そもそも、ラジオで広告を認識する必要があるのは誰ですか? これは、コマーシャルの実際の出力を追跡し、トリミングや中断のケースをキャッチできる広告主にとって便利です。 ラジオ局は、地域などでのネットワーク広告の出力を監視できます。 音楽作品の再生を追跡したい場合(著作権所有者が本当に気に入っている場合)、または小さな断片から歌を学習したい場合(Shazamや他の同様のサービスのように)同じ認識タスクが発生します。
タスクはより厳密に次のように定式化されます。特定のセットの参照オーディオフラグメント(曲またはコマーシャル)があり、これらのフラグメントの一部がおそらくサウンドである空気のオーディオレコーディングがあります。 タスクは、再生されたすべてのフラグメントを検索し、再生の開始と継続時間を決定することです。 放送時間の記録を分析する場合、システム全体がリアルタイムよりも高速である必要があります。
仕組み
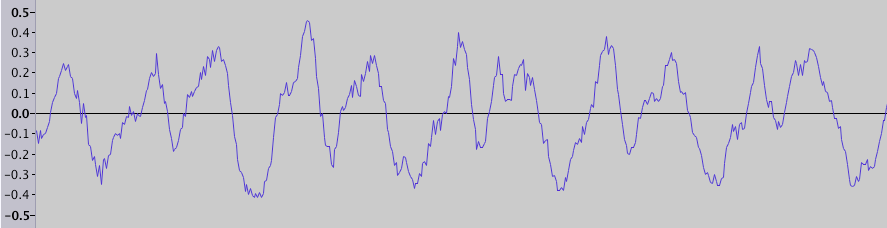
音は(狭い意味で)空中を伝播する圧縮と希薄化の波であることを誰もが知っています。 たとえば、wavファイルなどの録音は、一連の振幅値です(物理的には圧縮比または圧力に対応します)。 オーディオエディターを開いた場合、おそらくこのデータの視覚化が見られます-振幅対時間のグラフ(フラグメント期間0.025秒):
しかし、これらの周波数変動は直接知覚されませんが、異なる周波数と音色の音が聞こえます。 そのため、音を視覚化する別の方法がよく使用されます。 スペクトログラムでは、時間が水平軸に、周波数が垂直軸に、ドットの色が振幅を示します。 たとえば、バイオリンの音のスペクトログラムは次のとおりです。
個々の音とその倍音、ノイズだけでなく、周波数範囲全体をカバーする縦縞が表示されます。
Pythonを使用してこのようなスペクトログラムを作成するには、次のようにします。
SciPyライブラリを使用してwavファイルからデータをロードし、 matplotlibを使用してスペクトログラムを作成できます。 すべての例はPythonバージョン2.7で提供されていますが、おそらくバージョン3でも動作するはずです。 file.wavには、サンプリング周波数8000 Hzの録音が含まれていると想定しています。
import numpy from matplotlib import pyplot, mlab import scipy.io.wavfile from collections import defaultdict SAMPLE_RATE = 8000 # Hz WINDOW_SIZE = 2048 # , fft WINDOW_STEP = 512 # def get_wave_data(wave_filename): sample_rate, wave_data = scipy.io.wavfile.read(wave_filename) assert sample_rate == SAMPLE_RATE, sample_rate if isinstance(wave_data[0], numpy.ndarray): # wave_data = wave_data.mean(1) return wave_data def show_specgram(wave_data): fig = pyplot.figure() ax = fig.add_axes((0.1, 0.1, 0.8, 0.8)) ax.specgram(wave_data, NFFT=WINDOW_SIZE, noverlap=WINDOW_SIZE - WINDOW_STEP, Fs=SAMPLE_RATE) pyplot.show() wave_data = get_wave_data('file.wav') show_specgram(wave_data)
空中でフラグメントを検索するタスクは、2つの部分に分けることができます:最初に、多数の参照フラグメントの中から候補を見つけ、次に候補が実際にこの空気のフラグメントで聞こえるかどうかを確認し、そうであれば、どの時点でサウンドが開始および終了しますか? どちらの操作も、サウンドフラグメントの「インプリント」を使用して作業します。 ノイズに強く、十分にコンパクトでなければなりません。 このインプリントは次のように構成されています:スペクトログラムを時間の短いセグメントに分割し、各セグメントで最大振幅の周波数を探します(実際には、異なる範囲でいくつかの最大値を探す方が良いですが、簡単にするために最も意味のある範囲で最大値を1つ取ります)。 このような周波数(または周波数インデックス)のセットはインプリントです。 これらは時間のあらゆる瞬間に聞こえる「ノート」であると言うのは非常に失礼です。
