
DOM L3 XPathとの互換性を提供する
Windows 10で真に互換性のある最新のWebプラットフォームを提供するというタスクを設定したので、特にDOM L3 XPathに関する標準のサポートの改善に常に取り組んでいます。 今日、Project Spartanでこれを達成した方法をお伝えしたいと思います。
ちょっとした歴史
IE9でDOM L3 Core標準およびネイティブXMLドキュメントのサポートを実装する前に、ActiveXエンジンを介してWeb開発者にMSXMLライブラリを提供しました。 XMLHttpRequestオブジェクトに加えて、MSXMLは独自のAPIであるselectSingleNodeおよびselectNodesを介して、XPathクエリ言語の部分的なサポートも提供しました。 MSXMLを使用するアプリケーションの観点から見ると、この方法はうまくいきました。 ただし、XMLとのやり取りやXPathの操作に関するW3C標準を完全には満たしていませんでした。
ライブラリ作成者とWebサイト開発者は、XPath呼び出しをラップして、オンザフライ実装を切り替える必要がありました。 チュートリアルやXPathの例をオンラインで検索すると、IEとMSXMLのラッパーがすぐにわかります。たとえば、
// code for IE if (window.ActiveXObject || xhttp.responseType == "msxml-document") { xml.setProperty("SelectionLanguage", "XPath"); nodes = xml.selectNodes(path); for (i = 0; i < nodes.length; i++) { document.write(nodes[i].childNodes[0].nodeValue); document.write("<br>"); } } // code for Chrome, Firefox, Opera, etc. else if (document.implementation && document.implementation.createDocument) { var nodes = xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null); var result = nodes.iterateNext(); while (result) { document.write(result.childNodes[0].nodeValue); document.write("<br>"); result = nodes.iterateNext(); } }
プラグインを使用しない新しいWebベースのエンジンでは、ネイティブXPathサポートを提供する必要がありました。
オプションの評価
そのようなサポートを翻訳するために利用可能なオプションの評価をすぐに始めました。 最初から作成することも、MSXMLブラウザーに完全に統合することも、.NETからSystem.XMLを移植することもできますが、これには時間がかかりすぎます。 したがって、完全なXPathについて考えながら、XPathの基本的なサブセットのサポートを実装することから始めることにしました。
標準の最初のサブセットを採用する価値があるかどうかを判断するために、数十万の最も人気のあるサイトからのリクエストに関する統計を収集する内部ツールを使用しました。 最も一般的なリクエストは次のタイプであることが判明しました。
- // element1 / element2 / element3
- //要素[@ attribute = "value"]
- .//* [含む(concat( ""、@ class、 "")、 "classname")]
これらはそれぞれ、すでにあるCSSセレクターAPIの非常に高速な実装にリダイレクトできるCSSセレクターに完全に対応しています。 自分で比較してください:
