たとえば、検索結果はユーザーごとに異なります。 また、ドキュメント自体のデータのみに基づく並べ替え(TF / IDFまたはドキュメントの任意のフィールドによる並べ替え)では、目的の結果が得られません。 同時に、オンラインストアの検索結果で、ユーザーが既に最初の位置で見た製品を表示します。
別の例。 ソートの変更に頻繁に影響するパラメーター:ElasticsearchはLuceneに基づいて構築され、追加専用のストレージを使用します。ドキュメントの更新は事実上ありません。 ドキュメントが変更されるたびにインデックスが再作成され、ストレージセグメントの定期的な再構築が必要になります。 つまり、出力をサイト上のドキュメントビューの数で並べ替える場合、できることは、Elasticsearchで各ビューを記録することです。 そして、ここでは、ドキュメントのソートに使用されるメタ情報の外部リポジトリを使用する問題が成熟しているようです。

プロジェクトの1つでは、Elasticsearchをメインリポジトリとして使用します。 これにより、不必要なジェスチャなしで数千万のドキュメントにシステムを拡張し、同時に数千ミリ秒で測定された応答を維持できます。 プロジェクトの基本はドキュメントです(ウェブサイトページ、公開投稿、GIFまたはYoutubeビデオ。各ドキュメントは解析されたコンテンツを含むページです。ドキュメントにはメタ情報があります。元のURL、タグなど。インタレストフィード(1つのフィード内の複数のサイト)を作成し、Googleアラート機能も使用します。この機能内で、任意のフレーズのフィードを作成できます。
この問題は、アプリケーションに人気のあるドキュメントを投票および並べ替えることを決定したときに始まりました。 前述したように、頻繁に変更されるデータをESに書き込むべきではありません。
挑戦する
投票データはRedisに保存されます。 これは非常に高速なストレージであり、この種のタスクに最適です。 Redisに保存されているデータ(ユーザーの投票、ドキュメントビューの数)に従って、Elasticsearchに保存されているドキュメント(オンデマンドの選択)を並べ替える必要があります。
FUNCTION_SCORE_QUERYソリューション
バージョン0.90.4以降、ElasticsearchはFunction Score Query (FSQ) メカニズムを提供します 。 これはかなり柔軟なソリューションです。 一般に、 FSQを使用すると、出力のソートに使用されるドキュメントの重みを「手動で」計算できます 。
FSQでできることは十分です。
- 入力から選択から次のドキュメントを受け取るコールバック(java)をインストールします。
- 入力に渡されるドキュメントに、コールバックで計算された結果に等しい重み(フィールド_score)を割り当てます。
コールバックをインストールするには、Elasticsearchプラグインを作成する必要があることに注意してください。 ここでは、メインアイデアを理解しやすくするための単純化されたプラグインコードを提供します。
public class AbacusPlugin extends AbstractPlugin { @Override public String name() { return "myScore.plugin"; } @Override public String description() { return "My Score Plugin"; } // called by Elasticsearch in a initialization phase(reflection magic) public void onModule(ScriptModule module) { module.registerScript( "myScore", // NOTE: script name MyScriptFactory.class ); } /* * Script Factory should implement NativeScriptFactory */ public static class MyScriptFactory implements NativeScriptFactory { // Some Score Calculation Service private final MyScoreService service; public MyScriptFactory() { service = new MyScoreService(); } @Override public ExecutableScript newScript( @Nullable Map<String, Object> params // script params ) { return new AbstractDoubleSearchScript() { /* * called for every filtered document */ @Override public double runAsDouble() { // extract document ID final String id = docFieldStrings("_uid").getValue(); // extract some other document`s field final String field = docFieldStrings("someField").getValue(); // calc score by ID and some other field return service.calcScore(id, field); } }; } } }
このプラグインは何をしますか?
