はじめに
現在、機械学習は科学研究の活発に発展している分野です。 これは、データをより速く、
ディープラーニングでは、原則として人工ニューラルネットワークとして表されるさまざまな順次非線形変換を使用して、データの高レベルの抽象化をモデル化する方法を検討します。 今日、ニューラルネットワークは、予測、パターン認識、データ圧縮などの問題を解決するために使用されています。
機械学習、特に深層学習のトピックの関連性は、Habréの主題に関する記事が定期的に表示されることで確認されます。
この記事は、いくつかのディープラーニングソフトウェアツールの比較分析に当てられており、その多くが最近登場しました[ 1 ]。 これらのツールには、ソフトウェアライブラリ、プログラミング言語の拡張、およびニューラルネットワークモデルの作成とトレーニングに既製のアルゴリズムを使用できる独立した言語があります。 既存のディープラーニングツールにはさまざまな機能があり、ユーザーにはさまざまなレベルの知識とスキルが必要です。 適切なツールを選択することは、最小限の時間で少ない労力で目的の結果を達成できる重要なタスクです。
この記事では、ニューラルネットワークモデルを設計およびトレーニングするためのツールの概要を簡単に説明します。 焦点は、 Caffe 、 Pylearn2 、 Torch 、およびTheanoの 4つのライブラリーです。 これらのライブラリの基本的な機能が考慮され、その使用例が示されています。 手書きの数字を分類する問題を解決するためにニューラルネットワークの同じトポロジを比較する場合のライブラリの品質と速度が比較されます( MNISTデータセットはトレーニングおよびテストサンプルとして使用されます)。 また、問題のライブラリの実用性を評価する試みも行われています。
MNISTデータセット
さらに、手書き数字MNISTの画像のベースは、調査対象のデータセットとして使用されます( 図1 )。 このデータベースの画像の解像度は28x28で、グレースケール形式で保存されます。 番号は画像の中央にあります。 データベース全体は2つの部分に分かれています。50,000個の画像で構成されるトレーニングと、10,000個の画像です。

図 1. MNISTデータベース内の数字の画像の例
深層学習タスク用のソフトウェア
ディープラーニングタスクを解決するためのソフトウェアツールは多数あります。 [ 1 ]では、最も有名な機能の一般的な比較を見つけることができます。ここでは、それらのいくつかに関する一般的な情報を示します( 表1 )。 最初の6つのソフトウェアライブラリは、広範なディープラーニングメソッドを実装しています。 開発者は、完全に接続されたニューラルネットワーク(完全に接続されたニューラルネットワーク、FC NN [ 2 ])、畳み込みニューラルネットワーク(CNN)[ 3 ]、自動エンコーダー(自動エンコーダー、AE)および制限付きボルツマンマシン(制限付きボルツマンマシン、 RBM)[ 4 ]。 残りのライブラリに注意を払う必要があります。 機能が少ないという事実にもかかわらず、場合によっては、シンプルさでパフォーマンスを向上させることができます。
表1.深層学習機能[ 1 ]
| # | 役職 | 言語 | OC | FC NN | CNN | ええ | RBM |
| 1 | DeepLearnToolbox | Matlab | Windows Linux | + | + | + | + |
| 2 | テアノ | Python | Windows、Linux、Mac | + | + | + | + |
| 3 | Pylearn2 | Python | Linux、Vagrant | + | + | + | + |
| 4 | ディープネット | Python | Linux | + | + | + | + |
| 5 | ディープマット | Matlab | ? | + | + | + | + |
| 6 | トーチ | ルアC | Linux、Mac OS X、iOS、Android | + | + | + | + |
| 7 | ダーチ | R | Windows Linux | + | - | + | + |
| 8 | カフェ | C ++、Python、Matlab | Linux OS X | + | + | - | - |
| 9 | nnForge | C ++ | Linux | + | + | - | - |
| 10 | Cxxnet | C ++ | Linux | + | + | - | - |
| 11 | Cuda-convnet | C ++ | Linux、Windows | + | + | - | - |
| 12 | Cuda CNN | Matlab | Linux、Windows | + | + | - | - |
[ 1 ]の情報と専門家の推奨に基づいて、さらに検討するために4つのライブラリーが選択されました。 各ライブラリは、次の計画に従って検討されます。
- 短い参照情報。
- 技術的機能(OS、プログラミング言語、依存関係)。
- 機能性
- ロジスティック回帰などのネットワークを形成する例。
- 分類のための構築されたモデルのトレーニングと使用。
