研究プラットフォーム
実験の対象は、Intel Core i7-4700HQプロセッサを搭載したASUS N750JKラップトップです。 クロック周波数は2.4GHzで、Intel Turbo Boostモードで3.4GHzにブーストされます。 16ギガバイトのRAM DDR3-1600(PC3-12800)をインストールし、デュアルチャネルモードで動作します。 オペレーティングシステム-Microsoft Windows 8.1 64ビット。
図1調査対象のプラットフォームの構成。
検討中のプラットフォームのプロセッサには4つのコアが含まれており、ハイパースレッディングテクノロジが有効になっている場合、8つのスレッドまたは論理プロセッサのハードウェアサポートを提供します。 プラットフォームファームウェアは、この情報をMADT(Multiple APIC Description Table)ACPIテーブルを介してオペレーティングシステムに送信します。 プラットフォームにはRAMコントローラが1つしか含まれていないため、プロセッサコアのメモリコントローラへの近接を宣言するSRAT(システムリソースアフィニティテーブル)テーブルはありません。 明らかに、調査中のラップトップはNUMAプラットフォームではありませんが、統一のために、オペレーティングシステムは、NUMA行Nodes = 1で示されるように、1つのドメインを持つNUMAシステムと見なします。 4つのコアそれぞれのサイズが32キロバイト。 同じコアを共有する2つの論理プロセッサは、第1レベルと第2レベルのキャッシュメモリを共有します。
スタディ操作
データブロックの読み取り速度のサイズ依存性を調査します。 これを行うには、最も効率的な方法、つまりAVX命令VMOVAPDを使用して256ビットのオペランドを読み取る方法を選択します。 グラフのx軸はブロックサイズを示し、y軸は読み取り速度を示します。 最初のレベルのキャッシュのサイズに対応するXポイントの近くでは、処理されたブロックがキャッシュメモリを超えた後にパフォーマンスが低下するため、変曲点が表示されることが予想されます。 このテストでは、マルチスレッド処理の場合、16の開始されたスレッドのそれぞれが個別のアドレス範囲で動作します。 アプリケーション内のハイパースレッディングテクノロジーを制御するために、各スレッドはSetThreadAffinityMask API関数を使用します。この関数は、1つの論理ビットが各論理プロセッサーに対応するマスクを定義します。 単一のビット値は特定のスレッドによる特定のプロセッサの使用を許可し、ゼロ値はそれを禁止します。 調査中のプラットフォームの8つの論理プロセッサでは、マスク11111111bはすべてのプロセッサの使用を許可し(ハイパースレッディングが有効)、マスク01010101bは各コアで1つの論理プロセッサの使用を許可します(ハイパースレッディングは無効)。
次の略語がチャートで使用されています。
