おそらく既にご想像のとおり、GCC 5.0ではグループメモリアクセスのベクトル化が大幅に改善されました。 グループメモリアクセスは、反復可能な呼び出しシーケンスを指します。 例:
x = a[i], y = a[i + 1], z = a[i + 2]
iで反復できるのは、長さ3のメモリダウンロードのグループです。メモリアクセスのグループの長さは、グループ内の最低アドレスと最高アドレスの間の距離です。 上記の例では- (i + 2)-(i)+ 1 = 3
グループ内のメモリアクセス数は、その長さを超えません。 例:
x = a[i], z = a[i + 2]
i上で反復可能なのは、メモリアクセスが2つしかないという事実にもかかわらず、長さ3のグループです。
GCC 4.9は、長さが2(2、4、8 ...)のグループをベクトル化します。
GCC 5.0は、長さが3または次数2(2、4、8 ...)のグループをベクトル化します。 他の長さは、実際のアプリケーションでは非常にまれなので、ベクトル化されません。
ほとんどの場合、構造体の配列を操作するときは、メモリアクセスのグループのベクトル化が使用されます。
1.たとえば、RGB構造での画像変換。 例 。
2. N次元の座標を操作します(3次元の点を正規化するなど)。 例 。
3.定数行列によるベクトルの乗算:
a[i][0] = 7 * b[i][0] - 3 * b[i][1]; a[i][1] = 2 * b[i][0] + b[i][1];
GCC 5.0全体(4.9と比較)
- 長さ3のメモリアクセスのグループのベクトル化がありました。
- 任意の長さのメモリダウンロードグループのベクトル化を大幅に改善
- 特定のx86プロセッサに最適なメモリアクセスグループをベクトル化する手法が使用されるようになりました。
次の表は、GCC 4.9と比較してバイト構造(ベクトル内の要素の最大数)でGCC 5.0を使用した場合のパフォーマンスの向上の推定値を示しています。 評価には次のサイクルが使用されます。
int i, j, k; byte *in = a, *out = b; for (i = 0; i < 1024; i++) { for (k = 0; k < STGSIZE; k++) { byte s = 0; for (j = 0; j < LDGSIZE; j++) s += in[j] * c[j][k]; out[k] = s; } in += LDGSIZE; out += STGSIZE; }
どこで:
- cは定数行列です。
const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1};
このようなマトリックスは、ループ内の計算を最小限に抑えて、比較的速い加算と減算を行うために使用されます。
- inおよびoutは、グローバル配列「a [1024 * LDGSIZE]」および「b [1024 * STGSIZE]」へのポインタです。
- バイトは符号なし文字です
- LDGSIZEおよびSTGSIZEは、それぞれメモリダウンロードのグループの長さを決定し、メモリに保存するマクロです。
コンパイルオプション「-Ofast」とSilvermontの 「-march = slm」、 Haswellの 「-march = core-avx2」およびすべての組み合わせ-DLDGSIZE = {1,2,3,4,8} -DSTGSIZE = {1,2 、3,4、8}
4.9と比較したGCC 5.0のパフォーマンスの向上(何倍も高速であるほど、優れている)。
Silvermont :Intel Atom(TM)CPU C2750 @ 2.41GHz
最大6.5倍の成長!
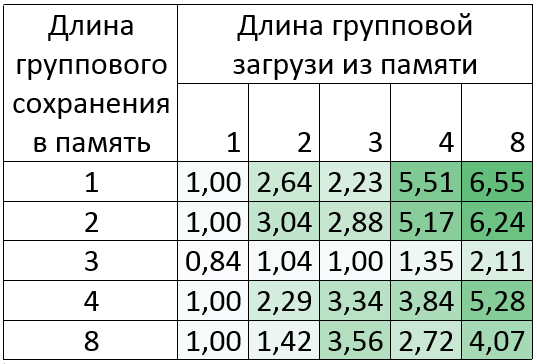
表からわかるように、長さ3のメモリグループの結果はあまり良くありません。 これは、そのような変換には8つの「pshufb」命令が必要であり、Silvermontでの実行時間は約5クロックサイクルであるためです。 それにもかかわらず、ループ内の他のチームのベクトル化により、大幅に増加する可能性があります。 これは、長さ2、3、4、および8のメモリダウンロードのグループの例で見ることができます。
長さ2のメモリロードグループのGCCアセンブラの例:
| GCC 4.9 | GCC 5.0 |
| movdqa .LC0(%rip)、%xmm7
movdqa .LC1(%rip)、%xmm6 movdqa .LC2(%rip)、%xmm5 movdqa .LC3(%rip)、%xmm4 movdqu a(%rax、%rax)、%xmm1 movdqu a + 16(%rax、%rax)、%xmm0 movdqa%xmm1、%xmm3 pshufb%xmm7、%xmm3 movdqa%xmm0、%xmm2 pshufb%xmm5、%xmm1 pshufb%xmm6、%xmm2 pshufb%xmm4、%xmm0 por%xmm2、%xmm3 por%xmm0、%xmm2 | movdqa .LC0(%rip)、%xmm3
movdqu a(%rax、%rax)、%xmm0 movdqu a + 16(%rax、%rax)、%xmm1 movdqa%xmm3、%xmm4 pand%xmm0、%xmm3 psrlw $ 8、%xmm0 pand%xmm1、%xmm4 psrlw $ 8、%xmm1 packuswb%xmm4、%xmm3 packuswb%xmm1、%xmm0 |
Haswell :Intel Core(TM)i7-4770K CPU @ 3.50GHz
最大3倍の成長!

この場合、長さ3のメモリグループの結果は、 Haswellでは命令「pshufb」が1クロックサイクルで実行されるため、はるかに優れています。 さらに、ここでの最大の増加は、長さ3のメモリアクセスグループの実装されたベクトル化のためです。
長さ2のメモリロードグループのGCCアセンブラの例:
| GCC 4.9 | GCC 5.0 |
| vmovdqa .LC0(%rip)、%ymm7
vmovdqa .LC1(%rip)、%ymm6 vmovdqa .LC2(%rip)、%ymm5 vmovdqa .LC3(%rip)、%ymm4 vmovdqu a(%rax、%rax)、%ymm0 vmovdqu a + 32(%rax、%rax)、%ymm2 vpshufb%ymm7、%ymm0、%ymm1 vpshufb%ymm5、%ymm0、%ymm0 vpshufb%ymm6、%ymm2、%ymm3 vpshufb%ymm4、%ymm2、%ymm2 vpor%ymm3、%ymm1、%ymm1 vpor%ymm2、%ymm0、%ymm0 vpermq $ 216、%ymm1、%ymm1 vpermq $ 216、%ymm0、%ymm0 | vmovdqa .LC0(%rip)、%ymm3
vmovdqu a(%rax、%rax)、%ymm0 vmovdqu a + 32(%rax、%rax)、%ymm2 vpand%ymm0、%ymm3、%ymm1 vpsrlw $ 8、%ymm0、%ymm0 vpand%ymm2、%ymm3、%ymm4 vpsrlw $ 8、%ymm2、%ymm2 vpackuswb%ymm4、%ymm1、%ymm1 vpermq $ 216、%ymm1、%ymm1 vpackuswb%ymm2、%ymm0、%ymm0 vpermq $ 216、%ymm0、%ymm0 |
測定に使用されるコンパイラ:
英語の記事の元のテキストから測定値が取得された例をダウンロードできます。