はじめに
コード構造、プロジェクト構造、プロジェクト設計、プロジェクトアーキテクチャ-これらの概念は、建築家、開発者、プロジェクトマネージャー、またはコンサルタントにとって異なる意味、複雑さ、または深さを持つことができます。 次に用語を掘り下げていく必要がありますが、この記事のフレームワークでは、これらすべての概念がほぼ同じこと、つまりパターンのセット、コードの書き方を示すルール、正しく応答するルールを表現すると仮定します入ってくる要件。 たとえば、DAO(データアクセスオブジェクト)を使用してデータベースにアクセスする場合、データベースに新しい構造を作成するとともに、新しいDAOを作成するか、既存のDAOを拡張する必要がありますが、プレゼンテーションレベルではSQLを記述しません。
さらに明確にするために、M。Fowlerによる「エンタープライズアプリケーションアーキテクチャのパターン」について書かれた「クラシック」とほぼ同じものになることを付け加えます。 この本は、機能を共有する方法、つまり どのメソッドがどのクラスに属している必要があります。
問題
例から始めましょう。 私たちの仕事は、オス国へのビザの申請を処理するシステムを書くことです。 システムは、連絡先データと職場に関するデータで構成されるリクエストの作成を許可する必要があります。 ビザセンターに処理のリクエストを送信します。 ビザの発行または拒否を決定する。 文書を提出した人に関するレポートを生成します。 空飛ぶサルにパスポートを渡します。 さらに、複数の人に対してリクエストを行うことができます。
簡略化された形式では、クエリ構造は次のようになります。
class VisaRequest{ Collection<Applicant> applicants } class Applicant{ Contact contact WokrInfo workInfo } …
プログラミング言語はマジックである(つまり、マジックなしでコンパイルされない)ことを忘れないでください。ただし、groovyに似ています。
この場合の機能自体は次のようになります。
class VisaRequestService { def create(def visaRequest){...} def update(def visaRequest){...} def get(def requestId){} def submit(def requestId){...} def getDecision(def requestId, def applicantName){...} def generateReport(def requestId, def applicantName){...} }
サービスのレベルとデータモデルを反映したこのようなシステムのクラス図を以下に示します。

マーティン・ファウラーはこれについて何を書いていますか? 私は本を語り直しません、私は他のすべてと一緒に、VisaRequestServiceのようなクラスが成長するという事実に注意を引くだけで、各メソッドは実際にはスクリプトであるため、書かれたメソッドを再利用することがますます難しくなると言います特定のシナリオに固有。 私たちは彼と議論するつもりはありませんが、記事のタイトルから概念に注目します-結束。 凝集度はオブジェクト/クラスのプロパティであり、オブジェクト/クラスがどれほど忙しいかを決定します。 凝集度が低い場合、クラスの責任が大きすぎ、クラスの操作が多すぎて大きくなり、大きなクラスは読みにくく、拡張しにくいなどです。
些細なケースでは、実際にすべてを管理する神クラスを作成しました。 もちろん、これが唯一のソリューションではなく、個別のDecisionServiceを作成できます。
class DecisionService{ def getDecision(def requestId, def applicantName){...} }
または個別のSubmitService:
class SubmitService{ def submit(def requestId){...} }
または個別のApplicantService:
class ApplicantService{ def getDecision(def requestId, def applicantName){...} def generateReport(def requestId, def applicantName){...} }
または何か他のもの(結局、Osの国)。
これらすべての例で、新しいクラスの凝集度はかなり良いように見えますが、既存のクラスの凝集度を改善しているわけではありません。 最初の2つのケースで、これらのクラスの1つだけを作成するように制限した場合、VisaRequestServiceは引き続き多くの処理を行います。 さらに、このようにクラスを壊した理由は不明のままです。
解決策
クラシック
Fowlerはこの問題をPLOの肩に完全に転送することで解決します。 彼は、リッチデータモデルの概念を紹介します。これは、OOPの基礎の1つである1つのクラスのデータとメソッドの正直な組み合わせにすぎません。 システムのリッチデータモデルは次のようになります。
class VisaRequest{ Collection<Applicant> applicants def create(){...} def update(){...} def get(){} def submit(){...} } class Applicant{ Contact contact WokrInfo workInfo def getDecision(){...} def generateReport(){...} def create(){...} def update(){...} def get(){} }