MBPS(メガバイト/秒) - メガバイト/秒単位のブロック読み取り速度 。
CPI(命令ごとのクロック) - 命令ごとのメジャーの数 。
TSC(タイムスタンプカウンター) - プロセッサークロックカウンター 。
注:TSCレジスタのクロック周波数は、ターボブーストモードで動作している場合、プロセッサのクロック速度と一致しない場合があります。 結果を解釈するとき、これを考慮に入れなければなりません。
グラフの右側では、各プログラムフローで実行されるターゲット操作のサイクルの本体を表す命令の16進ダンプ、またはこのコードの最初の128バイトが視覚化されています。
体験No.1 シングルスレッド
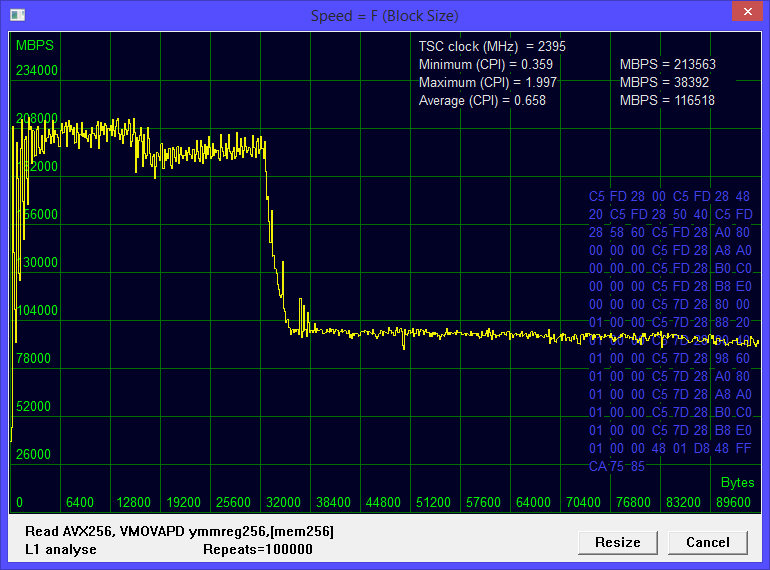
図2 1つのストリームによる読み取り
最大速度は213563メガバイト/秒です。 変曲点は、約32キロバイトのブロックサイズで発生します。
体験No.2 4つのプロセッサで16スレッド、ハイパースレッディングがオフになっています
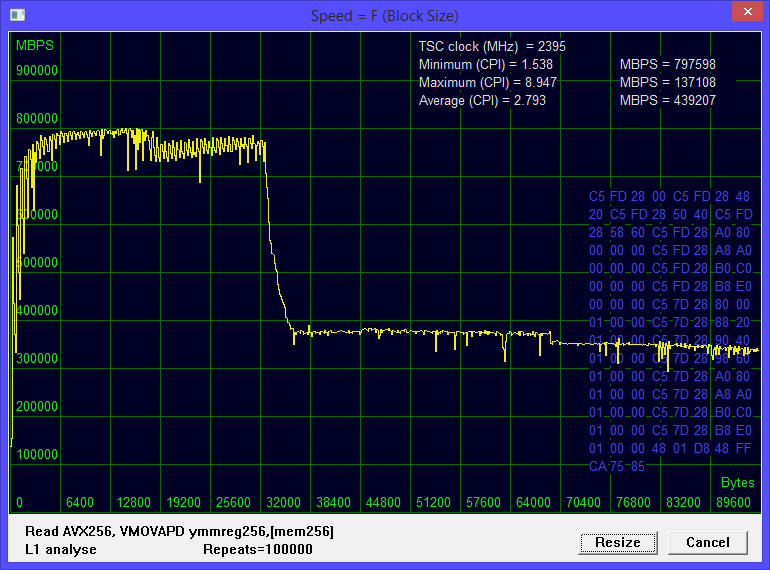
図3 16スレッドによる読み取り。 使用される論理プロセッサの数は4です
ハイパースレッディングはオフです。 最大速度は1秒あたり797598メガバイトです。 変曲点は、約32キロバイトのブロックサイズで発生します。 予想どおり、シングルスレッドの読み取りと比較して、動作中のコアの数で速度が約4倍に増加しました。
体験No.3 8プロセッサで16スレッド、ハイパースレッディング対応
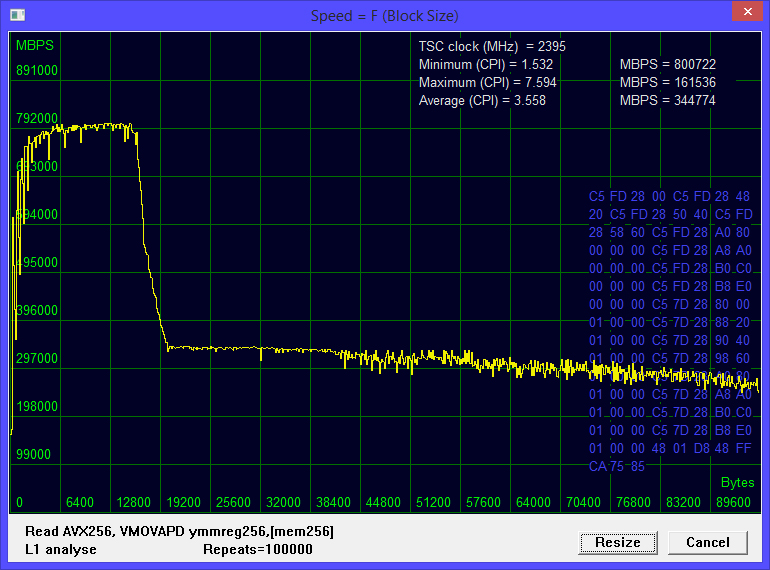
図4 16スレッドによる読み取り。 使用される論理プロセッサの数は8です
ハイパースレッディングが有効になっています。 ハイパースレッディングが組み込まれた結果、1秒あたり800,722メガバイトの最大速度はほとんど増加しませんでした。 大きなマイナス-変曲点は、約16キロバイトのブロックサイズで発生します。 ハイパースレッディングを有効にすると、最大速度がわずかに増加しましたが、ブロックサイズが半分の約16キロバイトになると速度が低下するため、平均速度が大幅に低下しました。 これは驚くことではありません。各コアには第1レベルの独自のキャッシュがあり、一方、1つのコアの論理プロセッサはそれを共有します。
結論
調査中の操作は、マルチコアプロセッサ上で非常にうまくスケーリングされます。 理由-各コアには第1レベルと第2レベルの独自のキャッシュが含まれ、ターゲットブロックのサイズはキャッシュのサイズに匹敵し、各スレッドは独自のアドレス範囲で動作します。 学術目的のために、合成テストでこのような条件を作成しました。実際のアプリケーションは通常、理想的な最適化にはほど遠いことを認識しています。 しかし、ハイパースレッディングを含めると、これらの条件下でもマイナスの効果があり、ピーク速度がわずかに増加し、サイズが16〜32キロバイトのブロックの処理速度が大幅に低下します。