このアプリは、Intel Threading Building Blocks(Intel TBB)ライブラリの例から取られています。 マンデルブロフラクタルを描画し、Intel TBBを使用してストリームで並列化されます。 つまり マルチコアプロセッサの利点を活用します。ベクトル命令の場合を見てみましょう。
テストシステム:
•Intel Core i5-4300Uを搭載したノートブック(Haswell、2コア、4ハードウェアスレッド)
•IDE:Microsoft Visual Studio 2013
•コンパイラ:Intel Composer 2015 update 2
•Intel Advisor XE 2016ベータ
•付録:マンデルブロフラクタル、わずかに修正。 <tbb_install_dir> \ examples \ task_priorityを参照してください
1.状況を評価する
それで、最初のステップ:基本バージョン、動作時間:4.51秒を測定します。 次に、Intel Advisor XEで調査分析を開始します。
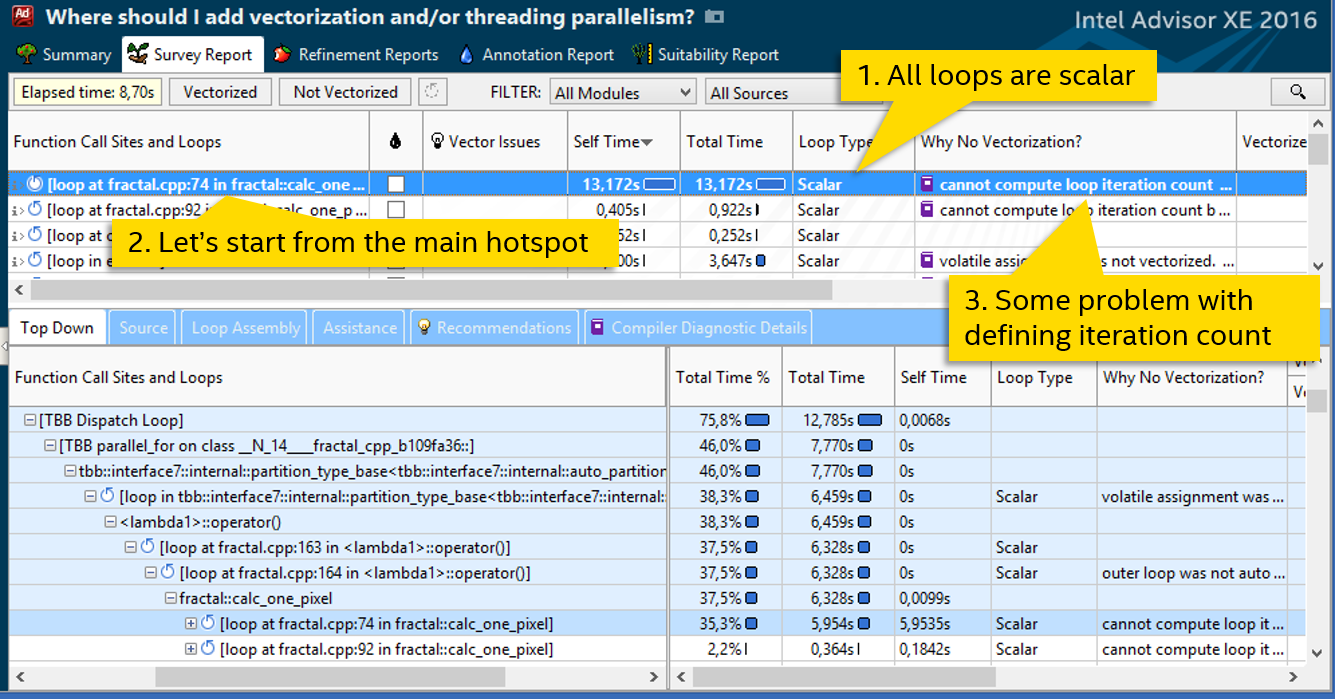
「ループタイプ」列は、すべてのサイクルがスカラーであることを示しています。 SIMD命令を使用しないでください。 fractal.cppファイルで最も高価なサイクルは74行目です。13秒以上のCPU時間を消費します-それを行います。 「ベクトル化の理由」列には、コンパイラがループの反復回数を推定できなかったため、ループをベクトル化しなかったことを示すメッセージが含まれています。 ハイライトされたループをダブルクリックして、コードを見てください:
