はじめに

図1.さまざまなプロセッサマイクロアーキテクチャのベクトルレジスタの幅
プロセッサの新しいマイクロアーキテクチャの重要な部分は、ベクトルレジスタの長さの増加と、すべてがMMX、SSE、AVX、AVX2として知られる新しいベクトル命令セットの出現です。これにより、1つの命令で同じタイプの複数の操作を実行できるようになります。 ベクトル化によってプログラムを高速化する方法を理解するには、次のチャートをご覧ください。
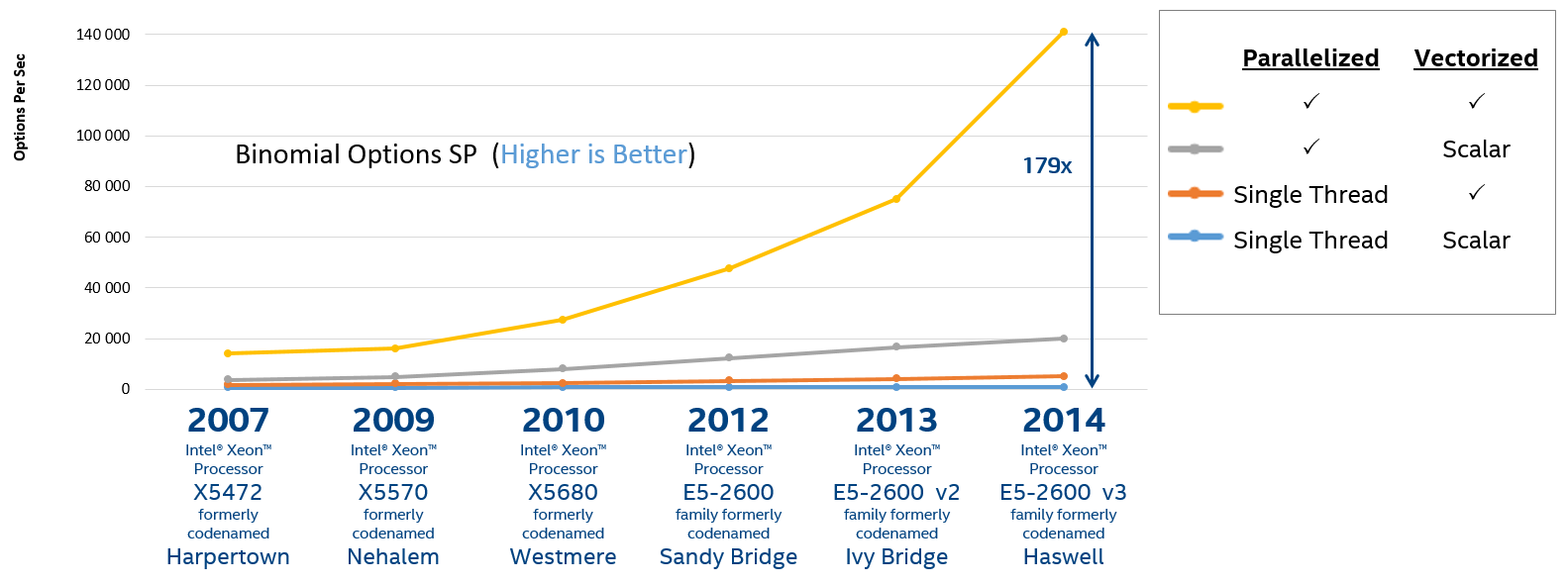
図2.バイナリオプション計算プログラムのさまざまなバージョンのパフォーマンス
このベンチマークの可能な合成にも関わらず、彼は、多くの人に既に馴染みのあるスレッド処理だけでなく、ベクトルレジスタの効率的な使用も最大のパフォーマンスを達成するための重要な要素であると言います。 ベクトル化を実現する一般的な方法はいくつかあります。
- コンパイラによる自動ベクトル化。
- OpenMP * 4.0標準(後で使用します)およびIntel Cilk Plusの使用。
- マネージコンパイラのベクトル化-#pragma ivdepや#pragma vectorなどのベクトルディレクティブの使用。
- Intel Cilk Plusアレイ表記法。
さらに、アセンブラコードでの組み込み関数の使用やベクトル命令の使用など、より複雑な方法があります。
幸いなことに、コンパイラの新しいバージョンのリリースにより、自動ベクトル化はよりアクセスしやすく効率的になっています。 この問題でコンパイラがどのように成功したかを確認するには、コンパイルキー(インテル®コンパイラーの場合は-optreport)を追加し、各サイクルの詳細と結果のアクセラレーションを含むベクトル化に関するレポートを読むことができます。 しかし、多くの場合、すべてが単純なものとはほど遠いため、コードをベクトル化できること、またコードを書き換える必要があることをコンパイラーが何らかの形で理解できるようにする必要があります。 また、ベクトル化されたコードがパフォーマンスの面でデフォルトで最も効率的であるとは思わないでください。 サイクルはベクトル化されていますが、実際の加速はかなり小さいことがよくわかります。 これらの問題により、最適化エンジニアの作業は非常に困難で日常的なものになります:コードの調査、コンパイラからのメッセージの確認、アセンブラコードとデータアクセスパターンの調査、新しいバージョンの正確性の確認、必要な部分の変更、パフォーマンスの評価などが必要です。
良いニュース:ベクトル化アドバイザーにより、ルーチンが非常に簡単になります!