リストされたライブラリを確認した後、それらは多くのテストネットワーク構成で比較されます。
カフェライブラリー
Caffeは2013年9月から開発中です。開発は、カリフォルニア大学バークレー校での勉強中にYangqing Jiaから始まりました。 それ以来、CaffeはThe Berkeley Vision and Learning Center( BVLC )およびGitHub開発者コミュニティによって積極的にサポートされています。 ライブラリは、BSD 2-Clauseの下でライセンスされています。
CaffeはC ++プログラミング言語を使用して実装され、PythonおよびMATLABにはラッパーがあります。 公式にサポートされているオペレーティングシステムはLinuxとOS Xであり、Windowsには非公式の移植版もあります 。 Caffeは、ベクトルおよび行列計算にBLASライブラリ(ATLAS、Intel MKL、OpenBLAS)を使用します。 これに加えて、外部依存関係には、glog、gflags、OpenCV、protoBuf、boost、leveldb、nappy、hdf5、lmdbが含まれます。 コンピューティングを高速化するために、CUDAテクノロジの基本機能またはcuDNN深層学習プリミティブライブラリを使用して、CaffeをGPUで実行できます。
Caffe開発者は、完全に接続された畳み込みニューラルネットワークの作成、トレーニング、およびテスト機能をサポートしています。 入力データと変換は、 レイヤーの概念によって記述されます。 ストレージ形式に応じて、次のタイプのソースデータレイヤーを使用できます。
- DATA-leveldbおよびlmdb形式でデータレイヤーを定義します。
- HDF5_DATA-hdf5形式のデータレイヤー。
- IMAGE_DATAは、ファイルにクラスラベル付きの画像のリストが含まれていることを前提とする単純な形式です。
- その他。
変換は、レイヤーを使用して定義できます。
- INNER_PRODUCTは完全に接続されたレイヤーです。
- 畳み込み-畳み込み層。
- POOLING-空間結合レイヤー。
- ローカル応答正規化(LRN)-ローカル正規化のレイヤー。
これに加えて、変換の形成にさまざまなアクティベーション関数を使用できます。
- 正の部分(整流線形ユニット、ReLU)。
- シグモイド関数(SIGMOID)。
- 双曲線正接(TANH)。
- 絶対値(ABSVAL)。
- 絶滅(パワー)。
- 二項正規対数尤度関数(BNLL)。
ニューラルネットワークモデルの最後の層には、エラー関数が含まれている必要があります。 ライブラリには次の機能があります。
- 平均二乗誤差(MSE)。
- エッジエラー(ヒンジ損失)。
- ロジスティック損失関数。
- 情報ゲイン損失関数。
- シグモイドクロスエントロピー損失(シグモイドクロスエントロピー損失)。
- ソフトマックス機能。 シグモイドのクロスエントロピーをクラスの数が3つ以上の場合に一般化します。
モデルのトレーニングのプロセスでは、さまざまな最適化手法が使用されます。 Caffe開発者は、いくつかのメソッドの実装を提供します。
Caffeライブラリでは、prototxt形式の構成ファイルを使用して、ニューラルネットワークトポロジ、初期データ、およびトレーニング方法が設定されます。 このファイルには、入力データ(トレーニングとテスト)およびニューラルネットワークのレイヤーの説明が含まれています。 「ロジスティック回帰」ネットワークの例を使用して、このようなファイルを構築する段階を考えてみましょう( 図2 )。 さらに、ファイルはlinear_regression.prototxtと呼ばれ、examples / mnistディレクトリにあると仮定します。

図 2.ニューラルネットワークの構造
- ネットワーク名を設定します。
name: "LinearRegression"
- lmdb形式で保存されたMNISTデータベースは、トレーニングセットとして使用されます。 lmdbまたはleveldb形式を使用するには、「DATA」タイプのレイヤーを使用します。このレイヤーでは、入力データ(data_param)を記述するパラメーターを指定する必要があります。ハードディスク上のデータへのパス(ソース)、データタイプ(バックエンド)、サンプルサイズ(batch_size) データを使用してさまざまな変換(transform_param)を実行することもできます。 たとえば、すべての値に0.00390625(255の逆数)を掛けて、画像を正規化できます。 topパラメーターは、レイヤーの出力を識別するために使用される1つ以上の名前を指定します。 この例では、これらは処理された画像(データ)および画像が属するクラスラベル(ラベル)です。
layers { name: "mnist" type: DATA top: "data" top: "label" data_param { source: "examples/mnist/mnist_train_lmdb" backend: LMDB batch_size: 64 } transform_param { scale: 0.00390625 } }
