel.GetValidationResults());
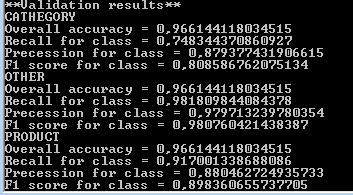
抽出された式の種類(カテゴリ、製品)ごとに、システムの品質を特徴付ける一連の値が計算されます。 想起とは、人が見つけた表現の総数に対する、アルゴリズムが見つけた表現(製品名など)の数の比率です。 歳差-検出されたすべての中で正しく検出された式の割合。 F1は、歳差運動と想起を組み合わせたアルゴリズムの品質の集合的な基準です。 この値が1.0に近いほど優れています。 これらすべての測定基準の意味について詳しく説明するつもりはありませんが、興味のある読者にはこの記事を読むことをお勧めします。
比較のために、単語とバイグラムの形式の属性を5ワードウィンドウで広く使用する条件付きランダムフィールドメソッドは、このサンプルで製品名に86.2、カテゴリに79.5のF1を与えることに注意してください。
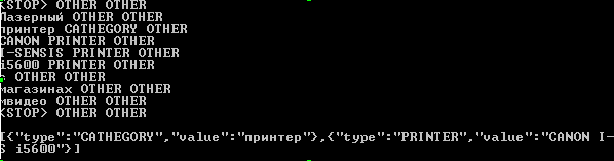
次に、新しい例を入力してみましょう。
string result_raw = MyModel.GetPredictionsRaw (" CANON I-SENSIS i5600 "); string result = MyModel.GetPredictionsJson (" CANON I-SENSIS i5600 "); Console.WriteLine(result_raw); Console.WriteLine(result);
理論(および哲学):テキストからさまざまな表現を抽出する問題には長い歴史があり、それを解決するための多くの特別なツールがあります。 しかし、私たちは、深刻な特別なスキルを必要とせず、手動で構成せずに、比較的小さなサンプルで作業し、同時に幅広いタスクに適した、非常に使いやすいソリューションを作りたいと考えました。 その後、テキストからデータを抽出するための新しいモデルの作成、およびその結果、新しいアプリケーションは、ビジネスに必要な分析ツールを自分で決定できる個々の開発者や中小企業が利用できるようになります。
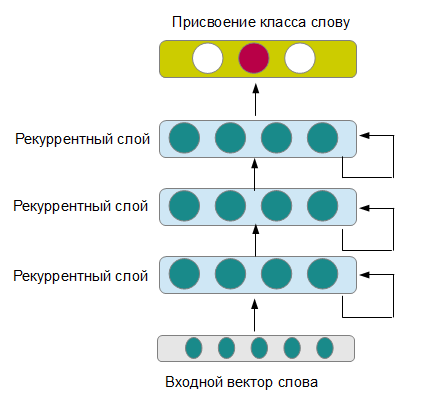
これを行うには、品質の低下をあまり伴わずに、特定のタスク用に選択された記号、文法アナライザー、および用語のあらゆる種類の辞書の手動選択をまず取り除く必要がありました。 これを可能にするモデルの1つは、ディープリカレントニューラルネットワークです(図を参照)。 リカレントネットワークは、以前の状態のメモリを保持しながら、入力として文から新しい単語を順次受信します。 出力で、ニューラルネットワークは、指定された単語が属するクラスを発行します。 いくつかの連続したレイヤーは、文のますます抽象的な理解を形成し、異なる時間範囲で動作します(ただし、これはすべてが正しく設定されている場合に発生します。そうでない場合は、高度に再訓練されたニューラルネットワークを取得できます)。
研究から、このようなモデルは、セマンティックロールのマークアップや調性の分析など、英語のテキストから複雑な表現を抽出できることがわかっています。 さらに、結果は劣らず、多くの場合、他のすべての既知の方法の指標を上回っています。 確かに、各作品は独自のわずかに異なるアーキテクチャを使用し、最適なパラメーターはタスクごとに異なっていました。
したがって、私たちは多くの作業を行い、英語とロシア語のテキストの18のテストコレクションで数十の異なるモデルをチェックしました。その結果、さまざまなタスクで結果が高くなるように、最適なニューラルネットワークモデルと入力語の表現方法を見つけることができました。
確かに、最終的に、APIに選択されたモデルは速度と精度の妥協点になりますが、その結果は依然として非常に優れていますが、最善ではありません。 ただし、必要に応じて、より遅いモデルを接続することにより、個々のタスクの結果を改善できます。
有用な場合、実装の可能性と制限: APIがあなたに利益をもたらす場合、期待できる結果、価値のないものを示す小さなタブレットを用意しました。
| いつ役に立つか
| いつ役に立たない |
| テキストを理解するためのツールを使用してアプリケーションを作成したいが、言語アナライザーの理論に精通していないか、経験がほとんどない場合 。 手動で調整することなく、システムに競合モデルを作成させようとしました。
| あなたはコンピューター言語学の専門家であり、5年間取り組んできた問題の解決の質を向上させたいと思っています 。 現在の実装がすべての特殊なソリューションを上回ることを保証するものではありません。
|
| 既製のAPIがないテキストから情報を抽出するという特定のタスクを解決します(つまり、人、組織、日付、地理的な場所の名前を見つけるのは簡単ではありません) 。 私たちのシステムはさまざまなタスクのために訓練することができます。
| 名前付きエンティティを認識するための既製のAPIなど、タスク用の特別なソリューションが既にあります 。 ほとんどの場合、ニーズが完全に満たされていることが確実であれば、ターンキーソリューションを使用する方が簡単です。
|
| 予算と利用可能なリソースが限られているため、独自の言語アナライザーのサポートと開発を継続したくありません。 私たちは新しい研究に従って最新のアルゴリズムを実装しているため、時間が経つにつれて、APIで設計されたシステムの品質は追加費用なしで向上します
| 独自の専門家チームがあり、常に言語アナライザーをサポートおよび開発しています。
|
| エンドアプリケーションのディスク領域またはコンピューティングリソースを節約したい。 ターゲットデバイス上で5〜100 mbのスペースを節約できます。これは、モバイルアプリケーションにとって重要です。 エントリーレベルのVPSまたは共有ホスティングにあるWebアプリケーションに分析機能を簡単にインストールできます。
| メモリとプロセッサのリソースは無制限に利用できます。
|
最後に、無料のAPIキーの制限について。 この記事の執筆時点では、制限はトレーニングサンプルのサイズ(クラスラベルを除くテキストの最大24万文字)、同時に動作するさまざまなモデルの数(最大2個)、およびリクエストの数(1日あたり4万2千文字)に関連しています。 これは、ほとんどのアプリケーションの開発、テスト、個人使用、およびあまり忙しくないシステムのライブ作業に十分なはずです。