 比較的最近の記事は「純粋なCでの単体テストの半自動登録」で、著者はBoostのカウンターを使用して問題の解決策を示しました。 同じ原則に従って、CプロジェクトでのBoost依存関係の不整合の理由から、Boostを使用せずに、このような少量でさえ、この経験を既に繰り返す(成功した)試みがなされました。 同時に、テストには多数の補助プリプロセッサディレクティブが含まれていました。 そして、すべてが残っていましたが、ほぼ最終段階で、追加のアクションを完全に取り除くことができる代替の登録方法が見つかりました。 これは、C89テスト登録ソリューションであり、テストスイートを登録するためのもう少し厳しいビルドソリューションです。
比較的最近の記事は「純粋なCでの単体テストの半自動登録」で、著者はBoostのカウンターを使用して問題の解決策を示しました。 同じ原則に従って、CプロジェクトでのBoost依存関係の不整合の理由から、Boostを使用せずに、このような少量でさえ、この経験を既に繰り返す(成功した)試みがなされました。 同時に、テストには多数の補助プリプロセッサディレクティブが含まれていました。 そして、すべてが残っていましたが、ほぼ最終段階で、追加のアクションを完全に取り除くことができる代替の登録方法が見つかりました。 これは、C89テスト登録ソリューションであり、テストスイートを登録するためのもう少し厳しいビルドソリューションです。
このすべての動機はシンプルで簡単ですが、完全を期すために簡単に概説する価値があります。 自動登録がない場合、繰り返しコードの入力/挿入、またはコンパイラ外部のジェネレーターのいずれかを処理する必要があります。 1つ目は実行に消極的であり、このアクティビティ自体はエラーが発生しやすく、2つ目は不要な依存関係を追加し、アセンブリプロセスを複雑にします。 この機会のためだけにテストでC ++を使用するというアイデアは、他のすべてがCで書かれている場合、スズメの大砲からの射撃の感覚を呼び起こします。 このすべてに対して、原則として、問題が発生したのと同じレベルで問題を解決することは興味深いです。
最終目標は、以下のコードに似たものとして定義されますが、テスト名は定義された場所を除いてどこにも繰り返されないという追加条件があります。 それらは一度だけダイヤルされ、オシレーターによってそれ以上コピーされません。
TEST(test1) { /* Do the test. */ } TEST(test2) { /* Do the test. */ }
用語を明確にするための短い余談の後、解決策の検索を開始できます。
用語とテスト構造案
さまざまなテストフレームワークは、個々のテストまたはそのグループを指すために一貫性のない単語を使用しています。 したがって、いくつかの単語を明示的に定義すると同時に、かなり一般的なテスト構造の例でそれらの意味を示します。
テストのコレクション (「スイート」)は、テストスイートのグループ(「フィクスチャ」)を意味します 。 これは、階層の最大の構造単位です。 コレクション内のグループテストを順番に設定します。 テストはすでに独力で行われています。 各タイプの要素の数は任意です。
これはグラフィカルです:
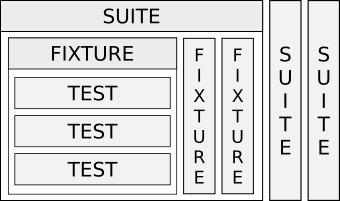
各上位レベルは、より小さな要素を組み合わせ、オプションでテストの準備(「セットアップ」)および完了(「ティアダウン」)の手順を追加します。
セットでのテストの登録
あなたの道徳観があなたに正しいことをすることを妨げさせないでください。
-ISAAC ASIMOV 財団
個別のテストは、セット全体よりも頻繁に追加されるため、自動登録はより関連性があります。 また、それらはすべて1つの翻訳単位内にあるため、問題の解決が簡単になります。
そのため、メイン制御要素としてプリプロセッサを使用せずに、言語を使用してテストのリストのリポジトリを整理する必要があります。 プリプロセッサを拒否すると、明示的なカウンターがなくなります。 ただし、テストを一意に識別し、一般に、単に通知するだけでなく、何らかの方法でそれらにアクセスする必要がある場合は、カウンターの存在がほぼ必要です。 同時に、組み込みの
__LINE__
マクロは常に
__LINE__
にありますが、この状況でどのように適用できるかを理解する必要
__LINE__
ます。 もう1つの制限があります:グローバル配列の要素へのいくつかの明示的な割り当て
test_type tests[]; static void test(void) { /* Do the test. */ } tests[__LINE__] = &test;
これらの関数は、関数の外部では言語レベルでサポートされていないため、適切ではありません。 最初の状況はあまりバラ色に見えません:
- 中間状態または最終状態を保存する方法はありません。
- 切断された要素を特定し、それらをまとめる方法はありません。
- その結果、前のエンティティを参照できないため、接続された構造(基本的には配列ですが、リストにもあります)を定義する方法はありません。
しかし、すべてが見た目ほど絶望的というわけではありません。 欠けているものがあるかのように、完璧なオプションを想像してください。 この場合、補助マクロを展開した後のコードは次のようになります。
MagicDataStructure MDS; static void test1(void) { /* Do the test. */ } MDS[__LINE__] = &test1; static void test2(void) { /* Do the test. */ } MDS[__LINE__] = &test2; static void fixture(void) { int i; for (i = 0; i < MDS.length; ++i) { MDS.func[i](); } }