サウンドインプリントを取得する方法は次のとおりです。
def get_fingerprint(wave_data): # pxx[freq_idx][t] - pxx, _, _ = mlab.specgram(wave_data, NFFT=WINDOW_SIZE, noverlap=WINDOW_OVERLAP, Fs=SAMPLE_RATE) band = pxx[15:250] # 60 1000 Hz return numpy.argmax(band.transpose(), 1) # max print get_fingerprint(wave_data)
エーテルフラグメントとすべての参照フラグメントの痕跡を取得できます。候補をすばやく検索し、フラグメントを比較する方法を学習する必要があります。 まず、比較の問題を見てみましょう。 ノイズと歪みのために、印刷物が正確に一致しないことは明らかです。 しかし、このように粗くされた周波数は、すべての歪みに非常によく耐えることがわかり(周波数はほとんど「泳ぐ」ことはありません)、周波数の十分に大きな割合が正確に一致します。 これを視覚化する簡単な方法は、最初に周波数が一致するポイントのすべてのペアを見つけてから、一致するポイント間の時間差のヒストグラムを作成することです。 2つのフラグメントに共通の領域がある場合、ヒストグラムには顕著なピークがあります(ピークの位置は一致するフラグメントの開始時間を示します)。
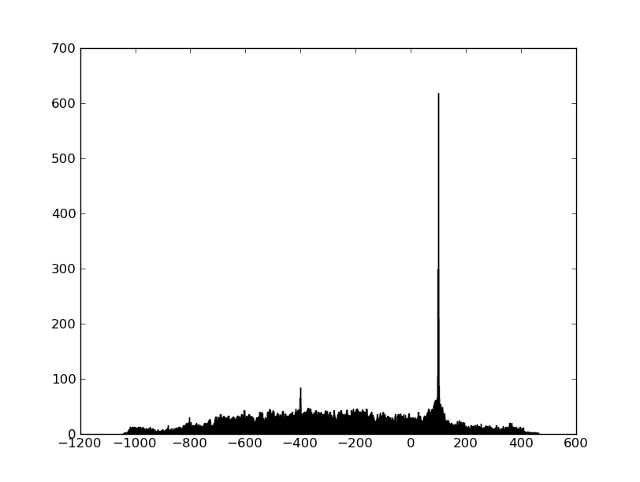
2つのフラグメントが何らかの方法で接続されていない場合、ピークはありません。
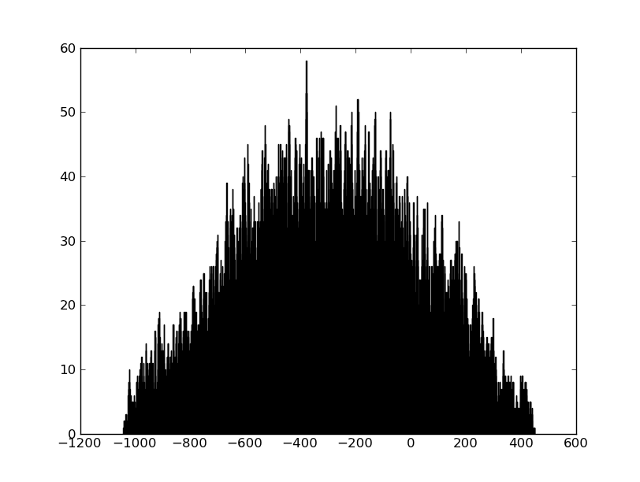
このような素晴らしいヒストグラムを作成できます:
認識を練習できるファイルはここで機能します 。
def compare_fingerprints(base_fp, fp): base_fp_hash = defaultdict(list) for time_index, freq_index in enumerate(base_fp): base_fp_hash[freq_index].append(time_index) matches = [t - time_index # for time_index, freq_index in enumerate(fp) for t in base_fp_hash[freq_index]] pyplot.clf() pyplot.hist(matches, 1000) pyplot.show()
認識を練習できるファイルはここで機能します 。
候補の検索の問題は通常、ハッシュを使用して解決されます。ハッシュの数は、通常、フラグメントのフィンガープリントから構築されます。これらは、原則として、フィンガープリントからのいくつかの値です。 さまざまなアプローチは、記事の最後にあるリンクで見ることができます。 私たちの場合、参照フラグメントの数は数百のオーダーであり、候補を選択する段階なしで行うことが可能でした。
結果
これらのレコードでは、 Fスコアは98.5%であり、開始を決定する精度は約1秒でした。 予想どおり、ほとんどのエラーは短い(4〜5秒)クリップにありました。 しかし、私にとっての主な結論は、そのようなタスクでは、独立して書かれたソリューションが既製のものよりもよく機能することが多いということです(たとえば、EchoPrint、Habréですでに書いた、短いクリップのために50-70%以下を絞ることができました)すべてのタスクとデータには独自の仕様があり、アルゴリズムに多くのバリエーションがあり、パラメーターの選択にgreat意性がある場合、作業のすべての段階を理解し、実際のデータを視覚化することは、良い結果に大きく貢献します。
楽しい事実:
参照: