最後の投稿へのコメントでは、非常に重要な質問が提起されました-CPUのみで実行する場合と比較して、統合グラフィックスに計算をアップロードすることにより、実際にパフォーマンスが向上しますか? もちろんそうなりますが、GFX + CPUで効率的なコンピューティングを行うには、特定のプログラミングルールに従う必要があります。
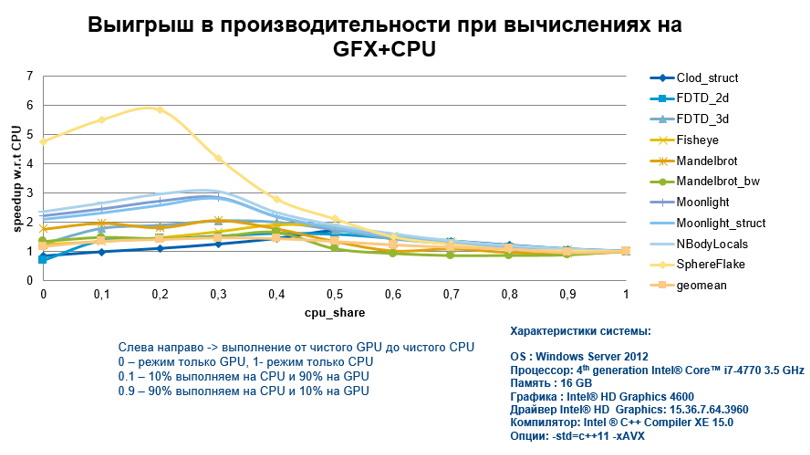
私の言葉を確認して、さまざまなアルゴリズムと異なるCPUの関与度で、統合されたグラフで計算を実行して得られた加速度のグラフをすぐに提示します。 KDPVでは、ゲインが非常に大きいことがわかります。
多くの人は、これらのアルゴリズムの種類と、そのような結果を得るためにこのコードで行ったアルゴリズムはまったく明確ではないと言うでしょう。
したがって、GFXで効率的に実行するために、このような印象的な結果を達成する方法を検討します。
まず、ハードウェア自体の詳細についての知識を考慮に入れて、すべての機能とメソッドをまとめてから、Intel Graphics Technologyを使用した特定の例を使用した実装に進みましょう。 それで、高いパフォーマンスを得るために何をすべきか:
- ネストされたcilk_forを使用するため、反復スペースが増加します。 その結果、同時実行のためのリソースが大きくなり、GPUで使用できるスレッドが増えます。
- コードをベクトル化する(はい、GPUではCPUと同じくらい重要です)オフラインにするには、pragma simdディレクティブまたはIntel®Cilk™Plus配列表記を使用します。
- コンパイラが異なるバージョンのコード(コードパス)を作成しないように、キーワード__restrict__および__assume_aligned()を使用します。 たとえば、アライメントされたメモリとアライメントされていないメモリを操作するための2つのバージョンを生成できます。これらはランタイムでチェックされ、実行は目的の「ブランチ」で行われます。
- プラグマオフロードディレクティブのピンを使用すると、DRAMとカードメモリ間でデータをコピーすることによるオーバーヘッドを回避でき、CPUとGPUに共有メモリを使用できることを忘れないでください。
- このサイズのギャザー/スキャッター操作ははるかに効率的であるため、1バイトまたは2バイトの要素よりも4バイトの要素を使用することをお勧めします。 1.2バイトの場合、はるかに遅くなります。
- さらに良いのは、収集/分散命令を避けることです。 これを行うには、AoS(構造の配列)の代わりにSoA(配列の構造)データ構造を使用します。 ここではすべてが非常に単純です-データを配列に保存する方がよい場合、メモリへのアクセスは一貫性があり効率的です。
- GFXの強みの1つは、各ストリーム用の4 KBのレジスタファイルです。 ローカル変数がこのサイズを超える場合、はるかに遅いメモリで作業する必要があります。
- レジスタファイル(GRF)で選択されたint buf [2048]配列を使用する場合、レジスタへのインデックス付きアクセスはfor(i = 0.2048){... buf [i] ...}の形式のループで実行されます。 直接アドレス指定を使用するには、pragma unrollディレクティブを使用してループの展開を行います。
それでは、すべての仕組みを見てみましょう。 マトリックス乗算の最も単純な例は取り上げませんでしたが、ベクトル化とキャッシュブロックの最適化にCilk Plus配列表記を使用して、少し修正しました。
私は正直にコードを変更し、パフォーマンスがどのように変化するかを見ることにしました。
void matmul_tiled(float A[][K], float B[][N], float C[][N]) { for (int m = 0; m < M; m += TILE_M) { // iterate tile rows in the result matrix for (int n = 0; n < N; n += TILE_N) { // iterate tile columns in the result matrix // (c) Allocate current tiles for each matrix: float atile[TILE_M][TILE_K], btile[TILE_N], ctile[TILE_M][TILE_N]; ctile[:][:] = 0.0; // initialize result tile for (int k = 0; k < K; k += TILE_K) { // calculate 'dot product' of the tiles atile[:][:] = A[m:TILE_M][k:TILE_K]; // cache atile in registers; for (int tk = 0; tk < TILE_K; tk++) { // multiply the tiles btile[:] = B[k + tk][n:TILE_N]; // cache a row of matrix B tile for (int tm = 0; tm < TILE_M; tm++) { // do the multiply-add ctile[tm][:] += atile[tm][tk] * btile[:]; } } } C[m:TILE_M][n:TILE_N] = ctile[:][:]; // write the calculated tile to back memory } } }
行列を使用したブロック処理を伴うこのようなアルゴリズムの利点は理解できます-キャッシュの問題を回避しようとしているため、TILE_N、TILE_M、TILE_Kのサイズを変更します。 最適化と、MとKのサイズが2048、N-4096に等しいインテルコンパイラーでこの例を収集し、アプリケーションを起動します。 レンダリング時間は5.12秒です。 この場合、Cilk(およびSSEのデフォルト命令セット)によるベクトル化のみを使用しました。 タスクに並列処理を実装する必要があります。 これにはcilk_forを使用できます。
cilk_for(int m = 0; m < M; m += TILE_M) ...