- 完全に接続されたレイヤーを定義します(前のレイヤーの各ニューロンの出力は、後続のレイヤーの各ニューロンの入力に関連付けられます)。 Caffeライブラリの完全に接続されたレイヤーは、タイプINNER_PRODUCTのレイヤーを使用して定義されます。 入力名は、bottomパラメーターを使用して指定されます。 このレイヤーの入力データは処理された画像です。 レイヤー内のニューロンの数は(前のレイヤーの出力の数によって)自動的に決定され、出力ニューロンの数はnum_outputパラメーターを使用して示されます。 レイヤーの結果を、レイヤーの名前と同じ名前(ip)で配置します。
layers { name: "ip" type: INNER_PRODUCT bottom: "data" top: "ip" inner_product_param { num_output: 10 } }
- 最後に、エラー関数を計算するレイヤーを追加します。 以前の完全に接続されたレイヤー(ip)の結果と各画像のクラス番号(ラベル)の入力を受け取ります。 計算後、このレイヤーの結果は名前の損失によってアクセスできます。
layers { name: "loss" type: SOFTMAX_LOSS bottom: "ip" bottom: "label" top: "loss" }
ネットワーク構成の準備ができました。 次に、prototxt形式のファイルでトレーニング手順のパラメーターを決定する必要があります(solver.prototxtと呼びましょう)。 トレーニングパラメーターには、ネットワーク構成ファイルへのパス(net)、トレーニング中のテストの頻度(test_interval)、確率的勾配降下のパラメーター(base_lr、weight_decayなど)、最大反復回数(max_iter)、計算が実行されるアーキテクチャが含まれます。 (solver_mode)、トレーニング済みネットワークを保存するパス(snapshot_prefix)。
net: "examples/mnist/linear_regression.prototxt" test_iter: 100 test_interval: 500 base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005 lr_policy: "inv" gamma: 0.0001 power: 0.75 display: 100 max_iter: 10000 snapshot: 5000 snapshot_prefix: "examples/mnist/linear_regression" solver_mode: GPU
トレーニングは、メインライブラリアプリケーションを使用して実行されます。 この場合、特定のキーのセット、特にトレーニング手順のパラメーターの説明を含むファイルの名前が送信されます。
caffe train --solver=solver.prototxt
トレーニング後、結果のモデルを使用して、たとえばPythonラッパーを使用して画像を分類できます。
- Caffeライブラリーを接続します。 テストモードを設定し、計算を実行するためのアーキテクチャ(CPUまたはGPU)を指定します。
import caffe caffe.set_phase_test() caffe.set_mode_cpu()
- 次のパラメーターを指定して、ニューラルネットワークを作成します:MODEL_FILE-prototxt形式のネットワーク構成、PRETRAINED-caffemodel形式の訓練されたネットワーク、IMAGE_MEAN-平均画像(一連の入力画像から計算され、強度のその後の正規化に使用)、channel_swapはカラーモデルを設定し、raw_scale-最大強度値、image_dims-画像の解像度。 その後、分類用の画像(IMAGE_FILE)をロードします。
net = caffe.Classifier(MODEL_FILE, PRETRAINED, IMAGE_MEAN, channel_swap=(0,1,2), raw_scale=255, image_dims=(28, 28)) input_image = caffe.io.load_image(IMAGE_FILE)
- 選択した画像のニューラルネットワークの応答を取得し、結果を画面に表示します。
prediction = net.predict([input_image]) print 'prediction shape:', prediction[0].shape print 'predicted class:', prediction[0].argmax()
したがって、単純なアクションを通じて、ディープニューラルネットワークモデルを使用した実験の最初の結果を取得できます。 より複雑で詳細な例は、開発者のWebサイトで確認できます。
Pylearn2ライブラリ

Pylearn2は、2011年2月からモントリオール大学のLISAラボで開発されたライブラリです。 彼にはGitHubに約100人の開発者がいます 。 ライブラリは、BSD 3-Clauseの下でライセンスされています。