- element1> element2> element3
- 要素[属性= "値"]
- * .classname
したがって、XPathサポートを実装する最初のステップは、XPath要求からCSSセレクターへのコンバーターを作成し、呼び出しを適切な場所にリダイレクトすることでした。 これを行った後、テレメトリを再度使用して、成功したリクエストの割合を測定し、失敗したリクエストの中で最も頻繁に発生するものを見つけました。
そのような実装はリクエストの94%をカバーし、多くのサイトをすぐに獲得できることが判明しました。 失敗したのは、ほとんどが種でした
- //要素[含む(@ class、 "className")]
- //要素[含む(concat( ""、normalize-space(@ class)、 "")、 "className")]
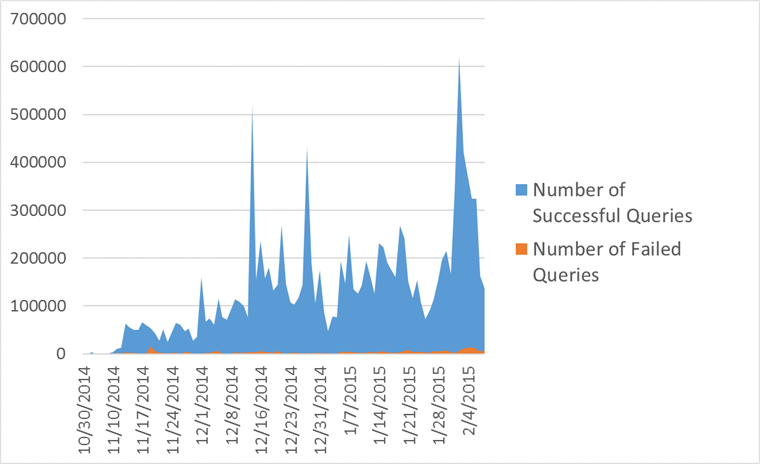
XPathクエリのテレメトリ実行結果
残りの3%のサイトに対するサポートの提供
CSSセレクターへの単純な変換で大部分のXPathクエリを維持することは問題ありませんが、残りのクエリを同様の方法で実装することはできないため、まだ十分ではありません。 XPath文法には、関数、非DOM要素のクエリ、ドキュメントノード、複雑な述語などの高度なものが含まれています。 そのような場合、一部の信頼できるサイト( MDNを含む)は、ポリフィルライブラリを使用するための適切なネイティブXPathサポートを持たないプラットフォームを提供します。
たとえば、純粋なJSで記述されたwicked-good-xpath (WGX)。 XPath仕様の内部テストスイートでテストし、ネイティブ実装と比較して、91%の互換性と非常にまともなパフォーマンスを示しました。 したがって、残りの3%のサイトにWGXを使用するというアイデアは、私たちにとって非常に魅力的であるように思えました。 さらに、これはMITライセンスの下でオープンソースコードを使用するプロジェクトであり、オープンソースビジネスへの貢献を増やすという私たちの意図と見事に組み合わされています。 ただし、IE内でJavaScriptポリフィルを使用してWeb標準のサポートを提供したことはありません。
ドキュメントコンテキストを損なうことなく、WGXが機能するようにするには、JSエンジンの独立した分離されたインスタンスで実行し、要求と必要なデータをページから入力に渡し、出力で完成した結果を取得します。 WGXコードを変更してドキュメントから「引き裂かれた」方法で動作するようにすることで、新しいブラウザーで多くのサイトのコンテンツの表示をすぐに改善しました。
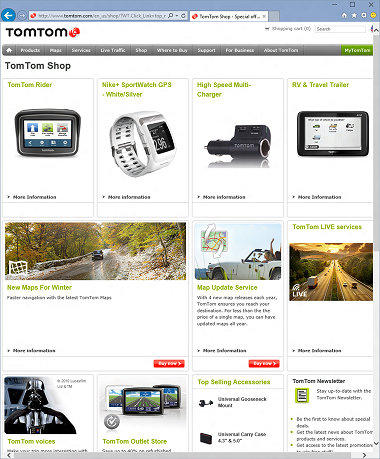

WGXを使用する前のサイト
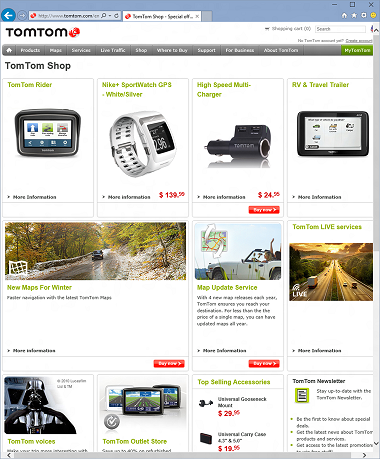

そして、これは後です。 チケットの価格と数に注意してください。
ただし、WG3には、W3C仕様と他のブラウザーの両方とは異なる動作を引き起こすバグがありました。 最初にそれらをすべて修正してから、コミュニティとパッチを共有する予定です。
したがって、Webでのデータマイニングの結果として、そしてオープンソースライブラリの助けを借りて、短時間で新しいエンジンが強力なXPathサポートを獲得し、ユーザーはすぐにWeb標準のより良いサポートを得るでしょう。 次のWindows 10 Technical Previewをダウンロードして、自分で確認できます。 UserVoiceを使用して、私たちがどれだけうまくやったか、 ツイートしたり、元の記事にコメントしたりすることもできます 。
翻訳者からのPS: JavaScriptがプラットフォームが書かれている言語になる傾向は明らかです。 FirefoxのShumway、またはPDF.jsを使用してください。 現在、Microsoftはブラウザの少なくとも一部をJSに翻訳しています。