機能は非常に単純なルールに従って分類されます。クラスには、このクラスが反映するエンティティに関連するメソッドのみが含まれます。 もちろん、この定義は厳密ではありません。実際、結束そのものの定義です。
リッチデータモデルは、たとえば複雑な計算の場合など、多くのシステムにとって便利ですが、エンティティに対する操作が少なく、外部環境との弱い相互作用がありますが、常にそうとは限りません。 これにはいくつかの理由がありますが、おそらく最も重要なのは2つです。
それらの最初は、そのようなステートフルモデルです。つまり、オブジェクトには何らかの状態があります。 データ構造のみに状態がある限り、これには問題はありませんでしたが、現在ではシステムの機能を保持するオブジェクトにも状態があります。 実際には、これはそのようなオブジェクトを作成するプロセスを複雑にします。 実際、これにより、springなどの一般的なDI(Dependency Injection)コンテナを使用することは非常に問題になります。 さらに、J2EEまたはWEBについて話す場合、ファサードの作成(春のアクション)の必要性をキャンセルした人はいません。これは、構造化の方法が不明な新しい機能層をもたらします。
2番目の理由は、大規模システムでは1つのエンティティに適用できる多くの操作を実際に行うことができるため、大規模なクラスが発生する可能性があり、設計全体を複雑にする新しいパーティション分割手法を考え出す必要があるためです。
クラシックではない
すべて同じサービスを使用して、わずかに異なる方法で問題を解決してみましょう。 なぜ彼らなのか? サービスがプログラマーの間で非常に人気があるためだけの場合。 上記の鋭い角や障害物を避けて、それらを正しく使用する方法が問題になります。 私の意見では、最も便利な方法は2つの座標に分割することです-データの構造(要素)と機能、サービスの名前に反映される必要があります。
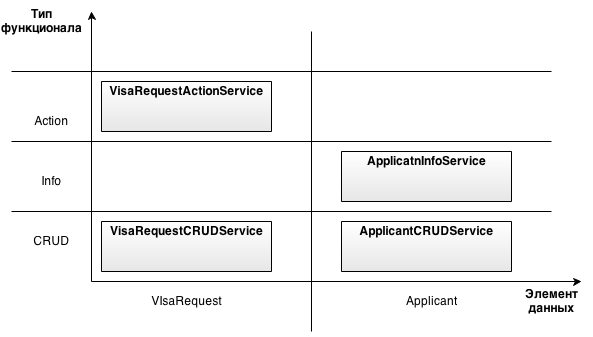
このルールに従って、システムに対して次のサービスを受け取ります。
class VisaRequestCRUDService { def create(def visaRequest){...} def update(def visaRequest){...} def get(def requestId){...} def getDecision(def requestId, def applicantName){...} } class VisaRequestActionService { def submit(def requestId){...} } class ApplicantCRUDService{ def create(def Applicant){...} def update(def Applicant){...} def get(def applicantId){...} def create(def Applicant){...} } class ApplicantInfoService{ def getDecision(def requestId, def applicantName){...} def generateReport(def requestId, def applicantName){...} }
クラス図は次のようになります。
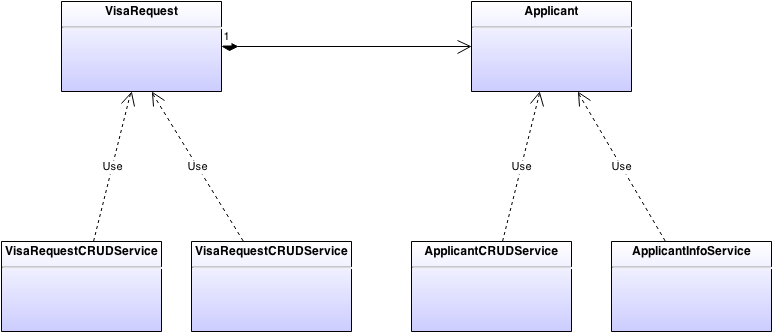
このアプローチの利点は非常に明白です。 まず、Rich Data Modelを使用する場合、1つのクラスの代わりに2つのクラスを使用するというほぼすべての利点があります。これにより、接続性が低下します。 第二に、システムの汚染を最小限に抑える凝集力のさらなる改善のメカニズム(ルール)を明示的に示します。
完全に明らかではない別のプラスがあります。 データモデルは常にドメインモデルと一致するとは限りませんが、操作は常にドメインモデルに属します。 上記のソリューションを使用すると、2つのモデルの違いを機能の座標に反映できます。 たとえば、空飛ぶ猿について思い出しましょう。 要件に基づいて、それらには特性がありません。つまり、それらに関する情報を保存する必要はなく、したがって、データモデルでは何もしません。 一方、これらはドメインモデルにあり、VisaRequestクラスに応じてサービスに反映できます。
class FlyApesRequestDeliveryService{ def deliver(def Request){...} }
もちろん、説明したアプローチには欠点があります。 関数の座標に沿って分割するのと同じ柔軟性により、この分割の非自明性が生じます。 開発者は、この設計を正しく使用するために、システムのタイプと実行される一連の操作(少なくともビジネス要件のレベルで)について明確なアイデアを持っている必要があります。
結論の代わりに
結束があれば、すべてが多かれ少なかれ明確になると思いますが、企業はどうでしょうか? 原則として、いくつかのチームがそれらに取り組んでおり、おそらく地理的に分割されているため、企業アプリケーションは興味深いものです。 多くのチーム-多くの人々、多くの人々-多くの質問。 新しい機能をどこでどのように実装しますか? システムに同様のものがありますか? 新しい開発者-新しいアプローチ。
これはすべて多くの問題を引き起こしますが、技術的な観点から最も難しいのはダーティコードです(クラスの構造の悪さはダーティコードの最も明るい例の1つです)。 多くの場合、ダーティコードを含むシステムは、修正するよりも書き直す方が簡単です。 誰もが私に同意するとは限りませんが、凝集はシステムの健全性の主要な指標の1つであると言えます。
おそらくこれで終了するはずです。 この記事が誰かに役立つことを願っていますが、上記の問題があなたに馴染みのないものであれば、進化論的デザインが何であるかを知っており、チームで機能します。ここに書かれていることはすべて忘れてください、あなたはすでにOsの国にいます。