Pylearn2はPythonで実装され、現在Linuxオペレーティングシステムをサポートしていますが、仮想マシンを使用して任意のオペレーティングシステムで実行することもできます。 開発者は、Vagrantに基づいた仮想環境用にカスタマイズされたラッパーを提供します。 Pylearn2はTheanoライブラリのアドオンです。 さらに、PyYAML、PILが必要です。 計算を高速化するために、Pylearn2とTheanoはC ++ / CUDAで実装されるCuda-convnetを使用します。これにより、速度が大幅に向上します。
Pylearn2は、完全に接続された畳み込みニューラルネットワーク、さまざまなタイプの自動エンコーダー(収縮自動エンコーダー、ノイズ除去自動エンコーダー)、および限定されたボルツマンマシン(ガウスRBM、スパイクアンドスラブRBM)の作成をサポートします。 いくつかのエラー関数が提供されています:相互エントロピー(相互エントロピー)、対数尤度(対数尤度)。 以下の指導方法が利用可能です。
- バッチ勾配降下(BGD)。
- 確率的勾配降下(SGD)。
- 非線形共役勾配降下法(NCG)。
Pylearn2ライブラリでは、ニューラルネットワークは、YAML形式の設定ファイルの記述を使用して定義されます。 YAMLファイルは、オブジェクト指向プログラミング手法を使用して開発されているため、オブジェクトをシリアル化する便利で迅速な方法です。
ロジスティック回帰の例を使用して、ニューラルネットワークの構造とトレーニング方法を記述するYAMLファイルを生成する手順を検討してください。
- トレーニングセットを定義します。 Pylearn2には、MNISTデータベースを操作するためのクラスが既にあります。 最初の50,000個の画像でトレーニングします。
!obj:pylearn2.train.Train { dataset: &train !obj:pylearn2.datasets.mnist.MNIST { which_set: 'train', one_hot: 1, start: 0, stop: 50000 },
- ネットワーク構造について説明します。 このために、ロジスティック回帰を実装するクラスを使用します。 必要なパラメーターを指定するだけで十分です。 完全に接続されたレイヤー(nvis)の入力ニューロンの数は784(画像内のピクセルの数)、出力(n_classes)-10(オブジェクトのクラスの数)、初期重み(オレンジ)はゼロによって決定されます。
model: !obj:pylearn2.models.softmax_regression.SoftmaxRegression { n_classes: 10, irange: 0., nvis: 784, },
- ニューラルネットワーク学習アルゴリズムとそのパラメーターを選択します。 トレーニングには、バッチ勾配降下法(BGD)を選択します。 batch_sizeパラメーターは、勾配降下の各ステップで使用されるトレーニングサンプルのサイズを決定します。 line_search_modeを網羅的に設定すると、バッチ勾配降下(BGD)メソッドは、バイナリサーチを使用して勾配方向に沿って最適なポイントに到達しようとし、勾配降下の収束が高速化されます。 トレーニング中に、トレーニング、検証(50,000〜60,000の画像)およびテストサンプルの分類結果を追跡します。 停止基準-最適化反復の最大数。
algorithm: !obj:pylearn2.training_algorithms.bgd.BGD { batch_size: 128, line_search_mode: 'exhaustive', monitoring_dataset: { 'train' : *train, 'valid' : !obj:pylearn2.datasets.mnist.MNIST { which_set: 'train', one_hot: 1, start: 50000, stop: 60000 }, 'test' : !obj:pylearn2.datasets.mnist.MNIST { which_set: 'test', one_hot: 1, } }, termination_criterion: !obj:pylearn2.termination_criteria.And { criteria: [ !obj:pylearn2.termination_criteria.EpochCounter { max_epochs: 150 }, ] } },
- 訓練されたモデルをさらに使用するには、結果を保存する必要があります。 モデルはpkl形式で保存されることに注意してください。
extensions: [ !obj:pylearn2.train_extensions.best_params.MonitorBasedSaveBest { channel_name: 'valid_y_misclass', save_path: "%(save_path)s/softmax_regression_best.pkl" }, ]
したがって、ネットワーク構成が準備され、トレーニングと分類に必要なインフラストラクチャが決定されます。これは、適切なPythonスクリプトを呼び出すことによって実行されます。 トレーニングのために、次のコマンドラインを実行する必要があります。