事は小さいです:ところで、あらかじめ決められたサイズの配列に疑わしく似ている「魔法の」構造を実装すること。 この配列が実際にどのように機能するかを考えるのは理にかなっています:
- すべての
NULL
要素を初期化して配列を定義しNULL
。 - 個々の要素に値を割り当てます。
- 配列全体を調べて、すべての非
NULL
要素を呼び出しNULL
。
この一連の操作は必要なものすべてであり、あまり現実的ではないように見えます。おそらく配列はここで本当に役立つでしょう。 定義では、配列は同じ型の要素のコレクションです。 通常、これはインデックス作成操作をサポートするエンティティの1つですが、同じ配列を個別の要素のグループと見なすことは理にかなっています。 かどうかを言ってみましょう
int arr[4];
どちらか
int arr0, arr1, arr2, arr3;
現時点では、上記の
__LINE__
マクロの言及に照らして、著者がどこで
__LINE__
ているかはすでに明確になっているはずです。 コンパイル段階での割り当てをサポートする疑似配列を実装する方法を理解することは残っています。 これは楽しいエクササイズのように思えるので、既成のソリューションを示して次の質問をするのにもう少し時間をかける価値があります。
- Cのどのエンティティが複数回表示され、コンパイルエラーを引き起こさないか?
- コンパイラは、コンテキストに応じて異なる解釈を行うことができますか?
ヘッダーファイルを考えてください。 結局のところ、それらの中にあるものは通常、コードのどこか他の場所に存在します。 例:
/* file.h */ int a; /* file.c */ #include "file.h" int a = 4; /* ... */
この場合、すべてが正常に機能します。 タスクに近い例を次に示します。
static void run(void); int main(int argc, char *argv[]) { run(); return 0; } static void run(void) { /* ... */ }
これはごく普通のコードで、目的の機能を取得するためにわずかに拡張できます。
#include <stdio.h> static void (*run_func)(void); int main(int argc, char *argv[]) { if (run_func) run_func(); return 0; } static void run(void) { puts("Run!"); } static void (*run_func)(void) = &run;
読者は、
run_func
の最後の言及に対する順序の変更またはコメントが期待と一致していること、つまり、
run_func
ない場合、「1要素配列」(
run_func
)の唯一の要素は
NULL
。それ以外の場合は、
run()
関数を指します。 順序に依存しないことは、ヘッダーファイルのすべての「魔法」を隠すことができる重要なプロパティです。
上記の例から、関数を宣言し、マクロ値
__LINE__
を使用して番号付けされた変数に関数へのポインターを格納する自動登録用のマクロを作成するのは簡単です。 マクロ自体に加えて、ポインター変数の可能な名前をすべてリストし、一度に1つずつ呼び出す必要があります。 これはほとんど完全なソリューションで、ヘッダーファイルに非表示にする必要がある「余分な」コードの存在をカウントしませんが、詳細は次のとおりです。
/* test.h */ #define CAT(X, Y) CAT_(X, Y) #define CAT_(X, Y) X##Y typedef void test_func_type(void); #define TEST(name) \ static test_func_type CAT(name, __LINE__); \ static test_func_type *CAT(test_at_, __LINE__) = &CAT(name, __LINE__); \ static void CAT(name, __LINE__)(void) /* test.c */ #include "test.h" #include <stdio.h> TEST(A) { puts("Test1"); } TEST(B) { puts("Test2"); } TEST(C) { puts("Test3"); } typedef test_func_type *test_func_pointer; static test_func_pointer test_at_1, test_at_2, test_at_3, test_at_4, test_at_5, test_at_6; int main(int argc, char *argv[]) { /* , * . */ if (test_at_1) test_at_1(); if (test_at_2) test_at_2(); if (test_at_3) test_at_3(); if (test_at_4) test_at_4(); if (test_at_5) test_at_5(); if (test_at_6) test_at_6(); return 0; }