while ( ((x*x + y*y) <= 4) && (iter < max_iterations) ) { xtemp = x*x - y*y + fx0; y = 2 * x*y + fy0; x = xtemp; iter++; }
コンパイル時に反復回数がわからない理由が明らかになります。 アルゴリズムの詳細に飛び込み、その間書き換えを試みる前に、より簡単な方法で試してみましょう。 ループの呼び出し元-トップダウンタブを見てみましょう。
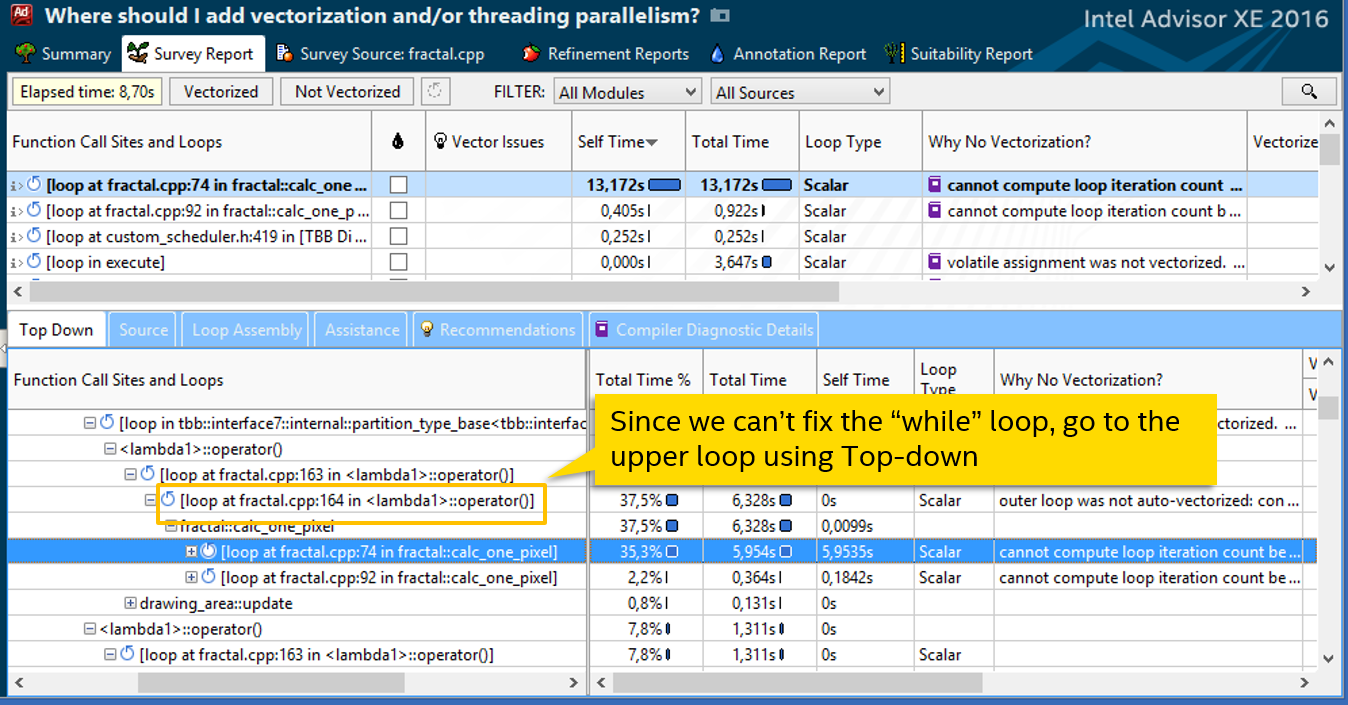
2.ベクトル化を強制します
呼び出しスタックの次のループは行164にあります。これは通常の見た目ですが、コンパイラーはベクトル化せず(ループタイプ列のスカラー)、おそらく有効ではないと考えます。 診断メッセージは、たとえばSIMDディレクティブを使用して、ベクトル化を強制しようとすることを示唆しています。
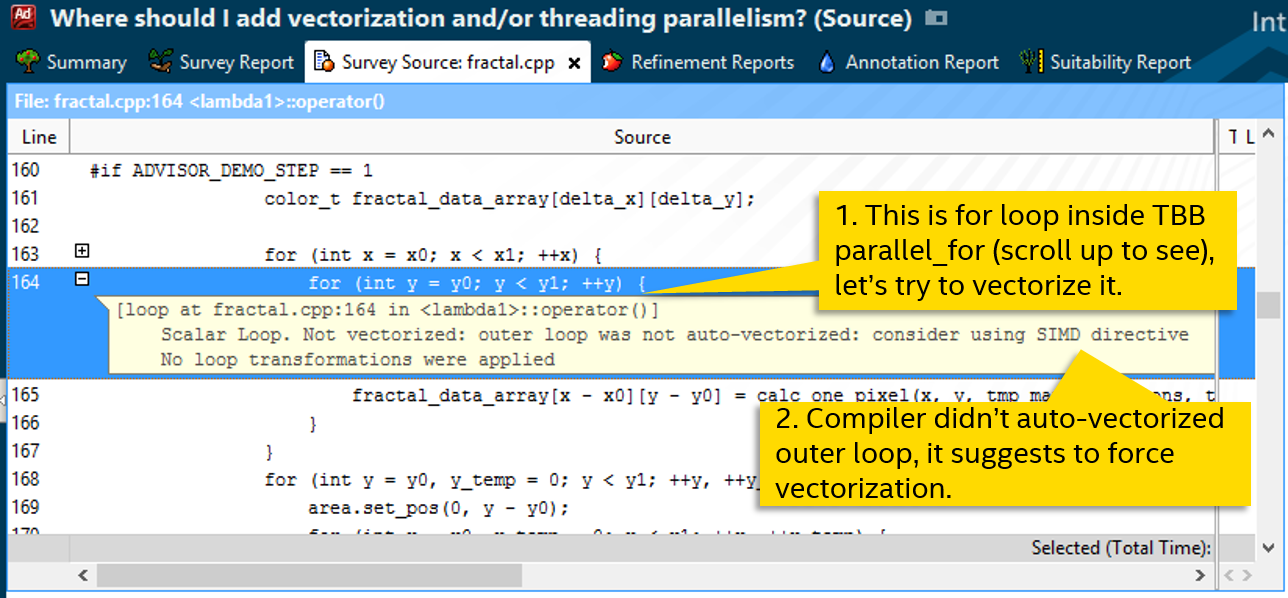
アドバイスに従ってください:
#pragma simd // forced vectorization for (int y = y0; y < y1; ++y) { fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255); }
プログラムを再構築し、調査を再度実行します。 #pragma simdを使用すると、ループは「スカラー」ではなく「剰余」になりました。