python train.py < >.yaml
より複雑で詳細な例は、 公式Webサイトまたはリポジトリで見ることができます 。
ライブラリトーチ

Torchは、機械学習アルゴリズムを幅広くサポートする科学計算用のライブラリです。 2000年以来、 Idiap Research Institute 、 ニューヨーク大学 、 NEC Laboratories Americaによって開発され、BSDライセンスの下で配布されています。
ライブラリは、CおよびCUDAを使用してLuaに実装されます。 高速スクリプト言語LuaとSSE、OpenMP、CUDAテクノロジーの組み合わせにより、トーチは他のライブラリと比較して優れた速度を発揮できます。 現在サポートされているオペレーティングシステムはLinux、FreeBSD、Mac OS Xです。メインモジュールはWindowsでも動作します。 トーチの依存関係には、imagemagick、gnuplot、nodejs、npmなどが含まれます。
ライブラリは一連のモジュールで構成され、各モジュールはニューラルネットワークを操作するさまざまな段階を担当します。 したがって、たとえば、 nnモジュールはニューラルネットワークの構成(レイヤーとそのパラメーターの定義)を提供し、 optimモジュールにはトレーニングに使用されるさまざまな最適化手法の実装が含まれ、 gnuplotはデータを視覚化する機能(グラフ化、画像の表示など)を提供します。 追加のモジュールをインストールすると、ライブラリの機能を拡張できます。
Torchを使用すると、コンテナメカニズムを使用して複雑なニューラルネットワークを作成できます。 コンテナは、ニューラルネットワークの宣言されたコンポーネントを1つの一般的な構成に結合するクラスであり、後でトレーニング手順に転送できます。 ニューラルネットワークのコンポーネントは、完全に接続されたレイヤーまたは畳み込みレイヤーだけでなく、アクティベーション関数またはエラー、既製のコンテナーでもあります。 トーチを使用すると、次のレイヤーを作成できます。
- 完全に接続されたレイヤー(線形)。
- アクティベーション関数:双曲線正接(Tanh)、最小(Min)または最大(Max)の選択、softmax関数(SoftMax)など。
- 畳み込み層:畳み込み(畳み込み)、間引き(サブサンプリング)、空間結合(MaxPooling、AveragePooling、LPPooling)、差分正規化(SubtractiveNormalization)。
エラー関数:二乗平均平方根誤差(MSE)、クロスエントロピー(CrossEntropy)など
トレーニング中に、次の最適化方法を使用できます。
Torchでニューラルネットワークを構成するプロセスを検討します。 最初にコンテナを宣言し、次にレイヤーを追加する必要があります。 レイヤーを追加する順序は重要です (n-1)番目の層の出力は、n番目の入力になります。
regression = nn.Sequential() regression:add(nn.Linear(784,10)) regression:add(nn.SoftMax()) loss = nn.ClassNLLCriterion()
ニューラルネットワークの使用とトレーニング:
- X入力の読み込み。torch.load(path_to_ready_dset)関数を使用すると、準備されたデータセットをテキストまたはバイナリ形式で読み込むことができます。 通常、これは、サイズ、データ、ラベルの3つのフィールドで構成されるLuaテーブルです。 準備が整ったデータセットがない場合は、Lua言語の標準関数(たとえば、io.open(ファイル名[、モード]))またはトーチライブラリパッケージの関数(たとえば、image.loadJPG(ファイル名))を使用できます。
- 入力Xのネットワーク応答の定義:
Y = regression:forward(X)
- 誤差関数E =損失(Y、T)の計算、この場合、尤度関数です。
E = loss:forward(Y,T)
- バックプロパゲーションアルゴリズムによる勾配の誤計算。
dE_dY = loss:backward(Y,T) regression:backward(X,dE_dY)
それでは、すべてをまとめましょう。 Torchライブラリでニューラルネットワークをトレーニングするには、独自のトレーニングサイクルを作成する必要があります。 その中で、ネットワーク応答を計算し、エラーの大きさを決定し、勾配を再計算する特別な関数(クロージャー)を宣言し、このクロージャーを勾配降下関数に渡してネットワークの重みを更新します。
-- : w, dE_dw = regression:getParameters() local eval_E = function(w) dE_dw:zero() -- local Y = regression:forward(X) local E = loss:forward(Y,T) local dE_dY = loss:backward(Y,T) regression:backward(X,dE_dY) return E, dE_dw end -- optim.sgd(eval_E, w, optimState)