明確にするために、マクロ置換の結果を見ると便利な場合があります。これは、複数のテストを連続して配置することは不可能ですが、許容範囲を超えているという事実を意味します。
static test_func_type A4; static test_func_type *test_at_4 = &A4; static void A4(void) { puts("Test1"); } static test_func_type B5; static test_func_type *test_at_5 = &B5; static void B5(void) { puts("Test2"); } static test_func_type C6; static test_func_type *test_at_6 = &C6; static void C6(void) { puts("Test3"); }
完全な実装へのリンクを以下に示します。
なぜ機能するのか
ここで、ここで何が起こっているかをより詳細に把握し、なぜこれが機能するのかという質問に答えるときが来ました。
ヘッダーを使用して例を思い出すと、コード内でデータメンバーをどのように表現できるかについて、いくつかの可能なオプションを区別できます。
int data = 0; /* (1) */ extern int data; /* (2) */ int data; /* (3) */
(1)
初期化子が存在するため、間違いなく定義です(したがって、宣言でもあります)。
(2)
は単なる広告です。
(3)
(私たちの場合)は宣言であり、
は定義です。
extern
キーワードとイニシャライザが存在しないため、コンパイラはこのステートメントが何であるかに関する決定(「ステートメント」)を延期せざるを得なくなります。 自動登録をエミュレートするために使用されるのは、コンパイラのこの「発振」です。
念のため、状況を最終的に明確にするためのコメント付きの例をいくつか示します。
int data1; /* , . */ int data2 = 1; /* , - . */ int data2; /* , . */ int data3; /* , , * , . */ int data3 = 1; /* , - . */ /* static . */ static int data4; /* , , * , . */ static int data4 = 1; /* , - . */ static int data4; /* , . */ int data5; /* , . */ int data5; /* , "" . */ int data6 = 0; /* , - . */ int data6 = 0; /* , . */
次の2つのケースが重要です。
- 広告のみがあります。 この場合、変数はゼロに初期化され、対応する行にテストがないことを判断するために使用できます。
- 少なくとも1つの広告と1つの定義があります。 テストのある関数のアドレスは、対応する変数に入力されます。
実際、必要な操作を実装し、動作する自動登録を取得するために必要なのはそれだけです。 テキスト内の一部の演算子のこの二重性により、配列を要素ごとに拡張し、値を配列の一部に「割り当てる」ことができます。
機能と欠点
最後の行のマーカーとして機能する各テストファイルの最後にマクロを挿入したくない場合、最初に最大行数に配置する必要があることは明らかです。 最良の選択肢ではありませんが、最悪ではありません。 たとえば、1つのテストファイルに1,000行を超える可能性は低いため、この上限を選択できます。 非常に楽しい瞬間はありません。この場合、テストが1000を超える数の行で定義されている場合、それらは自重になり、呼び出されることはありません。 幸いなことに、単純な「解決策」オプションがあります。テストを
-Werror
フラグ(より厳密でないオプション:
-Werror=unused-function
)でコンパイルすれば十分であり、そのようなファイルはコンパイルされません。 ( UPD2: コメントでは、この問題を簡単に解決し、
STATIC_ASSERT
を使用してコンパイルを自動的に中断する方法を提案し
STATIC_ASSERT
。有効な
__LINE__
値のチェックを各
TEST
マクロに挿入するだけで十分です。)
一般に、固定配列アプローチの十分性が、事前に最大行数を修正することをお勧めする唯一の理由ではありません。 これが行われない場合、コンパイル中に対応する宣言(テストが呼び出された場所で)を生成する必要があり、これにより大幅に速度が低下する可能性があります(これは予測ではなく試行の結果です)。 ここでは物事を複雑にしない方が簡単です。任意のサイズのファイルをコンパイルできるという利点は価値がないようです。
上記の
TEST()
マクロを使用した例では、関数ポインターの使用を確認できます。これは1つのテストエントリにすぎませんが、多くの場合、さらに追加する必要があります。 これを行う間違った方法:並列疑似配列を追加します。 これにより、コンパイル時間が長くなります。 正しい方法:構造を使用するには、この場合、新しいフィールドの追加はほとんど無料です。
擬似配列の要素の実際の処理(コードのコピーではない)の場合、実際の配列を形成する必要があります。 同じ関数ポインタの値をこの配列に配置する(またはテストに関する情報を含む構造をコピーする)ことは、初期化子を一定にしないため、最良の解決策ではありません。 ただし、ポインターをポインターに配置すると、配列が静的になり、コンパイラーがコードを生成して実行時にスタックに値を割り当てる必要がなくなり、コンパイル時間が短縮されます。