Intel Parallel Studio XEパッケージは、パフォーマンス評価のためにコードを分析する十分な機会を提供しますが、以前のコードベクトル化の評価は完全にはカバーされていませんでした。 Intel Parallel Studio XE 2016 Betaには、高度に更新されたIntel Advisor XE 2016 Betaが含まれており、実際には2つの製品を組み合わせています。
- スレッドアシスタント-以前はIntel Advisorにあったすべてのものに、いくつかの改善が加えられました。
- ベクトル化アドバイザーは、SIMDプログラムを分析するためのまったく新しいツールです。
どこから始めますか? パフォーマンスの問題と考えられる原因に焦点を合わせるには、調査を実行する必要があります。
ステージ1.プロファイリング(調査対象)
したがって、ベクトル化アドバイザーが最初に行うことは、アプリケーションを起動してプロファイルを作成することです。 このツールは、ホットスポット分析、バイナリモジュールの静的分析、コンパイラメッセージなど、各サイクルの完全なレポートを提供します。 さらに、新製品にはベクトル化の専門家からの推奨事項と診断機能が含まれており、その一部のみがIntel Developer Zoneにあります。

図3.調査分析後の詳細なプログラムレポート
以下に示すスクリーンショットは、調査後にユーザーが多くの重要な情報を受け取ることを示しています。まず、最も時間のかかるものを選択するために、サイクルに費やされた時間(自己時間と合計時間)に注意します。 次に、まだベクトル化されていないループに集中できます。 図3はスカラーサイクルを示しており、これをさらに検討して最適化します。 このサイクルにはコンパイラー診断があります-サイクルがベクトル化されなかった理由に関する情報。ここでは、コンパイラーは依存関係の存在を想定しています。 また、以下のステップ1.1のスクリーンショット(図4)に示すように、ベクトル化アドバイザーはパフォーマンスの問題とそれらを解決する方法を探し、コンパイラー情報だけでなく、バイナリファイルの静的分析も使用します:加速推定、アセンブラー命令のさまざまな特性、データ型などなど。 このデータはすべて、サイクルごとにここにあります。
この段階で得られた情報は、何を改善する必要があるかを判断し、最適化されたプログラムに向けて第一歩を踏み出すのに十分であると想定されます。
ステップ1.1反復回数の検索(トリップカウントの検索)
多くの場合、ベクトル化されたループの非効率的な生成に関する問題を解決するには、ループ内の反復回数を知る必要があります。 反復回数が一定でない場合(したがって、コンパイラはそれを推定して最適化に使用することはできません)、測定してコンパイラにヒントを与えることができます。 これを行うために、新しいタイプの分析がVectorization Advisor-Trip Countsに登場しました。 この分析のもう1つの利点は、調査後に収集されたプログラム全体のプロファイルに統合されることです。