ご存知のように、SIMDサイクルはピール、ボディ、残りに分けることができます。 実際、ボディはベクトル化された部分であり、1つの命令で複数の反復が一度に実行されます。 データがベクトルの長さに揃えられていない場合、皮むきが表示されます。剰余-最後に複数の反復が残っています。
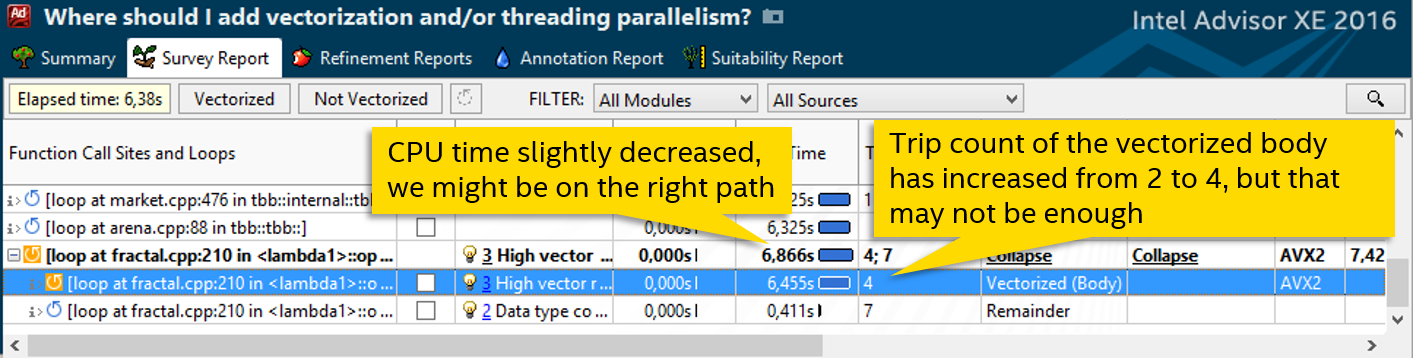
残りのみがあります。 つまり、ループはベクトル化されていますが、本体は実行されていません。 推奨事項のあるブックマークは、この状況の非効率性を示しています。ここでの残りは通常の順次ループであるため、本体でさらに反復を実行する必要があります。 Trip Counts分析を使用して、反復の数を確認してみましょう。

3.反復回数を増やす
ループには8つの反復しかありませんが、これは非常に小さいものです。 さらにある場合、ベクトル化されたボディには実行するものがあります。 コードの変更後に行番号が変更されました。現在は179行目です。反復回数がどのように決定されるかを見てみましょう。
tbb::parallel_for(tbb::blocked_range2d<int>(y0, y1, inner_grain_size, x0, x1, inner_grain_size), [&] (tbb::blocked_range2d<int> &r){ int x0 = r.cols().begin(), y0 = r.rows().begin(), x1 = r.cols().end(), y1 = r.rows().end(); ... for (int x = x0; x < x1; ++x) { for (int y = y0; y < y1; ++y) { // 179 fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255); } } ...