最初に、このソリューションは
setup()
/
teardown()
関数の透過的な登録を実装するために生まれ、テスト自体にのみ適用されました。 原則として、これは再定義できる機能に適しています。 ポインター宣言を挿入し、マクロを再定義するマクロを提供するだけで十分です。マクロが使用されなかった場合、ポインターはゼロになります。それ以外の場合-ユーザー定義値。
テストの最上位レベルのエラーに関するコンパイラメッセージは、その量に驚かされるかもしれませんが、これは、セミコロンや後続の構文エラーが後続しないかなりまれなケースで発生します。
最後に、努力の結果を評価できます。
テストスイート:
| 後のテストスイート:
|
コレクションにテストスイートを登録する
トリックは1回使用できる巧妙なアイデアですが、テクニックは少なくとも2回使用できるトリックです。
-D.クヌース、 コンピュータープログラミング4Aの芸術
前のタスクに近いものですが、いくつかの重要な違いがあります。
- 興味深い文字(関数/データ)は異なるコンパイル単位で定義されます。
- そして、その結果、
__LINE__
似たカウンターはありません。
最初の段落のおかげで、前のセクションの純粋な形式のトリックはここでは機能しませんが、主なアイデアは変わりませんが、その実装方法はわずかに変わります。
冒頭で述べたように、このパートでは、環境の追加要件、つまりアセンブリシステムを提案します。これは、範囲
[0, N)
ファイル識別子を割り当てることができるはずです
[0, N)
はテストスイートの最大数を表します)。 繰り返しになりますが、境界線が一番上にありますが、たとえば、テストの各コレクションに100セットあれば、多くのテストに十分なはずです。
前回コンパイラーがすべての「汚い作業」を行った場合、今回はリンカー(別名「リンカー」)が動作する番でした。 各翻訳単位で、同じファイル識別子を使用してエントリポイントを決定し、テストコレクションのメインファイルで文字の存在を確認し、それらを呼び出す必要があります。
1つのオプションは、 「弱い文字」を使用することです。 この場合、関数は通常どおりほぼどこでも定義されていますが、メインファイルでは、
weak
属性(このようなもの:
__attribute__((weak))
)でマークされています。 明らかな欠点は、弱い文字がコンパイラーとリンカーによってサポートされる必要があることです。
弱い文字の構造について少し考えると、関数へのポインターとの類似性に気付くでしょう:未定義の弱い文字はゼロに等しいです。 これらはまったくなくても実行できることが
static
。以前のように関数へのポインタを定義するだけで十分ですが、
static
ません。 明示的な形式でポインタを使用すると、スタックフレームのリストに自動的に生成された名前がない場合にも、追加の利点がもたらされます。
この点で、テストスイートとの最初の違いは、既知のソリューションに還元されると考えることができます。 翻訳単位間の関係を決定することは残っています。 このタスクを完了するのに十分な情報がファイルにないため、外部からの情報が必要です。 ここでは、ビルドシステムごとに実装の詳細があります。GNU/ Makeの例を以下に示します。
順序自体の決定は十分に簡単です。テストコレクションを構成するすべてのファイルの並べ替えられたリスト内のファイル名の位置にしましょう。 テストなしで補助ファイルを心配する必要はありません。それらは最大で干渉せず、ナンバリングの省略を作成しますが、これは重要ではありません。 この情報は、コンパイラフラグ(この場合は
-D
)を使用してマクロ定義を通じて送信されます。
実際には、識別子定義関数は:
pos = $(strip $(eval T := ) \ $(eval i := 0) \ $(foreach elem, $1, \ $(if $(filter $2,$(elem)), \ $(eval i := $(words $T)), \ $(eval T := $T $(elem)))) \ $i)
最初の引数はすべてのファイル名のリストであり、2番目は現在のファイルの名前です。 インデックスを返します。 この関数は見た目がささいなものではありませんが、適切に機能します。
TESTID
追加(ここでは、
$(OBJ)
はオブジェクトファイルのリストを保存します):
%.o: %.c $(CC) -DTESTID=$(call pos, $(OBJ), $@) -c -o $@ $<
これにより、ほとんどすべての困難が克服され、残っているのは、たとえば次のようにコードで識別子を使用することだけです:
#define FIXTURE() \ static void fixture_body(void); \ void (*CAT(fixture_number_, TESTID))(void) = &fixture_body; \ static void fixture_body(void)
テストのコレクションのメインファイルには、対応するアナウンスとバイパスが必要です。
残りの困難
ファイルの数が設定された制限を超えて増加すると、テストで発生する可能性があるため、一部のファイルが視野から「抜け落ちる」可能性があります。 今回は、ソリューションでコンパイル時間の追加検証が必要になります。 コレクション内の既知の数のファイルを使用すると、それらが冗長であるかどうかを簡単に確認できます。 実際、もう1つのマクロを使用して、各放送ユニットにこの情報へのアクセスを提供するだけで十分です。
... -DMAXTESTID=$(words $(OBJ)) ...
