ただし、他人をscるのはいつでも簡単ですが、何かをするのは簡単ではありません。 応答テンプレートに手動で入力するのではなく、ダイアログサンプルを使用してニューラルネットワークをトレーニングすることでチャットボットを作成できるかどうか興味がありました。 インターネットでのクイック検索では有用な情報が得られなかったため、いくつかの実験をすばやく行い、何が起こるかを確認することにしました。
通常のチャットボットは、特定のパターンで定義された表面的な回答に限定されます。 訓練されたチャットボット(一部あります)は、ダイアログのデータベースで同様の質問に対する回答を探し、時には新しいテンプレートを作成します。 しかし、それでも、彼の「心」は通常、与えられたアルゴリズムによって上から厳しく制限されています。 しかし、入り口での質問の原理で動作するニューラルネットワークを備えたボット-出口での回答-は、理論的には無制限です。 ニューラルネットワークは、自然言語で入力を受け取ることによって論理推論のルールを学習できること、およびさまざまなテキストに関する質問に答えることができることが示されている作品があります。 しかし、私たちはまだそれほど野心的ではなく、典型的なチャットボットの答えに似たものを得ようとしています。
データのソースとして、英語での会話の写し(3860の複製から成る)のみがすぐに見つかりました。 私たちのアプローチでは、言語は根本的な違いをもたらさないので、それは経験にとって良いことです。 まず、比較するために、対話者のフレーズ内の単語の一致に基づいて(「ワードバッグ」である質問ベクトルと回答ベクトルの角度の余弦によって)トランスクリプトから既製の回答を選択する簡単なチャットボットを急いでまとめました。 プログラム全体は30行に収まります。
起こったことは次のとおりです。
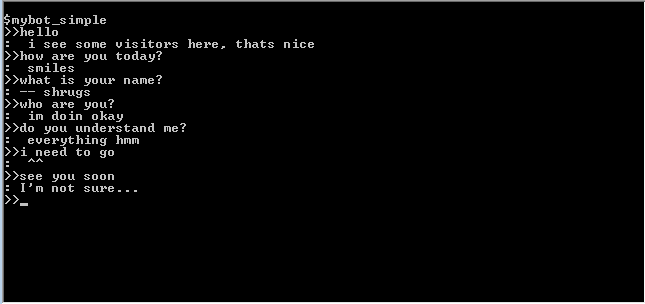
翻訳(概算)(H:-人、P:-プログラム):
H:こんにちは
P :ここに訪問者がいますが、それは良いことです
W:お元気ですか
P:笑顔
W:お名前は?
P:肩をすくめる
W:あなたは誰ですか?
P:元気です
W:あなたは私を理解していますか?
P:絶対にすべて、うーん...
C:行かなければならない
P: ^^
W:またね
P:わからない
表面的な調査は、このような単純なプログラムに対して非常によく反応し、彼女の名前の真実と彼女が誰なのかを知りません...すべてのコミュニケーションの90%は表面的ですか?)。
次に、より複雑なアルゴリズムに目を向けます。 テンプレートチャットボットはユーザーを「欺く」目的で作成され、さまざまなトリックを使用してコミュニケーションの錯覚を作成するため、ここでの難易度はすぐに良いというわけではありません。