ここで、optimState-勾配降下パラメータ(learningRate、momentum、weightDecayなど)。 完全なトレーニングサイクルはこちらで確認できます 。
トレーニングプロシージャと同様に、宣言プロシージャのコードは10行未満であることがわかります。これは、ライブラリの使いやすさを示しています。 さらに、このライブラリを使用すると、ニューラルネットワークをかなり低いレベルで操作できます。
訓練されたネットワークの保存と読み込みは、特別な機能を使用して実行されます。
torch.save(path, regression) net = torch.load(path)
ダウンロード後、ネットワークを分類または追加のトレーニングに使用できます。 サンプル要素がどのクラスに属しているかを知る必要がある場合は、ネットワークを通過して出力を計算するだけです。
result = net:forward(sample)
より複雑な例は、ライブラリのトレーニング資料にあります 。
テアノ図書館

Theanoは、多次元配列を含む数式を効率的に計算できるPython言語の拡張機能です。 図書館は、古代ギリシャの哲学者で数学者のピタゴラス-フェアーノ(またはティーノ)の妻の名前にちなんでその名前を取得しました。 Theanoは、機械学習アルゴリズムの迅速な開発をサポートするためにLISAラボで開発されました。
ライブラリはPythonで実装され、Windows、Linux、およびMac OSのオペレーティングシステムでサポートされています。 Theanoには、Pythonで記述された数式を効率的なCまたはCUDAコードに変換するコンパイラーが含まれています。
Theanoは、ニューラルネットワークを構成およびトレーニングするための基本的なツールセットを提供します。 多層完全接続ネットワーク(多層パーセプトロン)、畳み込みニューラルネットワーク(CNN)、リカレントニューラルネットワーク(リカレントニューラルネットワーク、RNN)、自動エンコーダーおよび限定ボルツマンマシンの可能な実装。 さまざまな活性化機能、特にS字型、ソフトマックス機能、クロスエントロピーも提供されます。 トレーニングの過程で、バッチ勾配降下(バッチSGD)が使用されます。
Theanoのニューラルネットワーク構成を検討します。 便宜上、LogisticRegressionクラス( 図3 )を実装します。このクラスには、変数-トレーニングされたパラメーターW、b、およびそれらを操作するための関数-ネットワーク応答(y = softmax(Wx + b))およびエラー関数が含まれます。 次に、ニューラルネットワークをトレーニングするために、train_model関数を作成します。 そのためには、誤差関数を決定する方法、勾配を計算するルール、ニューラルネットワークの重みを変更する方法、ミニバッチサンプルのサイズと場所(画像自体とそれらの答え)を記述する必要があります。 すべてのパラメーターを決定した後、関数がコンパイルされ、トレーニングサイクルに転送されます。

図 3. Theanoでニューラルネットワークを実装するためのクラス図
クラスのソフトウェア実装
class LogisticRegression(object): def __init__(self, input, n_in, n_out): # y = W * x + b # , , self.W = theano.shared( # value=numpy.zeros((n_in, n_out), dtype=theano.config.floatX), name='W', borrow=True) self.b = theano.shared(value=numpy.zeros((n_out,), dtype=theano.config.floatX), name='b', borrow=True) # softmax, - y_pred self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b) self.y_pred = T.argmax(self.p_y_given_x, axis=1) self.params = [self.W, self.b] # def negative_log_likelihood(self, y): return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y]) # x - # (minibatch) x # y - x = T.matrix('x') y = T.ivector('y') # MNIST 28*28 classifier = LogisticRegression(input=x, n_in=28 * 28, n_out=10) # , cost = classifier.negative_log_likelihood(y) # , Theano - grad g_W = T.grad(cost=cost, wrt=classifier.W) g_b = T.grad(cost=cost, wrt=classifier.b) # updates = [(classifier.W, classifier.W - learning_rate * g_W), (classifier.b, classifier.b - learning_rate * g_b)] # , train_model = theano.function( inputs=[index], outputs=cost, updates=updates, givens={ x: train_set_x[index * batch_size: (index + 1) * batch_size], y: train_set_y[index * batch_size: (index + 1) * batch_size] } )