関心のあるループは、インテルスレッディングビルディングブロック(インテルTBB)ライブラリの並列ループから呼び出されます。 外側のループの反復は、異なるスレッド間で分散されます。各スレッドは、タイプtbb :: blocked_range2dのオブジェクト- 独自のローカル反復スペースを受け取ります。 このスペースでの反復回数をどれだけ小さくできるかは、パラメーターinner_grain_sizeに依存します。 つまり 行179のループの反復回数を決定するr.rows()。end()の値は、 inner_grain_sizeに依存します 。
コードでは、この非常に粒度が大きくなっています(2つのネストされた並列ループに対して2つあります)。
int grain_size = 64; int inner_grain_size = 8;
inner_grain_sizeを32に増やしようとしています。これから悪いことは何も期待されていません。IntelTBBストリームで作業を分割するだけで粗くなります。 結果を見てみましょう:
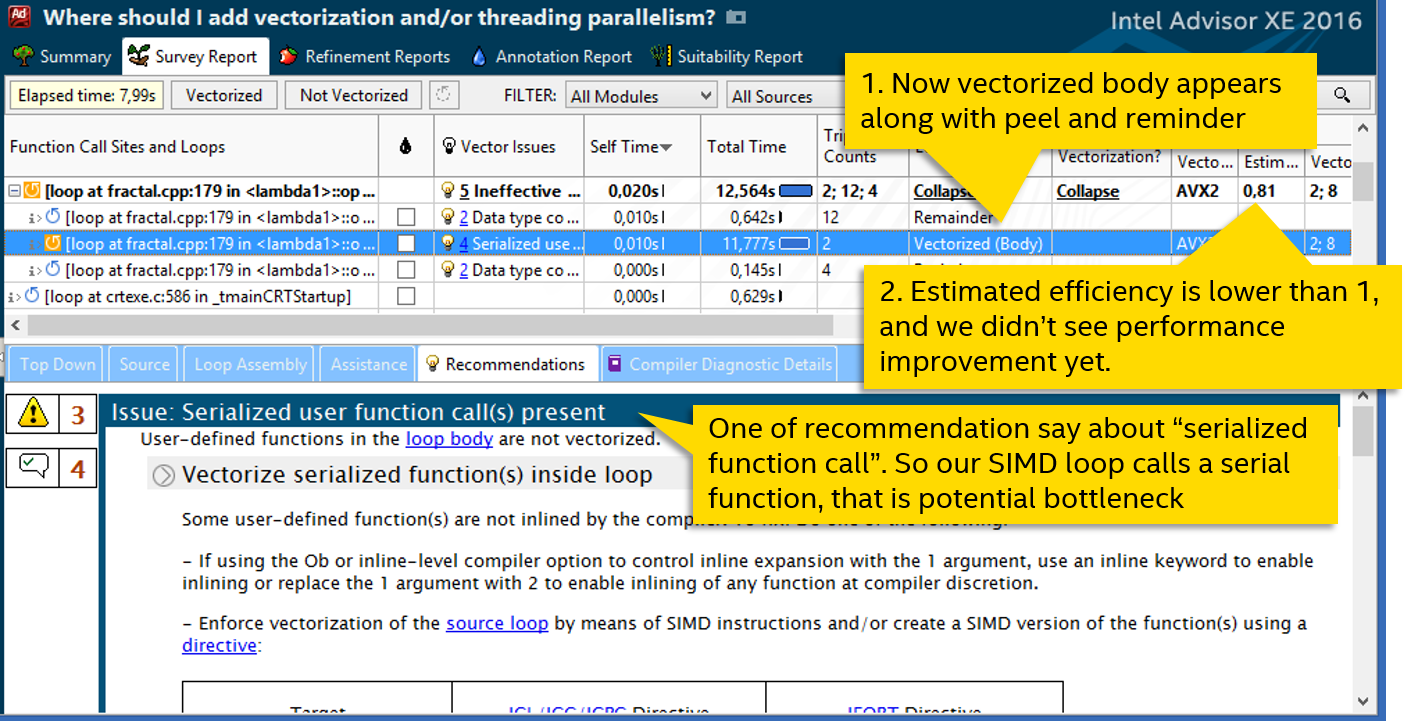
これで、ベクトル化されたボディがループに表示され、最終的にSIMD命令を実際に使用し、ループがベクトル化されました。 しかし、喜ぶには早すぎます-生産性は向上していません。
4.関数をベクトル化する
