これらのプロセッサは、Intel Xeonシリーズで最も強力であり、4つ以上のプロセッサシステム用に設計されており、約1年前にリリースされました。 第1世代のXeon E7と比較すると、パフォーマンスは2倍、内蔵キャッシュは25%増加、サポートされるRAMの最大量は3倍、I / Oチャネル帯域幅は4倍です。 さらに、Intel Itaniumプロセッサ用に開発されたクラッシュ保護テクノロジーを利用することにより、Xeon E7 v2ベースのサーバーは5-9(99.999%)の可用性を提供します。 Xeon E7プロセッサには、2つの命令ストリームをサポートし、最大37.5 MBの共有L3キャッシュと最大3つのQuickPath Interconnect(QPI)リンクを使用する最大15個のプロセッサコアが含まれています。 このプロセッサを搭載した4プロセッササーバーは最大6 TBのRAM、8プロセッササーバーは最大12 TBのRAMを搭載できます。
Xeon E7 v2プロセッサを使用してCaché2015.1のスケーラビリティを評価するために、インターシステムズは米国の主要な医療機関で使用される医療記録管理システム(EMR)であるEPICのデータベースをテストしました。 テストにより、Caché2015.1とXeon E7 v2ベースのサーバー上のエンタープライズキャッシュプロトコル(ECP)テクノロジーを組み合わせることで、1秒あたり2,100万を超えるエンドユーザーデータベースクエリを処理できることが示されました(このパフォーマンスメトリックを1秒あたりのグローバルリファレンスまたはGREFと呼びます) 。 同時に、Xeon E5と組み合わせてCaché2013.1で達成された結果は3倍以上改善されました。 EMRシステムのテストの選択は、インターシステムズの主な顧客は金融機関、小売、公共部門に加えて医療機関であるという事実によって説明されています。
以下のCaché2015.1スケーラビリティの強化により、生産性が3倍に向上しました。
- 特定のアプリケーション向けの新しい並列化アルゴリズム。これにより、負荷とユーザー数が増加しても、アプリケーションの応答時間は同じレベルのままです。
- Caché2015.1は、データへの不均一アクセス(NUMA、不均一メモリアクセス)に関連付けられたマルチコアシステムでアプリケーションを実行する際の遅延を最小限に抑える特別なコマンドを使用します。したがって、サーバーにインストールされるプロセッサの数が増加しても、アプリケーションの応答時間は増加しません。
テストはどのように行われましたか?
テストは、サンフォードヘルス病院ネットワークにサービスを提供するEPIC EMRシステムで使用される実際のマルチテラバイトデータベースのコピーを使用して実施されました。 Sanford Healthは、米国で最大の医療機関の1つであり、1,400人の医師がいる43の病院を所有し、26,000人以上の患者に治療を提供しています。
パフォーマンスのエキスパートであるインターシステムズとエピックは、サンフォードヘルスデータベースのマルチテラバイトコピーに対して一連のテストを実行し、Caché2015.1でGREFによって測定されたパフォーマンスを決定し、Caché2013.1の以前のリリースで同じデータベースのパフォーマンスもテストしました。 エンドユーザーからのデータベースクエリによって作成された負荷を生成するために、Epicによって開発された特別なモデリングツールが使用されました。 同時に、データベースにアクセスするエンドユーザーの数は徐々に増加しました。 テストでは、GREFパフォーマンスインジケーターと遅延値の両方を測定しました。 データベースが一連の複雑なクエリを処理できる速度。
 Caché2015.1をテストするには、クロック周波数2.8 GHzのIntel Xeon E7-4890 v2プロセッサを搭載した4プロセッササーバを使用し、Caché2013.1はIntel Xeon E5-2680 2.7 GHzを搭載した2ソケットサーバを使用しました。 両方のサーバーがRed Hat Enterprise LinuxとVMware vSphereを実行しました。 計算能力、RAM、およびディスクの必要なリソースを所有していたため、これらの指標はシステムのスケーラビリティを制限したり、クエリに対するデータベースの応答を遅くしたりしません。 ストレージシステムとしてソリッドステートアレイが使用されました。
Caché2015.1をテストするには、クロック周波数2.8 GHzのIntel Xeon E7-4890 v2プロセッサを搭載した4プロセッササーバを使用し、Caché2013.1はIntel Xeon E5-2680 2.7 GHzを搭載した2ソケットサーバを使用しました。 両方のサーバーがRed Hat Enterprise LinuxとVMware vSphereを実行しました。 計算能力、RAM、およびディスクの必要なリソースを所有していたため、これらの指標はシステムのスケーラビリティを制限したり、クエリに対するデータベースの応答を遅くしたりしません。 ストレージシステムとしてソリッドステートアレイが使用されました。
結果
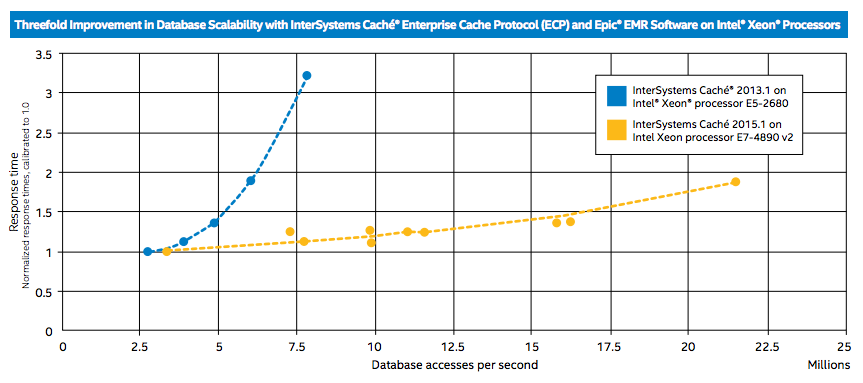
グラフからわかるように、テストでIntel Xeon E7-4890 v2を搭載したサーバー上のCaché2015.1は、Intel Xeon E5-2680を搭載したサーバー上のCaché2013.1よりも3倍高いパフォーマンスを示しました。 また、このグラフは、データベースへのクエリの数が増えると、新しいCachéリリースを使用した場合の遅延が大幅に遅くなることも示しています。 サーバーのハードウェア構成の制限のため、およびCaché2015.1自体のパフォーマンスの上限に達していないため、2,200万を超えるGREFを使用したテストは行われなかったことに注意してください。
結論
テストにより、データベース自体の並列化メカニズムの改善とIntel Xeon E7 v2プロセッサの新しいマルチコアアーキテクチャの活用の両方により、新しいCachéリリースのスケーラビリティが大幅に向上することが実証されました。
ご清聴ありがとうございました。ご質問にお答えします。