当初、スキームがあったことを思い出してください。
この回路には、1つの論理要素*と、いくつかの定義された初期値(たとえば、x = -2、y = 3)があります。 論理要素は結果(-6)を計算し、結果を大きくするためにxとyを変更します。
行うことは次のとおりです。回路から取得した出力値を取得し、それを正の方向に引いたとします。 この正の張力は、ロジックエレメントを介して伝達され、xとyの初期値に力を及ぼします。 結果の値を増やすためにxとyをどのように変化させるかを指示する力。
そのような力は私たちの直接の例でどのように見えるのでしょうか? xのわずかな増加が回路の結果を改善するため、xに加えられる力も正であると仮定できます。 たとえば、 x = -2からx = -1に増加すると、-3になり、-6をはるかに超えます。 一方、負の力がyに現れると、それが減少します(たとえば、 y = 2は元のy = 3に比べてyの値が低いため、結果は高くなります: 2 x -2 = -4 、再び-6以上)。 いずれにせよ、この原則を覚えておく必要があります。 先に進むと、実際に説明した力は、元の値(xおよびy)に対する出力値の導関数になることがわかりました。 おそらくこの言葉を聞いたことがあるでしょう。
導関数は、結果の値を増やすときに、各初期値に作用する力と考えることができます
この力(デリバティブ)をどうすれば本当に感謝できるでしょうか? これにはかなり簡単な手順があることがわかります。 逆方向に作業します。回路の結果を引き伸ばす代わりに、各初期値を順番に変更し、少し増やして、結果に何が起こるかを確認します。 出力値の変化の数は導関数です。 しかし、今のところ、十分な理論。 数学的な定義を見てみましょう。 元の値に関する関数の導関数を書くことができます。 たとえば、xに関する導関数は次のように計算できます。
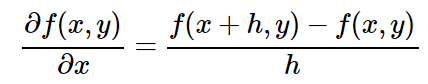
ここで、hは小さな変化値です。 さらに、この計算方法に特に精通していない場合は、上記の式の左側にある水平線は除算を意味しないことに注意してください。 文字全体(∂f(x、y))/∂xは単一の要素です:xに対する関数f(x、y)の導関数。 右側の水平線は区分です。 これは複雑ですが、標準的な表記法です。 いずれにせよ、これがあまりにも恐ろしく見えないことを願っています。
回路は特定の初期結果f(x、y)を生成し、その後、初期値の1つを小さな数hに変更し、新しい結果f(x + h、y)を取得しました。 これらの2つの値を減算すると、変化がわかります。hで割ると、変化は、使用する変化の(任意の)値になります。 言い換えれば、これは上で説明したものを正確に表現し、次のようなコードに変換します。
forwardMultiplyGate(x、y)関数が引数の積を返すことを思い出してください
var x = -2, y = 3; var out = forwardMultiplyGate(x, y); // -6 var h = 0.0001; // x var xph = x + h; // -1.9999 var out2 = forwardMultiplyGate(xph, y); // -5.9997 var x_derivative = (out2 - out) / h; // 3.0 // y var yph = y + h; // 3.0001 var out3 = forwardMultiplyGate(x, yph); // -6.0002 var y_derivative = (out3 - out) / h; // -2.0
xの例を見ていきましょう。 xをx + hに変更すると、回路はより高い値で応答しました(再び、-5.9997> -6に注意してください)。 h(除算式)による除算は、回路の結果をhの(任意の)値にするために実行され、この場合に使用することにしました。 技術的には、hの値は無限である必要があります(勾配の正確な数学的定義は、hがゼロになる傾向がある場合の式の限界として表されます)が、実際には、適切な近似値を取得する必要があるほとんどの場合にh = 0.00001または同様の値が最適です。 ここで、xに関する導関数が+3であることがわかります。 回路がxをより高い値に引くことを示すため、プラス記号を具体的に示しました。 3という実際の値は、このような張力の力として解釈できます。
任意の初期値に対する導関数は、この初期値を小さな数値に調整し、出力値の変化を観察することで計算できます。
ところで、私たちは通常、1つの初期値に関する微分、またはそのようなすべての値に関する勾配について話します。 勾配は、ベクトル(つまりリスト)で接続されたすべての元の値の導関数で構成されます。 最も重要なことは、勾配に続く小さな値で初期値が張力に反応することを許可する場合(つまり、各初期値の上部にのみ微分を追加する場合)、予想どおり増加することがわかります:
var step_size = 0.01; var out = forwardMultiplyGate(x, y); // : -6 x = x + step_size * x_derivative; // x -1.97 y = y + step_size * y_derivative; // y 2.98 var out_new = forwardMultiplyGate(x, y); // -5.87!
予想どおり、初期値を勾配に変更し、回路はより高い値(-5.87> -6.0)を生成するようになりました。 xとyを任意に変更しようとするよりもずっと簡単でしたね。 実際、計算を実行すると、勾配が実際に関数の急激な増加の方向であることを証明できます。 戦略1で行ったように、タンバリンと踊り、任意の値を代用しようとする必要はありません。 勾配を推定するには、数百ではなく3つの回路パスの推定のみが必要であり、出力値を増やすことに関心がある場合に(ローカルに)期待できる最適なプッシュを取得します。
多いほど良いとは限りません。 少し明確にしましょう。 この最も単純な例では、0.01より大きいステップサイズ(step_size)を使用すると常に最良の結果が得られることに注意してください。 たとえば、step_size = 1.0は-1(より大きく、より良い!)になります。そして、本当に無限のステップサイズは無限に良い結果を与えることができます。 回路が非常に複雑になると(ニューラルネットワーク全体など)、初期値から出力値までの関数はより混chaとし、「カーリー」になることを理解することが重要です。 勾配により、非常に小さい(実際には無限の)ステップサイズがある場合、その方向に従うと間違いなく大きな数値が得られます。そのような無限の小さなステップサイズでは、同様に機能する他の方向はありません。 しかし、より大きなステップ(たとえば、step_size = 0.01)を使用すると、すべてが意味を失います。 無限の小さなステップではなく、より大きなステップを使用できるのは、通常、関数が比較的均一であるためです。 しかし、実際には、私たちは指を交差させ、最善を願っています。
登山の例え。 かつて、私たちの回路の出力値は丘の頂上に似ているというアナロジーを聞いたことがあり、目隠しして登ろうとしています。 私たちは足の下の丘の斜面の急勾配を感じます(勾配)ので、足を少し動かせば、登ります。 しかし、大きくて自信に満ちた一歩を踏み出せば、私たちはピットに落ちることができます。
数値勾配は、評価するのに非常に便利であり、非常に単純でもあることを確信していただければ幸いです。 しかし。 さらに多くのことができることがわかりました。これについては、次のパートで説明します。