- onModule関数にソートスクリプトを登録します。
- NativeScriptFactoryインターフェースを実装するMyScriptFactoryクラスにスクリプトファクトリを実装します。
- 抽象クラスAbstractDoubleSearchScriptから継承して、ソートクラス自体を作成します。
- ソートクラスはrunAsDouble関数を実装します(返される計算されたスコアは2倍になると想定されます)。
- runAsDouble関数は 、クエリ選択に該当する各ドキュメントに対して呼び出されます。 文書のコンテンツへのアクセスは、抽象クラスAbstractDoubleSearchScript.docFieldStringsの関数によって提供されます。
- プラグインコードには、サービスMyScoreService()も表示されます。これは、実際には、新しいスコアドキュメントの割り当てを担当します。 このサービスは、投票数を求めてRedisに送られます。 あなたの場合、それはどこに行く他のサービスでも構いません。
ソリューションを説明する図:
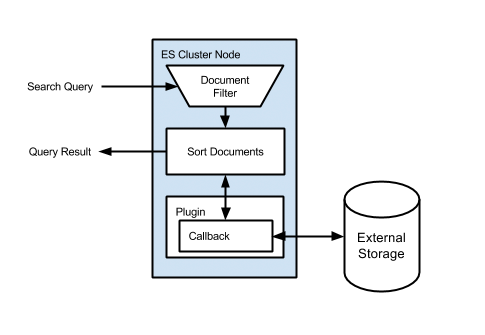
ご覧のとおり、標準のElastiSearchクエリが最初に実行され、次に各ドキュメントに対してカスタムスコアスクリプトが実行されます。 クエリは次のようになります。
{ "function_score": { "boost_mode": "replace", // to ignore score "query": ..., // some query "script_score": { "lang": "native", "script": "myScore" // script name "params": { // script params(optional) "param1": 3.14, "param2": "foo" }, }, } }
問題
すべてが非常に単純なようです。 要求はESノードの1つに到達し、シャードと他のノードに送信されました。 各シャードはクエリをカウントして実行し、Redisで追加データを求めて実行し、結果をイニシエーターに返しました。 しかし、落とし穴があります。 「各ドキュメントに対してカスタムスコアスクリプトが実行される」ことに注意してみましょう。 これはどういう意味ですか? たとえば、Elasticsearchのクエリで100万件のドキュメントが見つかりました。 その後、そのようなドキュメントごとに、Redisに移動し、そこから投票数を取得する必要があります。 1ミリ秒でなんとか回っても、 16分かかります。 実際、要求は複数のシャードと並行して行われたため、実際にはそれほどではありませんが、それでもその数字は印象的です。
問題解決
いずれの場合も、この問題の解決策は独自のものになります。 たとえば、特定のユーザーのカスタムソートと表示について話している場合、ユーザーに関するすべてのメタ情報を受け取ると、次のドキュメントごとに既にメモリからローカルに取得します。 これは非常に高速に動作します。
ただし、この場合、各ドキュメントには独自のメタ情報(投票数)があります。 これは、ホットデータとコールドデータを投稿するときにアプローチが機能する場所です。 ホットデータはRedisに保存され、コールドデータはESにダンプされます。 仕組みは次のとおりです。公開日から3日後、記事は実質的に投票の受け取りを停止します。記事はESにダンプされ、累積投票の値でドキュメントのインデックスを再作成できます。 また、最新の記事では、Redisからの声を取り上げています。
さらに、古いドキュメントがまだ新しい票を受け取っている場合、それらは失われませんが、キャッシュに蓄積され、定期的にESのインデックス作成に進みます。 このスキームでは、古いドキュメントが更新されていない音声でソートされる小さな時点がありますが、それは私たちに適しています。
また、スコアを計算するためのプラグインコードを見ると、それが同期しており、1つのドキュメントで実行されていることに気付きました(redisでバッチリクエストを生成することはできません)。 ただし、スコアバッチを検討し、すべてのドキュメントではなくredisでリクエストを作成する場合、非常に複雑な手法がありますが、たとえば、1000ドキュメントのパッケージを形成します。
結論
もちろん、説明したソリューションは、MySQLへの1つのクエリで取得できるものよりもはるかに複雑です。 ただし、必要な検索機能と大規模なため、Elasticsearchをメインストレージとして使用します。その場合、このようなアプローチは正当化され、機能します。
ここでシステムの動作を確認できます:
https://play.google.com/store/apps/details?id=com.indxreader