あとは、次のようなものを使用して、十分な数の広告が存在するかどうかのチェックを追加するだけです。
#define STATIC_ASSERT(msg, cond) \ typedef int msg[(cond) ? 1 : -1]; \ /* Fake use to suppress "Unused local variable" warning. */ \ enum { CAT(msg, _use) = (size_t)(msg *)0 }
テストスイートのファイルを追加/削除する際に、関数の競合(二重定義)の問題がやや目立たなくなります。 このような変更はインデックスの変位を引き起こし、この影響を受けたすべてのファイルの再コンパイルが必要です。 ここでは、アセンブリシステムによるファイルの変更日を確認し、構成が変更されたときにカタログの日付を更新することを思い出してください。 実際、コンパイルされた各ファイルは、それが置かれているディレクトリに依存関係を追加する必要があります。
その結果、テストでファイルをコンパイルするためのルールは同様の形式を取ります。
%.o: %.c $(dir %.c)/. $(CC) -DTESTID=$(call pos, $(OBJ), $@) -DMAXTESTID=$(words $(OBJ)) -c -o $@ $<
すべてをまとめると、テストのコレクションの定義の次の変換を観察できます。
前のテストのコレクション:
| 後のテストのコレクション:
|
追加の最適化
定期的な再コンパイルの必要性と各ファイルの処理速度の低下により、これらのコストを補う方法が考えられます。 利用可能な機能のいくつかを思い出してください。
プリコンパイル済みヘッダー。 複雑なコードはコンパイラによって長時間処理されるため、処理結果を一度準備して再利用するのは論理的です。
ccacheを使用して再コンパイルを高速化します。 たとえば、それ自体が優れたアイデアであれば、リポジトリのブランチを何度でも切り替えることができ、完全な再コンパイルを待たずに済みます。合計時間は、主にキャッシュからデータをプルする速度によって決まります。
-pipeコンパイラフラグ (サポートされている場合)。 追加のRAMを使用するため、ファイル操作の数が減ります。
最適化をオフにして、デバッグ情報を除外します。通常の状況では、コンパイルプロセスの加速を除いて、これはテストの動作に影響を与えません。
なぜここにあるのですか?コンパイルのパフォーマンスが低下する可能性があることを上記で何度か言及しましたが、これに対処するための手段を提供し、いくつかのコメントで効果をいくらか滑らかにしたいと思います。
- パフォーマンスの低下は主にテストの完全な再アセンブリで顕著であり、通常の状況ではそれほど重大ではありません。
- , ( ) 6,5 . — 13 ., , 5,5 . 5,7 ., ( ) .
参照資料
seatest , , -. seatest stic ( C99, ), . , stic.h . . Makefile ( ).
まとめ
Wikipedia , stic - C (, ). ( UPD: C++, , , , ). , ( -
#ifdef
、サードパーティのスクリプトとは異なり)、追加のテストデータを収集するのは比較的簡単です。たとえば、フォームにテスト実行述語を追加するのは非常に簡単でした:
TEST(os_independent) { /* ... */ } TEST(unix_only, IF(not_windows)) { /* ... */ }
誰もが自分で決定できるようにしますが、著者は間違いなく、現在の座席が置き換えられた方法、プロセス、結果が好きでした。テストを追加するプロセスを簡素化し、テストの量を以前のサイズの約16%である3911行も削減しました。