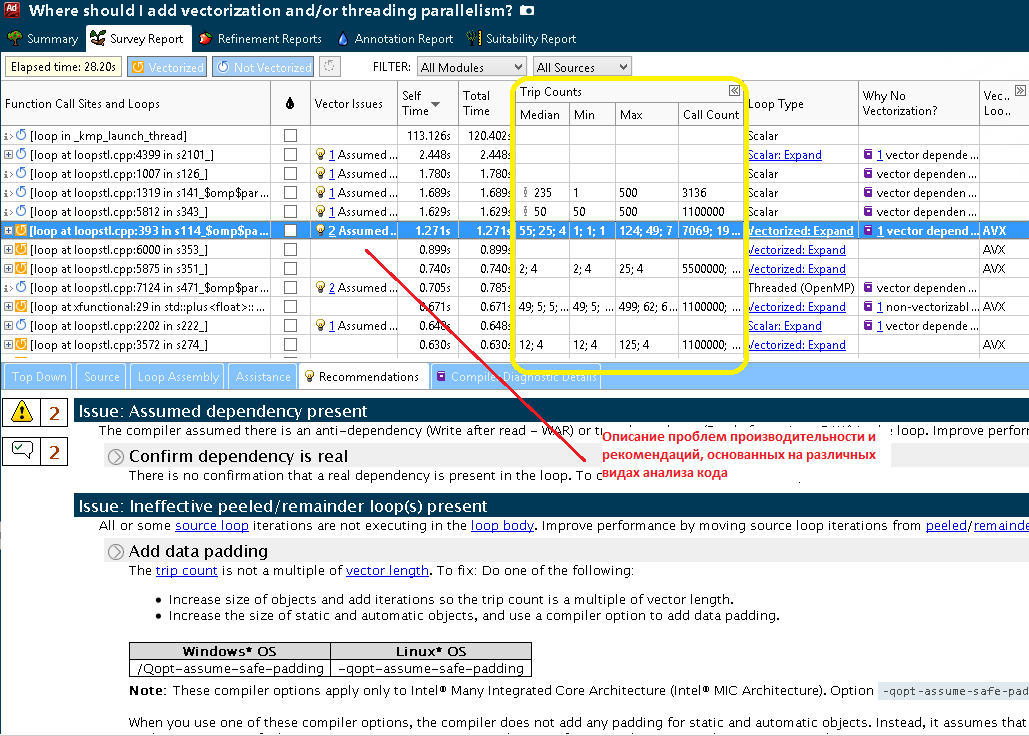
図4.反復サイクルの数で補完されたプログラムレポート
反復回数を検索した後に黄色で表示される列は黄色でマークされます。 ここでは、繰り返しの平均、最小、および最大数、ループ内のエントリ数、および平均とは異なる繰り返し数を持つかなりの数のエントリを示すインジケータが表示されます。 前述したように、選択したサイクルは依存関係の存在が予想されるためベクトル化されませんでした。 サンプルコードをより詳細に検討してください。
#pragma omp parallel for private(i__3,j,k,i__) schedule(guided) if(i__2 > 101) for (i__ = 1; i__ <= i__2; ++i__) { k = i__ * (i__ + 1) / 2; i__3 = *n; for (j = i__; j <= i__3; ++j) { cdata_1.array[k - 1] += bb[i__ + j * bb_dim1]; k += j; } }
外部ループは、OpenMPストリームを使用して並列化されます。 内側のループをベクトル化するのは良いことですが、Advisor XEはデータの依存関係の可能性について話します。これを確認しましょう。
ステップ2.1正当性を確認する
ベクトル化を妨げる可能性のあるデータを使用して可能な依存関係を確認するために、関心のあるサイクルに注意して、Correctnessを実行します。
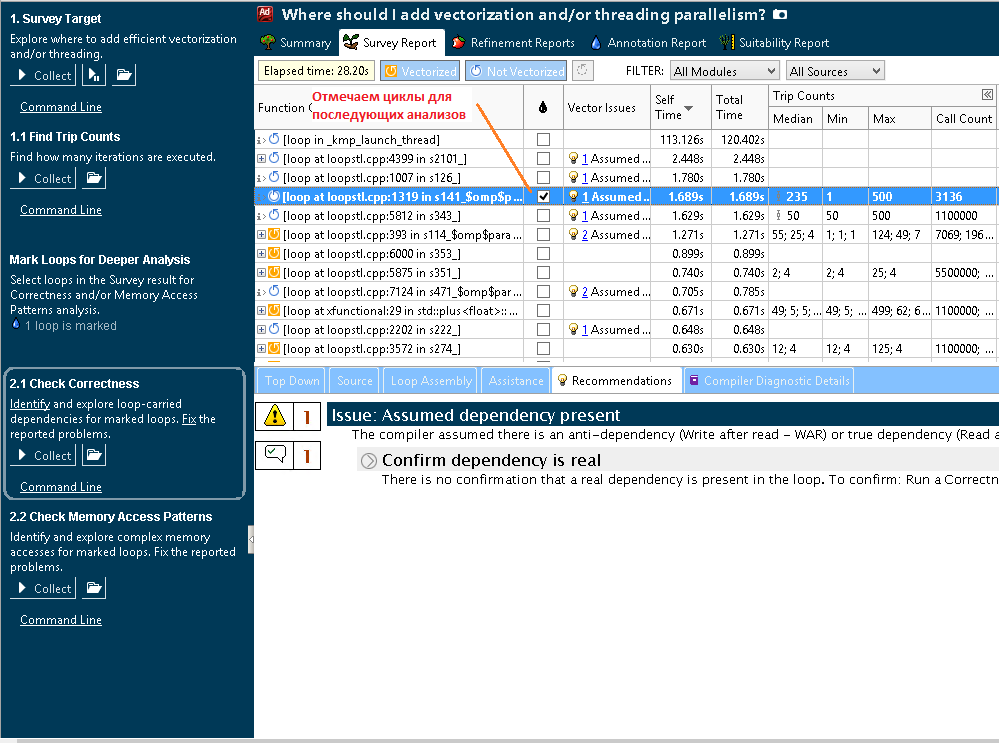
図5.その後の正確性の分析のためのサイクルの選択
データを収集した後、この例でAdvisor XEがコードをベクトル化する機能を妨げる問題を見つけなかったことがわかります。

図6.正当性分析後のレポート
ベクトル化の安全性を確信していたため(図6に依存関係は見つかりませんでした)、目的のサイクルをベクトル化するためにコンパイラーを「作成」します。このため、ディレクティブを追加します。
#pragma omp simd
ループの前:
#pragma omp parallel for private(i__3,j,k,i__) schedule(guided) if(i__2 > 101) for (i__ = 1; i__ <= i__2; ++i__) { k = i__ * (i__ + 1) / 2; i__3 = *n; #pragma omp simd for (j = i__; j <= i__3; ++j) { cdata_1.array[k - 1] += bb[i__ + j * bb_dim1]; k += j; } }
Surveyを再構築すると、次の結果が得られます。

図7.最適化のために選択されたサイクルで得られた結果
サイクルは、AVX命令を使用してベクトル化されました。 サイクルタイムは0.77秒に低下しました-2倍以上の加速が得られました!