ニューラルネットワークのパラメーターをすばやく保存およびロードするには、cPickleパッケージの関数を使用できます。
import cPickle save_file = open('path', 'wb') cPickle.dump(classifier.W.get_value(borrow=True), save_file, -1) cPickle.dump(classifier.b.get_value(borrow=True), save_file, -1) save_file.close() file = open('path') classifier.W.set_value(cPickle.load(save_file), borrow=True) classifier.b.set_value(cPickle.load(save_file), borrow=True)
モデルを作成してそのパラメーターを決定するプロセスには、膨大でノイズの多いコードを書く必要があることは簡単にわかります。 ライブラリは低レベルです。 柔軟性に加えて、独自のコンポーネントを実装および使用する可能性があることに注意してください。 図書館の公式ウェブサイトには、さまざまなトピックに関する多数のトレーニング資料があります。
手書きの数字を分類するタスクの例に関するライブラリの比較
テストインフラストラクチャ
次のテストインフラストラクチャは、ライブラリのパフォーマンスを評価するための実験で使用されました。
- Ubuntu 12.04、Intel Core i5-3210M @ 2.5GHz(CPU実験)。
- Ubuntu 14.04、Intel Core i5-2430M @ 2.4GHz + NVIDIA GeForce GT 540M(GPU実験)。
- GCC 4.8、NVCC 6.5。
ネットワークトポロジと学習オプション
次の構造の完全に接続された畳み込みニューラルネットワークで計算実験が行われました。
- 3層の完全に接続されたニューラルネットワーク(MLP、 図4 ):
- 第1層-FC(in:784、out:392、有効化:tanh)。
- 2Dレイヤー-FC(in:392、out:196、activation:tanh)。
- 3Dレイヤー-FC(in:196、out:10、activation:softmax)。
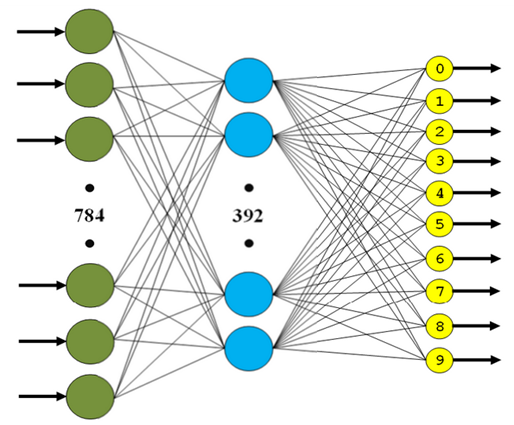
図 4.完全に接続された3層ネットワークの構造
- 畳み込みニューラルネットワーク(CNN、 図5 ):
- 1層目-畳み込み(入力フィルター:1、出力フィルター:28、サイズ:5x5、ストライド:1x1)。
- 2Dレイヤー-最大プーリング(サイズ:3x3、ストライド:3x3)。
- 3Dレイヤー-畳み込み(入力フィルター:28、出力フィルター:56、サイズ:5x5、ストライド1x1)。
- 4番目のレイヤー-最大プーリング(サイズ:2x2、ストライド:2x2)。
- 5番目のレイヤー-FC(in:224、out:200、activation:tanh)。
- 第6層-FC(in:200、out:10、アクティベーション:softmax)。
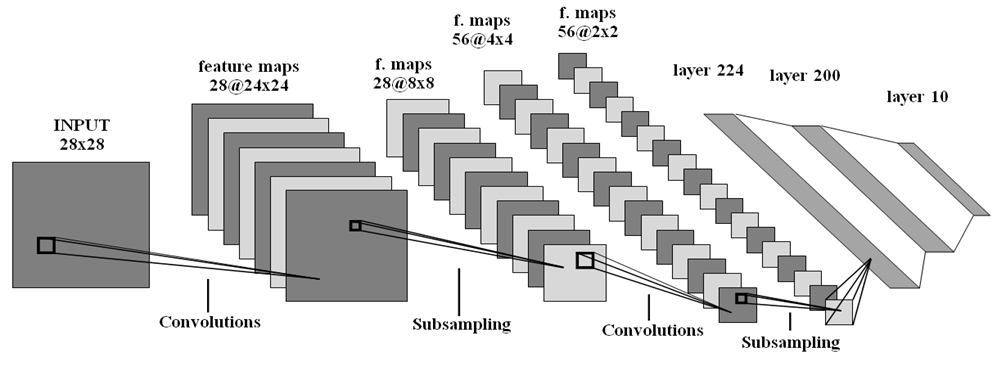
図 5.畳み込みニューラルネットワークの構造
すべての重みは、範囲(-6 /(n_in + n_out)、6 /(n_in + n_out))の均一分布則に従ってランダムに初期化されました。ここで、n_in、n_outは、それぞれレイヤーの入力と出力のニューロン数です。 確率的勾配降下(SGD)のパラメーターは、学習率-0.01、運動量-0.9、重量減衰-5e-4、バッチサイズ-128、最大反復数-150の値に等しく選択されました。
実験結果
調べた4つのライブラリを使用した、前述のニューラルネットワークのトレーニング時間( 図 4、5 )を以下に示します( 図6 )。 Pylearn2が他のライブラリと比較してパフォーマンスが低下していることは簡単にわかります(CPUとGPUの両方で)。 , . , CPU, Torch ( CNN , GPU). GPU- ( ) Caffe. Caffe .
CPU (. ):
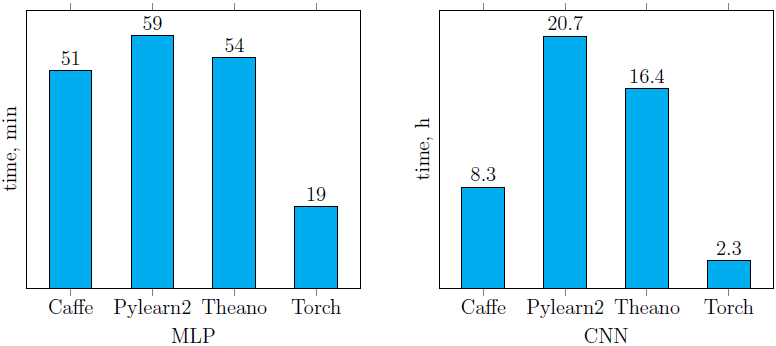
GPU (. ):
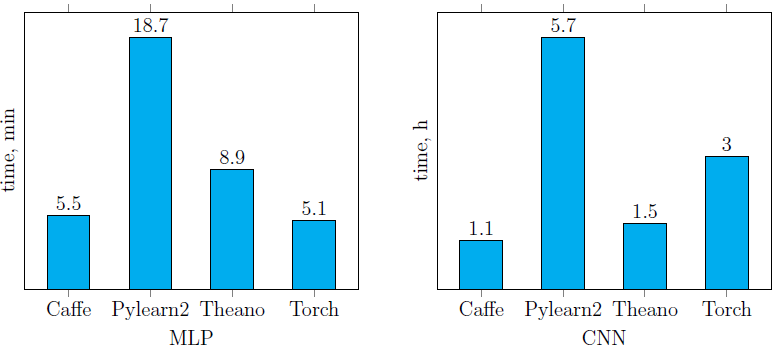
. 6. MLP CNN,
CPU ( . 7 ), , Torch . Caffe CNN, MLP.