ニューラルネットワークを使用してテキストを生成する方法 これに対する現在の古典的な方法は、神経言語モデルです。 要するに、ニューラルネットワークには、n個前の単語に基づいて次の単語を予測するタスクが与えられます。 出力ワードは、1つの出力ニューロン-1つのワード(図を参照)の原則に従ってエンコードされます。 入力単語は同じ方法でエンコードするか、意味の近い単語が異なる意味の単語よりも短い距離にあるベクトル空間で単語の分散表現を使用できます。
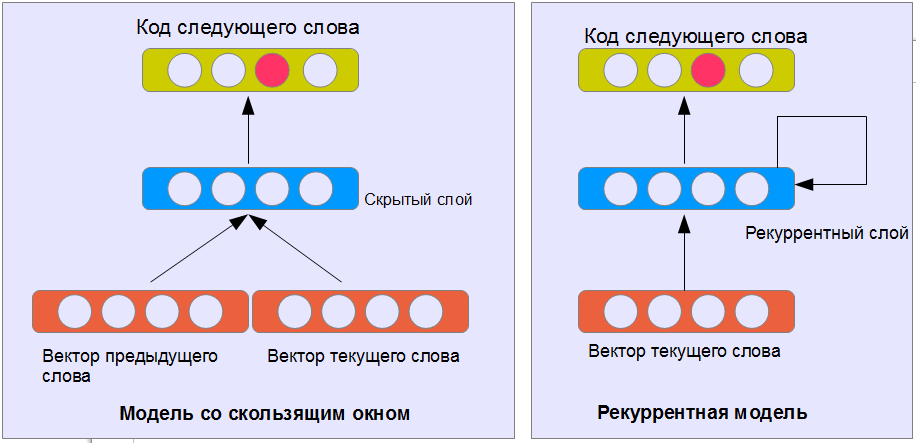
訓練されたニューラルネットワークは、テキストを生成し、その最後を予測できます(最後に予測された単語を最後に追加し、ニューラルネットワークを新しい細長いテキストに適用します)。 このようにして、応答モデルを作成できます。 1つの問題-答えは対談のフレーズとは関係ありません。
問題の明らかな解決策は、入力の前のフレーズの表現を提出することです。 どうやってやるの? 文章の分類に関する以前の記事で検討した多くの可能な方法のうちの2つ。 最も単純なNBoWオプションは、前のフレーズのすべての単語ベクトルの合計を使用することです。
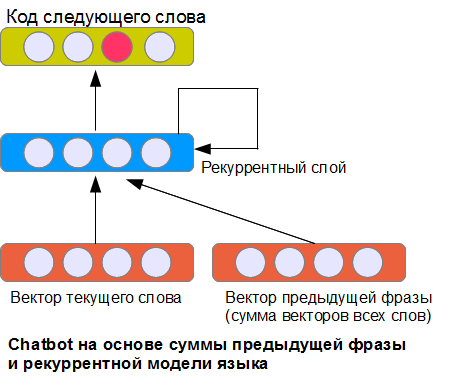
写真に示されているアーキテクチャは、唯一可能なものではありませんが、おそらく最も単純なものの1つです。 リカレントレイヤーは、現在の単語に関連する入力、前のフレーズを表すベクトル、および前のステップでの自身の状態を受け取ります(これがリカレントと呼ばれる理由です)。 このため、ニューラルネットワークは(理論的に)フレーズの無制限の長さで前の単語に関する情報を記憶できます(固定サイズのウィンドウからの単語のみが考慮される実装とは対照的です)。 もちろん、実際には、このような層は学習に一定の困難をもたらします。
ネットワークのトレーニング後、次のことが起こりました。
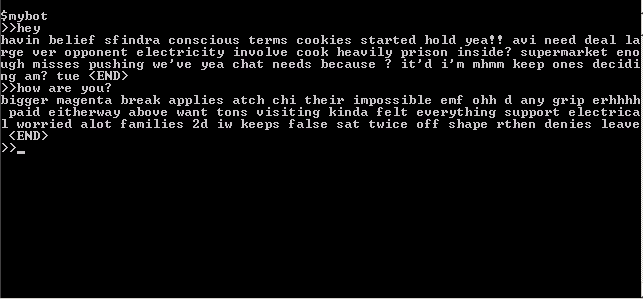
うーん...多かれ少なかれ意味のない単語のセット。 文章を構成する際に単語と論理の間に関係はありませんが、一般的な意味はなく、質問との関係もありません(少なくとも、私にはわかりません)。 さらに、このボットはあまりにもおしゃべりです-単語は大きな長いチェーンで加算されます。 これには多くの理由があります-これは、トレーニングサンプルの量が少ない(約15,000ワード)こと、およびリカレントネットワークのトレーニングが困難であるためです。 実際、これは予想されていたことであり、額の問題が解決されていないことを示すためにこのオプションを用意しました。 実際には、学習アルゴリズムとネットワークパラメーターの正しい選択を使用すると、より興味深いオプションを実現できますが、フレーズの繰り返しの繰り返し、文が終了する場所の選択の難しさ、元のトレーニングサンプルから長い断片をコピーするなどの問題が発生します。さらに、そのようなネットワークを分析することは困難です-何が学習され、どのように機能するかは明確ではありません。 したがって、このアーキテクチャの機能を分析する時間を無駄にせず、より興味深いオプションを試してみます。