コードを再構築し、再度実行します。 予想通り、ほぼ直線的な加速が得られます。 2つのコアプロセッサを搭載したシステムでは、時間は2.689秒でした。 スケジュールでオフロードを有効にし、パフォーマンスで何が勝つことができるかを見てみましょう。 そのため、プラグマオフロードディレクティブを使用して、ネストされたcilk_forループを追加すると、次のようになります。
#pragma offload target(gfx) pin(A:length(M)) pin(B:length(K)) pin(C:length(M)) cilk_for(int m = 0; m < M; m += TILE_M) { cilk_for(int n = 0; n < N; n += TILE_N) { ...
オフロードを伴うアプリケーションは0.439秒かかりましたが、これはかなり良いです。 私の場合、展開サイクルによる追加の変更では、パフォーマンスの大幅な向上は見られませんでした。 しかし、重要な役割はマトリックスアルゴリズムによって果たされました。 サイズTILE_MおよびTILE_Kは16、TILE_Nは32に選択されました。したがって、sizeof(atile)は1 KB、sizeof(btile)は128 B、sizeof(ctile)は2 KBでした。 私がこれをすべて行った理由は明らかだと思います。 そうです、1 KB + 2 KB + 128 Bの合計サイズは4 KB未満であることが判明しました。これは、GFXの各スレッドで使用可能な最速のメモリ(レジスタファイル)で作業したことを意味します。
ちなみに、通常のアルゴリズムははるかに長く機能しました(約1.6秒)。
実験のために、AVX命令の生成と、CPUでの最大4.098秒の加速実行、およびタスク用のCilk付きバージョン-最大1.784の生成をオンにしました。 それでも、生産性を大幅に向上させたのはGFXのオフロードでした。
私はあまり怠けていなかったので、VTune Amplfier XEが同様のアプリケーションでプロファイルできるものを確認することにしました。
デバッグ情報を含むコードを収集し、「GPUの使用状況を分析する」チェックマークを付けて基本的なホットスポット分析を開始しました。

興味深いことに、OpenCLには別のオプションがあります。 プロファイルを収集してVtuneタブを登ったところ、次の情報が見つかりました。
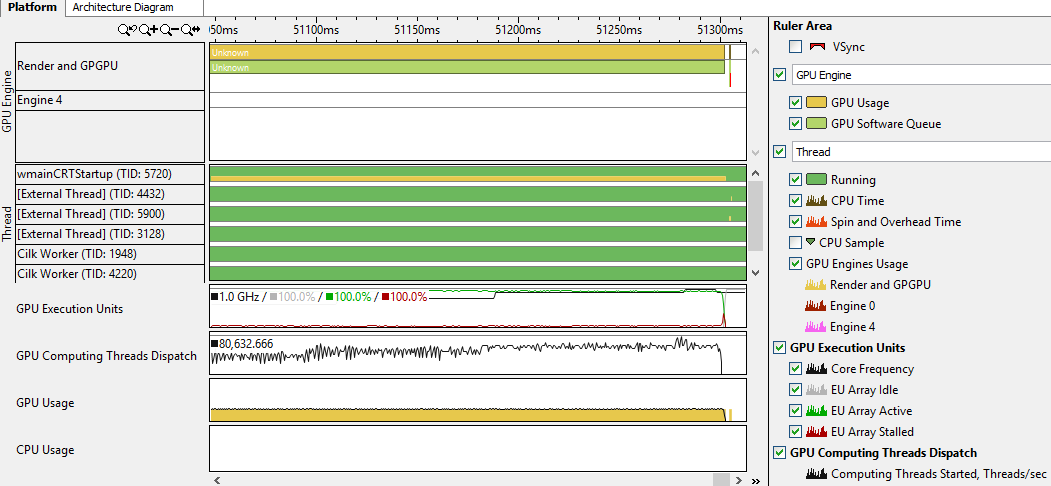
私はこれから多くを学んだとは言えません。 それでも、アプリケーションがGPUを使用していることを確認し、タイムライン上でオフラインが開始された瞬間に気付きました。 さらに、グラフ(EU GPU)ですべてのコアが時間の経過とともにどれだけ効果的に使用されているか(パーセント)を判断し、一般にGPUの使用を評価することができます。 必要であれば、特にコードがあなたによって書かれていない場合は、ここでもっと掘り下げる価値があると思います。 同僚は、GPUを使用する際にVTuneで多くの有用なものを見つけることができることを保証しました。
最後に、プロセッサの統合グラフィックスでオフロードを使用することで得られるメリットがあることを説明する価値があります。これは、特定のコード要件に従って、非常に重要です。