Advisor XEの推奨事項を確認します。そのうちの1つは、シリアル化された(順次)関数の呼び出しについて説明しています。 事実は、ベクトルサイクルが関数を呼び出す場合、通常のスカラー変数ではなく、ベクトルによってパラメーターを取得できるベクトル化バージョンが必要なことです。 コンパイラーがそのようなベクトル関数を生成できなかった場合、通常の順次バージョンが使用されます。 また、連続して呼び出され、ベクトル化全体を無効にします。
繰り返しますが、ループコードを見てください:
for (int y = y0; y < y1; ++y) { // 179 fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255); }
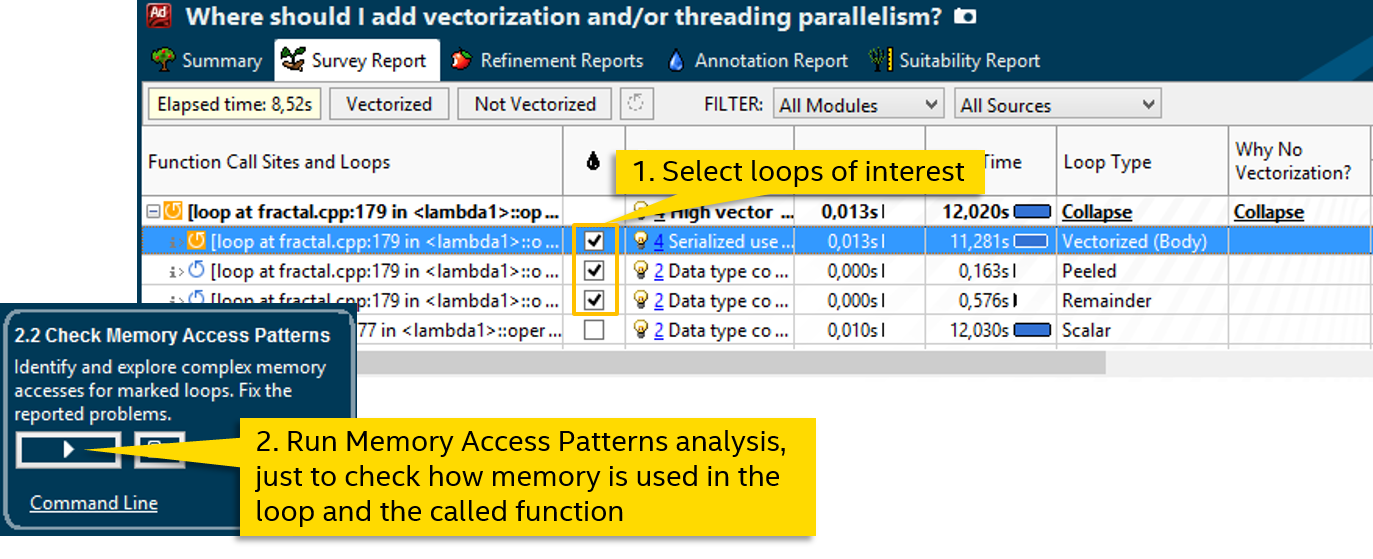
幸いなことに、関数呼び出しはcalc_one_pixelのみです 。 コンパイラはベクターバージョンを生成できなかったため、支援を試みます。 しかし、最初に、メモリアクセスパターンを見てみましょう。これは明示的なベクトル化に役立ちます。
サイクルのメモリアクセスパターンの分析(呼び出された関数と一緒に)は、すべての読み取りまたは書き込み操作が0単位の単位ストライドであることを示しています。つまり、 各反復から外部データにアクセスすると、同じ変数が読み書きされます。
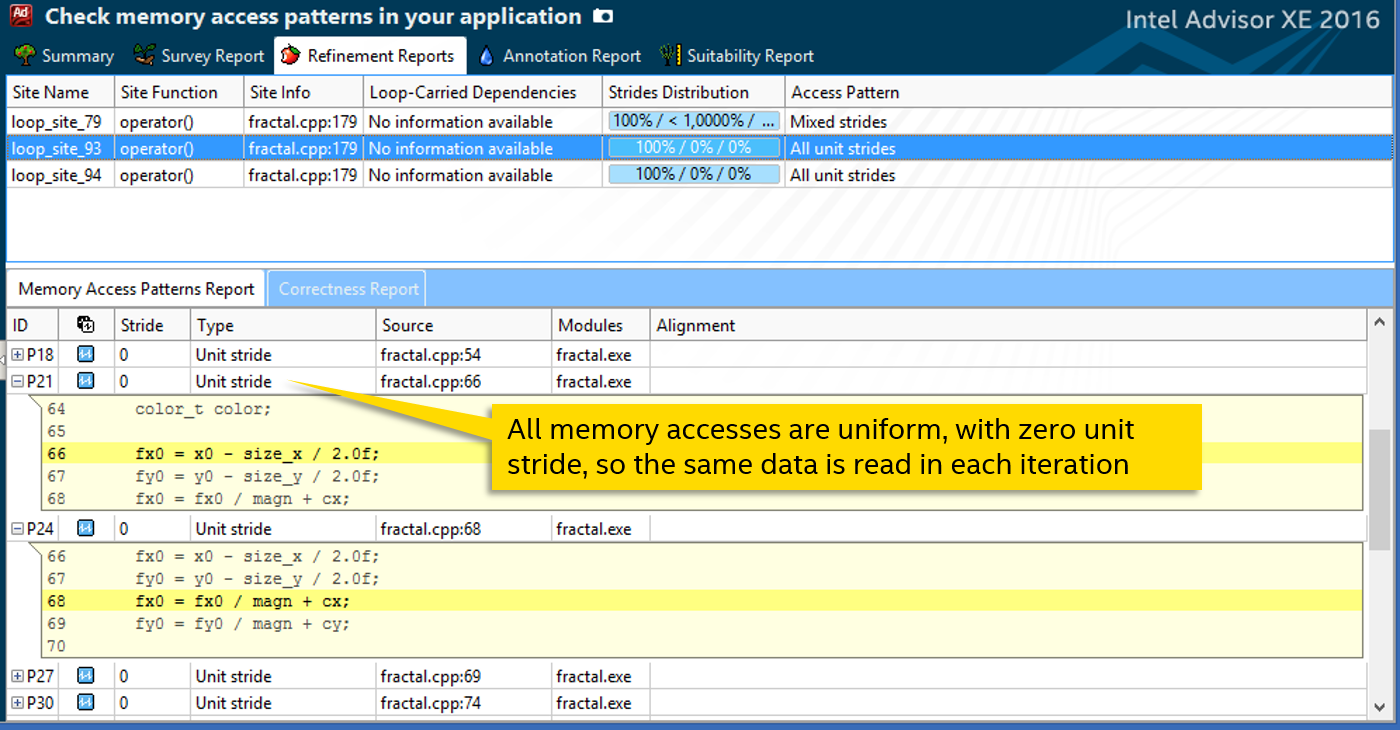