2番目のバージョンでは、前の記事で説明したたたみ込みネットワークを繰り返し言語モデルに接続しました。
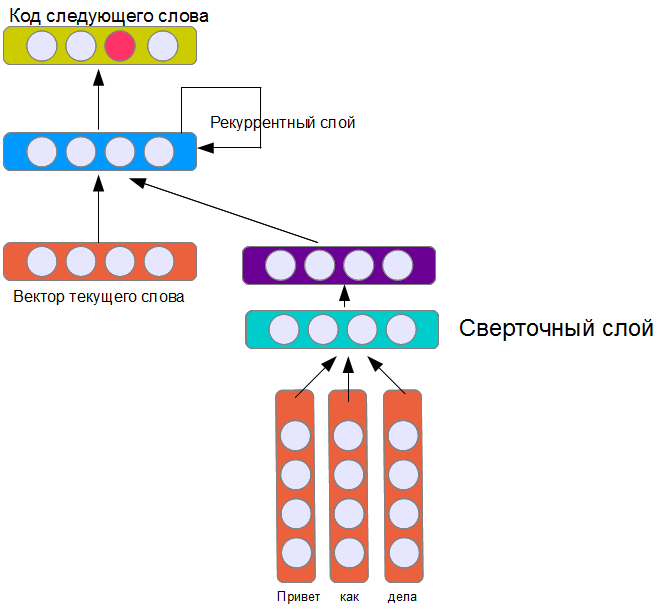
前の記事のネットワークと同様に、畳み込み層には16個のフィルターが含まれています。 一般的な考慮事項から、この4層モデルは学習が難しくなり、結果が悪化することが予想されます。 また、対話者のレプリカモデルを作成するには、16個のフィルターが明らかに不十分であると思われます。 確かに、彼女の訓練にははるかに時間がかかりますが、結果は...一般的に、あなた自身で判断してください:
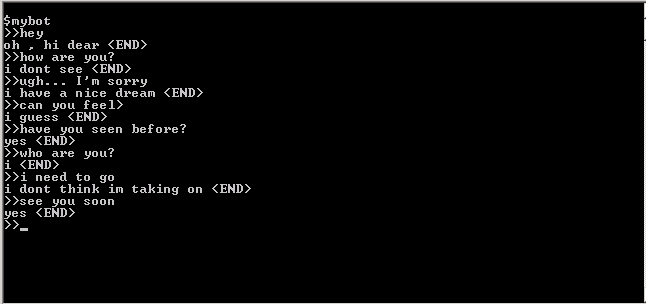
対話の翻訳(概算)(H:-人、P:-プログラム)
H:こんにちは
P:こんにちは
W:お元気ですか?
P:見えない
W:おっと...ごめんなさい
P:いい夢を見ているようです
W:感じますか?
P:私は思う
C:前に見えますか?
P:はい
W:あなたは誰ですか?
P:私
C:行かなければならない
P:これを受け入れることができるかどうかわからない
W:またね
P:はい
私の意見では、非常に印象的です。 コンピューターで人工知能が生き生きとするSF小説の断片、特に見ることはできないが前に見ることができるプログラムの主張を思い出します。 AIの作成と大きな成果を宣言する時が来ました...
実際、もちろん、このニューラルネットワークにはインテリジェンスがありませんが、インテリジェンスはありませんが、それほど面白くありません。 実際には、入力フレーズに対する畳み込み層ニューロンの活性化の依存性を追跡することにより、実際に学習したことを分析することができます。 このような分析により、あいさつ語( "hello"、 "hi"、 "he" yなど)に応答するニューロンと、 "have you ...?"などの疑問句を認識するニューロンを検出することができました。質問はオプションです(通常、ニューラルネットワークは「はい」と答えることを学習しました)。さらに、質問に「あなた」という単語が表示された場合、答えが単語「I」で始まる可能性(「I」 )
したがって、ニューラルネットワークは典型的な会話パターンと言語トリックを学習しました。これらは、「手動で」チャットボットをプログラミングするときによく使用され、16の使用可能なフィルターを適切に管理します。 単純な畳み込みネットワークを多層ネットワークに置き換え、フィルターを追加し、トレーニングサンプルを増やすことで、テンプレートの手動選択に基づいて、対応するチャットボットよりも「スマート」に見えるチャットボットを取得できます。 しかし、この質問はすでに記事の範囲を超えています。