ステップ2.2メモリアクセスパターンの確認
正確性の分析と同様に、選択したサイクルは、メモリを操作する効果について確認できます。 これは重要です。なぜなら、ベクトル化は、データへのアクセスの順序に応じて多かれ少なかれ効率的である可能性があるためです。たとえば、通常、アライメントされたデータへのアクセスは、より効率的なコードを提供します。 情報を取得し、メモリアクセスパターンの分析を実行するサイクルに注意してください。
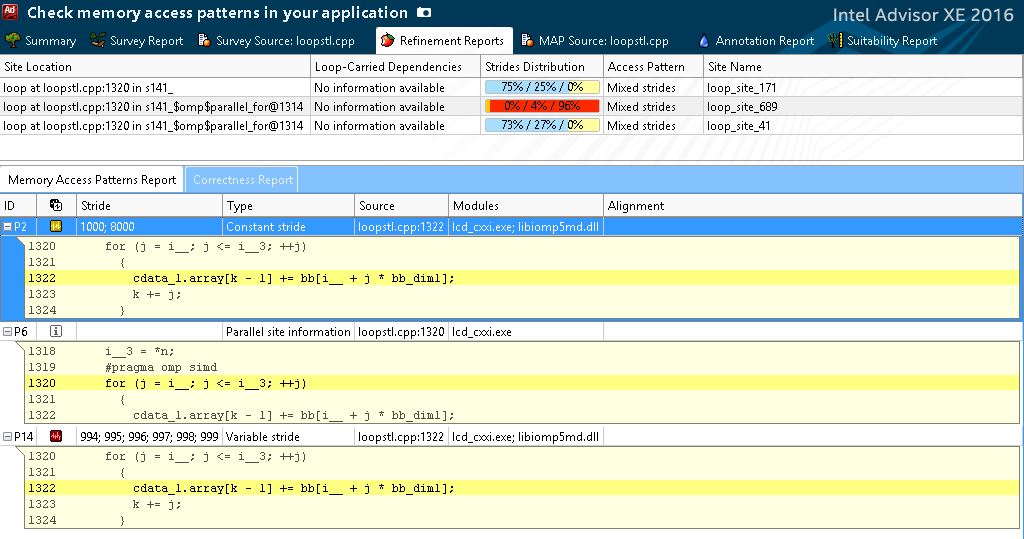
図8.データアクセステンプレートのレポート
図8に示すように、bb(ストライド)配列のステップは一定で、8000または1000(bb_dim1の異なる呼び出しで等しい)に等しくなります。 c_data_1.array配列に沿ったステップは可変(994; 995; 996 ...)ですが、アルゴリズムを書き換えずに修正することは非常に困難です。 単一のステップを踏むことをお勧めします。それにより、コンパイラーが最終的に行うデータのプリフェッチを編成します。 これは、「命令セット分析」列の命令の分析から確認できます。これに固有の挿入およびシャッフルがあります。
結論
ベクトル化アドバイザーは、追加のベクトル化が必要な作業コードが既に存在する場合に役立ちます。 新しいツールの助けを借りて、誰もがアプリケーションのボトルネックの詳細なプレゼンテーションを含む完全なレポートを取得できるだけでなく、それらを排除する方法に関する推奨事項も取得できます。 ベクトル化アドバイザーが登場する前に手動で分析を試みたユーザーは、膨大な時間を節約でき、これが可能であることをまだ知らなかったユーザーは、自分でアプリケーションを最適化する素晴らしい機会を得るでしょう!