この知識は、関数の手動ベクトル化に役立ちます。 OpenMP 4標準の#pragma omp simdディレクティブを使用し、パラメーターにアクセスするためのテンプレートを定義するオプションがあります。 たとえば、「線形」は単調に増加する量、主に反復変数に使用されます。 ユニフォームは私たちに適しています-同じデータへのアクセスに。
#pragma omp declare simd uniform(x0, max_iterations, size_x, size_y, magn, cx, cy, gpu) color_t fractal::calc_one_pixel(float x0, float y0, int max_iterations, int size_x, int size_y, float magn, float cx,
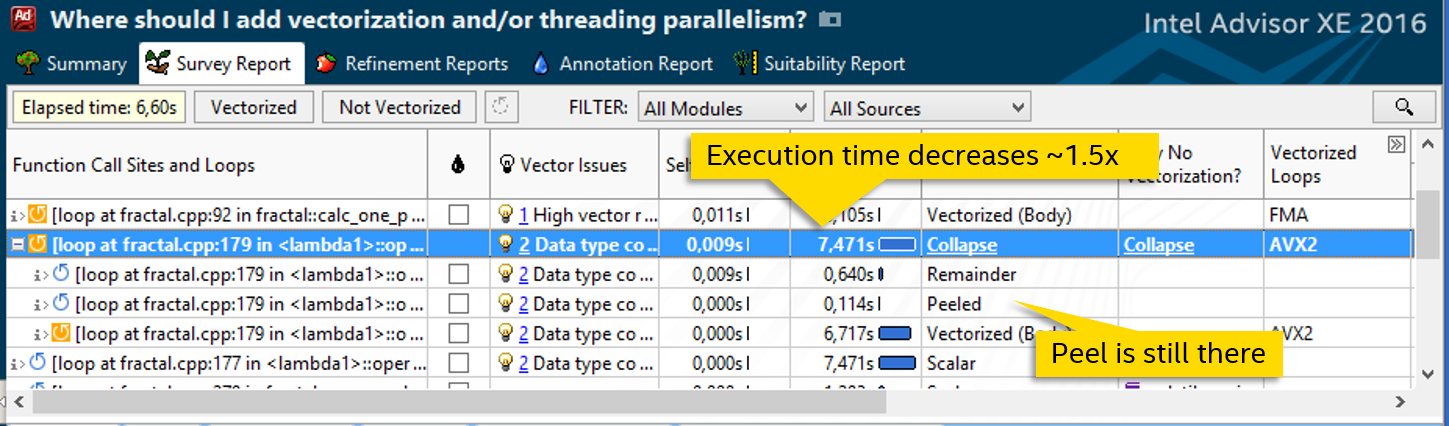
関数の定義にディレクティブを追加することにより、コンパイラーは、宣言されたスカラーの代わりにデータの配列を処理できるベクターバージョンを生成できるようになりました。 速度が著しく向上します-サイクルは12秒ではなく7.5秒実行されます。
5.データを揃える
ベクトルサイクルの非効率性の他の理由に対処してみましょう。 剥離部分の存在は、データが整列していないことを示します。 calc_one_pixelの結果が書き込まれる配列を定義する前に__declspec(align(32))を追加します。
__declspec(align(32)) color_t fractal_data_array[delta_x][(delta_y / 16 + 1) * 16]; // aligned data for (int x = x0; x < x1; ++x) { #pragma simd for (int y = y0; y < y1; ++y) { fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255); } }
その後、皮は消えます:

6.スキャンループを削除する(展開)
Advisor XE診断テーブルでは、もう1つ注意することができます-「変換」列は、コンパイラが2の係数で展開されたことを示しています。

つまり 最適化するために、反復回数は半分になります。 これ自体は悪いことではありませんが、3番目のステップで具体的にそれらを増加させようとしましたが、コンパイラーは反対の動作をすることがわかりました。 #pragma nounrollを使用してスイープを無効にしてみましょう:
#pragma simd #pragma nounroll // added unrolling for (int y = y0; y < y1; ++y) { fractal_data_array[x - x0][y - y0] = calc_one_pixel(x, y, tmp_max_iterations, tmp_size_x, tmp_size_y, tmp_magn, tmp_cx, tmp_cy, 255); }
その後、予想される反復回数は2倍になりました。
7.反復回数をさらに増やす
アンロールを使用した操作では、反復回数を増やすことができましたが、パフォーマンスの改善はありませんでした。 手順3のように、 grain_sizeをさらに増やすとどうなるか見てみましょう。最適な値を経験的にテストします。
int grain_size = 256; // increase from 64 int inner_grain_size = 64; // increase from 8
かなりではあるが、もう少し絞ることが判明した。

8.結果
すべての操作の後、テストアプリケーションの実行時間は4.51秒から1.92秒に短縮されました。 約2.3倍の加速を達成しました。 私たちの計算テストはすでに部分的に最適化されていることを思い出させてください-インテルTBBにストリーム並列し、マルチコアプロセッサで優れた加速とスケーラビリティを実現します。 しかし、ベクトル化が十分に活用されていないという事実のため、可能なパフォーマンスの半分が失われました。 最初の結論は、 ベクトル化が非常に重要になる可能性があるということです;それを無視しないでください。
次に、さまざまな変更の効果を見てみましょう。

ベクトル化を強制し、反復回数(ステップ2および3)を増やすだけでは、プログラムの速度は上がりませんでした。 関数のベクトル化後にステップ4で受け取った速度の最も重要な増加。 ただし、これは手順2〜4の累積効果です。 ループの実際のベクトル化では、反復回数を増やし、ベクトル化を強制し、関数をベクトル化する必要がありました。
また、後続の手順には特別な効果はありませんでした。この場合、完全にスキップできます。 ステップ7は多かれ少なかれ成功したものに起因する可能性があります。これは、ステップ3で多数の反復をすぐに設定しなかったためです。 ただし、この投稿の目的は、特定の例を使用してAdvisor XEの機能を示すことであったため、実行されるすべての手順について説明します。