CPU (. ):
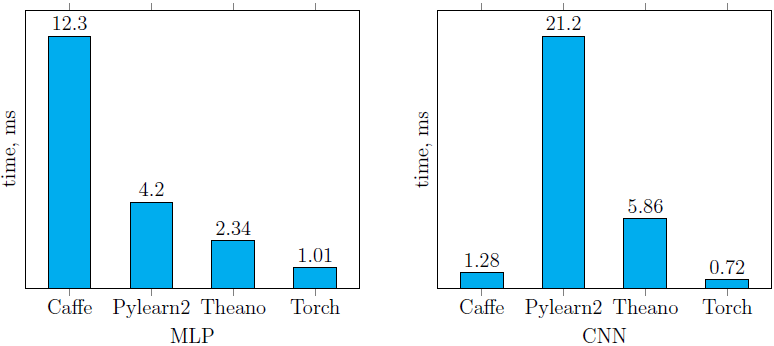
. 7. MLP CNN
, MLP 97.4%, CNN — ~99% ( 2 ). MNIST . , . , , .
2. 5
| Caffe | Pylearn2 | Theano | Torch | |||||
| , % | , % | , % | , % | |||||
| MLP | 98.26 | 0.0039 | 98.1 | 0 | 97.42 | 0.0023 | 98.19 | 0 |
| CNN | 99.1 | 0.0038 | 99.3 | 0 | 99.16 | 0.0132 | 99.4 | 0 |
, 1 3 :
- , .
- .
- — , , .
- , , .
- — ( , , , , ).
, , ( 3 ). Caffe ( . 6 ). . Theano . Pylearn2, ( YAML- ). Torch. , .
3. ( 1 3 )
| Caffe | 1 | 2 | 1 | 3 | 3 | 2 | 12 |
| Pylearn2 | 3 | 3 | 2 | 3 | 1 | 3 | 15 |
| Torch | 2 | 1 | 2 | 2 | 2 | 1 | 10 |
| Theano | 2 | 2 | 3 | 1 | 2 | 2 | 12 |
おわりに
, , Torch. Caffe Theano ( 3 ), . , Caffe Torch.
« » . .. Itseez.
- Kustikova, VD, Druzhkov, PN: A Survey of Deep Learning Methods and Software for Image Classification and Object Detection. In: Proc. of the 9th Open German-Russian Workshop on Pattern Recognition and Image Understanding. (2014)
- Hinton, GE: Learning Multiple Layers of Representation. In: Trends in Cognitive Sciences. Vol. 11. pp. 428-434. (2007)
- LeCun, Y., Kavukcuoglu, K., Farabet, C.: Convolutional networks and applications in vision. In: Proc. of the IEEE Int. Symposium on Circuits and Systems (ISCAS). pp. 253-256. (2010)
- Hayat, M., Bennamoun, M., An, S.: Learning Non-Linear Reconstruction Models for Image Set Classification. In: Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition. (2014)
- Restricted Boltzmann Machines (RBMs), www.deeplearning.net/tutorial/rbm.html .
- Bottou, L.: Stochastic Gradient Descent Tricks. Neural Networks: Tricks of the Trade, research.microsoft.com/pubs/192769/tricks-2012.pdf .
- Duchi, J., Hazan, E., Singer, Y.: Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. In: The Journal of Machine Learning Research. (2011)
- Sutskever, I., Martens, J., Dahl, G., Hinton, G.: On the Importance of Initialization and Momentum in Deep Learning. In: Proc. of the 30th Int. Conf. on Machine Learning. (2013)
- (ASGD), research.microsoft.com/pubs/192769/tricks-2012.pdf .
- ---, en.wikipedia.org/wiki/Limited-memory_BFGS .