" "
という文字列を例として引用しました。 FindBugsがInteger.MIN_VALUEに等しいハッシュコードの絶対値を計算する際の問題について警告すると、
"DESIGNING WORKHOUSES"
または
"DESIGNING WORKHOUSES"
などのハッシュコードを持つ文字列の例を提供します。 これらの例はどこから来たのですか? 与えられたハッシュコードで美しい行を自分で作る方法は?
2 32の異なるハッシュコードがあります-40億強、人間の言語で約10万語です。 目的のハッシュコードで1つの単語を見つけることはほとんど不可能ですが、2つの単語の組み合わせは非常に可能です。 前置詞などのバリエーションを追加すると、選択肢が表示されます。
考えられるすべての組み合わせを長時間繰り返しますが、文字列のハッシュコード式に対して単純な変換を実行することでプロセスを最適化できます。 与えられたハッシュコードでフレーズジェネレーターを書きましょう。 ファッショナブルな機能スタイルで、純粋なJava 8で記述します。
したがって、文字列sからのハッシュコード式hは、 l(s)がその長さであり、 s [i]はi番目の文字です。
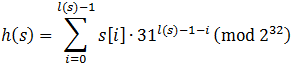
整数のオーバーフローは一般的なことなので、計算は2 32を法として行われます。 既知のハッシュコードを持つ2つの行s 1とs 2がある場合、これらの行を連結するためのハッシュコードは
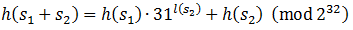
ここで、アルゴリズムは既に始まっています。 特定のハッシュコードを2つの部分に分けて文字列を作成する場合、2番目の部分を選択して、ハッシュコードを目的のサイズに補完できます。 2番目のパートで考えられるすべての長さを調べる必要がありますが、すべてのペアをソートするよりもはるかに高速です。
次の形式でフレーズを生成します。
"<___> [</>] <___>"
前後にスペースがある前置詞、またはスペースだけが前置詞と呼ばれます。 最初の単語はs 1で、中置詞と2番目の単語はs 2になります。 単語のベース、たとえばここ (litf-win.txtファイル)を見てください。 ファイルは次のようになります。
21715 2 1 1 2 1 7 ...
この数は私たちの興味を引くものではなく、切り捨てます。 さらに、3文字より短い単語をスローします。
List<String> words = Files.readAllLines(Paths.get("litf-win.txt"), Charset.forName("cp1251")).stream() .map(s -> s.substring(0, s.indexOf(' '))) .filter(s -> s.length() > 2) .collect(Collectors.toList());
前置詞を手動で入力します。
String[] preps = { "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "" };
中置記号のリストを作成します。前置詞と別のスペースの周りにスペースを追加します。
List<String> infixes = Stream.concat(Stream.of(" "), Arrays.stream(preps).map(p -> ' '+p+' ')) .collect(Collectors.toList());
インフィックスと単語のさまざまな組み合わせのストリームを作成します(行s 2 ):
words.stream().flatMap(s -> infixes.stream().map((String infix) -> infix+s))
次に、このストリームから連想配列を作成します(文字列の長さ->(ハッシュコード->文字列))。 Java 8では、これは以前のバージョンよりもはるかに簡単です。
Map<Integer, Map<Integer, List<String>>> lenHashSuffix = words.stream() .flatMap(s -> infixes.stream().map((String infix) -> infix+s)) .collect(Collectors.groupingBy(String::length, Collectors.groupingBy(String::hashCode)));
s 1のストリームを作成してみましょう-大文字(alas、このための既製の方法はまだありません):
words.stream().map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1))
s 1をすべてのs 2オプションと一致させるには、
flatMap
を使用できます。
lenHashSuffix
すべての長さをソートし、 s 2の適切なハッシュコードを計算し、このハッシュコードで行を抽出することは残っています。 これは疑問を提起します:与えられた長さlenに対してh ( s 1 )・31 lenを計算する方法は?
Math.pow
メソッドは機能しません。小数で機能します。
for
ループを記述することは可能ですが、これは最新ではありません! 幸いなことに、私たちは削減しました!
int hash = IntStream.range(0, len).reduce(s.hashCode(), (a, i) -> a*31);
ターゲットごとのターゲットハッシュコードを示します。 次に、
lenHashSuffix
からの各エントリ
entry
lenHashSuffix
次のようにs 2行のストリームを取得できます。
entry.getValue().getOrDefault( target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31), Collections.emptyList()).stream()
s 1とs 2を接着し、アルファベット順にソートしてコンソールに表示します。
words.stream() .map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1)) .flatMap(s -> lenHashSuffix.entrySet().stream() .flatMap(entry -> entry.getValue().getOrDefault( target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31), Collections.emptyList()).stream().map(suffix -> s+suffix))) .sorted().forEach(System.out::println);
それがプログラム全体です。
完全なソース
import java.nio.charset.Charset; import java.nio.file.*; import java.util.*; import java.util.stream.*; public class PhraseHashCode { public static void main(String[] args) throws Exception { int target = Integer.MIN_VALUE; String[] preps = { "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "" }; List<String> infixes = Stream.concat(Stream.of(" "), Arrays.stream(preps).map(p -> ' '+p+' ')) .collect(Collectors.toList()); List<String> words = Files.readAllLines(Paths.get("litf-win.txt"), Charset.forName("cp1251")).stream() .map(s -> s.substring(0, s.indexOf(' '))) .filter(s -> s.length() > 2) .collect(Collectors.toList()); Map<Integer, Map<Integer, List<String>>> lenHashSuffix = words.stream() .flatMap(s -> infixes.stream().map((String infix) -> infix+s)) .collect(Collectors.groupingBy(String::length, Collectors.groupingBy(String::hashCode))); words.stream() .map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1)) .flatMap(s -> lenHashSuffix.entrySet().stream() .flatMap(entry -> entry.getValue().getOrDefault( target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31), Collections.emptyList()).stream().map(suffix -> s+suffix))) .sorted().forEach(System.out::println); } }
結果
プログラムは10秒で解決し、100を超えるオプションを生成します。 もちろん、それらのほとんどは文法的に一貫していないか、ただ退屈ではありません。 しかし、良いことにも出くわします。
そのため、特定の行のハッシュコードが毎回再計算されるというレポートを作成する場合は、次の例(target = 0)で説明できます。
" " " " " " " " " " " "
ハッシュコードから
Math.abs
を計算することが有害である理由を同僚に伝える場合、次の行(target = Integer.MIN_VALUE)が
Math.abs
ます。
" " " " " " " " " "
ターゲット値を変更することにより、他のハッシュコードのフレーズを生成できます。